1. 论文相关
NeurIPS 2018

2.摘要
2.1 摘要
在这篇文章中,我们提出了一个概念简单且通用的框架,称为MetaGAN,用于解决小样本学习问题。大多数最先进的小样本分类模型可以以一种原则和直接的(principled and straightforward)方式与MetaGAN集成。通过引入一个以任务为条件的对抗生成器(adversarial generator),我们对传统的小样本分类模型进行了改进,使其能够区分真实数据和虚假数据。我们认为这种基于GAN的方法可以帮助小样本分类器学习更清晰的决策边界,从而更好地推广。我们证明,利用我们的MetaGAN框架,我们可以扩展有监督的小样本学习模型,以自然地处理未标记的数据。与以往的半监督小样本学习不同,我们的算法可以同时处理样本级和任务级的(sample-level and task-level)半监督问题。我们给出了MetaGAN强度的理论证明(theoretical justifications),并验证了MetaGAN在挑战小样本图像分类基准方面的有效性。
2.2 主要贡献
(1)MetaGAN算法能够从有标签和无标签的例子中学习推断特定于任务的数据分布的数据流形的形状和边界。
(2) 我们对MetaGAN背后的关键思想提供了直观和形式的理论依据。小样本学习的主要困难是如何从少量训练样本中形成可概括的决策边界。我们认为,对抗性训练可以帮助小样本学习模式,使学习更容易在不同类别之间更好的决策界限。虽然训练数据通常对每个任务都是非常有限的,但是我们展示了由MetaGAN中的非完美生成器生成的假数据如何帮助分类器识别更紧密的决策边界(真实的假决策边界),从而有助于提高小样本学习的性能。
(3)在有监督和半有监督的情况下,我们证明了MetaGAN在流行的小样本图像分类基准上的有效性。我们选择了两个具有代表性的小样本学习模型,MAML【Finn等人,2017年】代表学习使用梯度适应的模型,Relation Network【Sung等人,2018年】代表学习距离度量的模型,并将它们与MetaGAN相结合。[1]我们表明,在所有这些场景中,MetaGAN都可以持续地提高流行的小样本分类器的性能。
2.3 相关工作
3.我们的方法
MetaGAN是一个概念上简单和通用的框架,用于解决小样本学习问题。与[Salimans等人,2016]类似,我们给出了一个像样的K-shot N-way分类器,我们引入了一个条件生成模型(conditional generative model),其目标是生成与从特定任务中采样的真实数据不可区分的样本。我们将分类器输出的维数从N增加到N+1,以建模输入数据是假的的概率。我们在对抗的设置下训练判别器(分类器)和生成器。
MetaGAN背后的关键思想是,GAN模型中的不完美生成器可以在不同真实数据类的流形之间提供假数据,从而为分类器提供额外的训练信号,并使决策边界更加清晰(sharper)。我们首先在第3.1节中正式描述了我们的基本模型,然后在下面的章节中详细介绍了MetaGAN的不同实例。
3.1 基本算法(BASIC ALGORITHM)
我们首先介绍了MetaGAN的基本公式。对于few-shot N-way分类问题和数据集,假设我们有一个最先进的小样本分类器:。请注意,是以特定任务为条件的。实际上,这种调节可以通过快速适应【Finn等人,2017年】或将支持集作为输入【Snell等人,2017年,Mishra等人,2018年,Sung等人,2018年】。我们使用额外的输出来增强分类器,就像在GAN的半监督学习中所做的那样:。我们还训练了一个任务条件生成器和生成分布,它试图为特定任务生成数据。然后,对于任务的训练集(training episode),我们最大化了N-way分类器的目标和判别器的真实/假分类目标的组合:
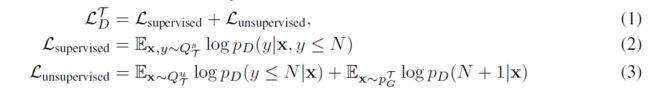
对于生成器,我们将非饱和生成器损失最小化(non-saturating generator loss):
那么训练MetaGAN的总体目标是:
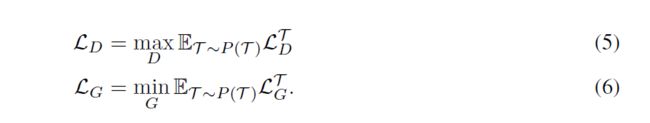
3.2 判别器(DISCRIMINATOR)
MetaGAN一般不限制判别器的设计。它几乎可以改编自任何最先进的小样本学习器。我们采用了两种流行的小样本分类模型作为我们的判别器(discriminator),MAML[Finn等人,2017]和Relational Networks[Sung等人,2018],分别代表学习快速微调模型和学习共享嵌入和基于度量的模型。
3.2.1 带MAML的MetaGAN(METAGAN WITH MAML)
MAML训练一个可迁移的初始化,它能够用一步梯度下降(one step gradient descent)快速适应任何特定的任务。形式上,判别器由参数进行参数化。对于一个特定的任务,我们根据损失公式7将参数更新为。
然后,我们使用跨任务的自适应判别器最小化查询集的期望损失,去训练判别器的初始参数,并使用自适应判别器训练生成器。最后,我们结合MetaGAN 和MAML的整个模型可以使用等式5和等式6中引入的损失进行训练,如下所示:
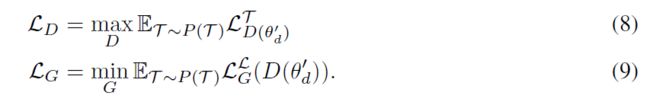
在补充材料中,我们提出了使用MAML模型训练MetaGAN的详细算法。
3.2.2 使用关系网络的MetaGAN(METAGAN WITH RELATION NETWORK)
关系网络(Relation Network,RN))是一种通过学习图像间的距离度量进行分类的小样本学习模型。MetaGAN可以以一种原则和直接的方式与RN集成。
对于特定任务,和[Sung等人,2018 ]一样,让是查询集图像与支持集图像之间的相关得分,是关系模块,是特征嵌入网络,C是级联算子(concatenation operator)。与[Sung等人,2018]不同,我们不限制在0到1的范围内,而是将用作Softmax分类中使用的logits里,
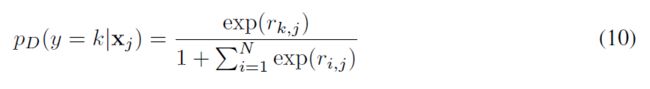
我们采用[Salimans等人,2016]中提出的简单技巧,将伪类的logit设置为0(与分母(denominator)中出现的常数1相对应),将其设置为模型,该模型是输入数据是假的概率。因此,我们可以直接使用损失公式5和公式6来训练我们的带有关系网络的MetaGAN模型。
3.3 生成器(GENERATOR)
我们使用条件生成模型在一个特定的任务中生成接近真实数据流形的假数据。为此,我们首先使用一个数据集编码器将任务的支持数据集中的信息压缩成向量,向量包含了任务的数据分布的足够统计信息。然后与随机噪声输入串联(concatenated),作为生成器网络的输入。受[Edwards and Storkey,2017]提出的统计网络(statistic network)启发,我们的数据集编码器由两个模块组成:
实例编码器模块(Instance-Encoder Module)
实例编码器(Instance-Encoder)是一个神经网络,它学习数据集中每个单独数据示例的特征表示。它将每个数据实例映射到特征空间。
特征聚合模块(Feature-Aggregation Module)
特征聚合模块以每个嵌入的特征向量为输入,生成整个任务训练集的表示向量。可行的聚合方法(Feasible aggregation methods)包括平均池化、最大池化和其他元素级聚合运算符(element-wise aggregation operators)。在我们的MetaGAN模型中,我们使用了遵循[Edwards和Storkey,2017]的平均池化。
通过集成实例编码器模块和特征聚合模块,鼓励实例编码器学习表示,使得在学习的特征空间中平均不同的样本是有意义的。此外,特征聚合使生成器更难简单地重建其输入,这可能导致模式下降[Che等人,2017]。
3.4 学习设置(LEARNING SETTINGS)
在这一部分中,我们证明了有监督的小样本学习和半监督的小样本学习都可以统一在MetaGAN框架中。
3.4.1 有监督的小样本学习(Supervised Few-Shot Learning)
监督学习是few shot分类模型中最常见的学习设置。对于任务,由于不带标签的数据集和不可用,我们使用带标签数据集和并在损失公式1和公式7中分别替换它们。
3.4.2 样本级半监督小样本学习(Sample-Level Semi-Supervised Few-Shot Learning)
样本级半监督学习遵循与[Ren等人,2018]相同的设置,其中每个任务中都有未标记的数据示例。虽然我们的模型有足够的灵活性来处理支持集和查询集中的不同的未标记实例集,但是对于任务,我们只使用一个未标记的示例集合来遵循[Run等,2018 ]中的相同的训练方案,以便更好地与我们的基线模型进行比较。
具体来说,对于带有MAML的MetaGAN,我们设置和。对于具有RN的MetaGAN,我们在损失公式1和公式7中设置和。
3.4.3 任务级半监督小样本学习(Task-Level Semi-Supervised Few-Shot Learning)
用于任务级半监督学习,训练集由标记任务和未标记任务组成。对于标记的任务,我们只需遵循上面描述的监督学习设置。对于未标记的任务,我们通过设置损失公式1和公式7中的和,忽略监督损失项(supervised loss term)。
正如[Salimans等人,2016]所建议的,我们采用“特征匹配损失”(feature matching loss)作为样本级和任务级半监督小样本学习的生成器损失。
4. 为什么MetaGAN有效?(WHY DOES METAGAN WORK?)
在这一节中,我们将介绍MetaGAN的直觉和理论依据,这将促使我们对模型进行各种改进。
在小样本分类问题中,该模型试图在每个类中只有几个样本的情况下为每个任务优化决策边界。显然,如果不能从其他任务中学习到任何信息,这个问题是不可能的,因为有太多的可能的决策边界来将少数几个样本分开,而且大多数样本都不会泛化。元学习试图在不同的任务间学习一种共享策略,从少量的样本中形成决策边界,希望这种策略能够推广到新的任务。
虽然这是合理的,但也可能存在一些问题。例如,某些对象看起来比其他对象更相似。在猫和车之间形成决策边界可能比猫和狗之间容易。如果训练数据不包含试图将猫和狗分开的任务,则很难提取正确的特征来将这两类对象分开。然而,另一方面,在训练过程中对各种类别组合的期望导致了组合爆炸问题。
这就是我们提出的MetaGAN公式的作用。就像使用GAN进行半监督学习一样,我们不希望生成器生成完全在真实数据流形上的数据。相反,更好的是,生成器能够从每个类的数据流形中稍微生成数据,参见图1。这迫使我们的判别器学习更清晰的决策边界。MetaGAN的判别器不仅要学会区分猫和狗,还必须学会什么是真正的猫或狗,以及什么是从猫和狗有点不同的地方产生的假数据。因此,判别器必须提取足够强的特征来确定实际数据流形的边界,这有助于将不同的类分开。此外,真/假类之间的分离与在小样本学习过程中选择的类组合无关。
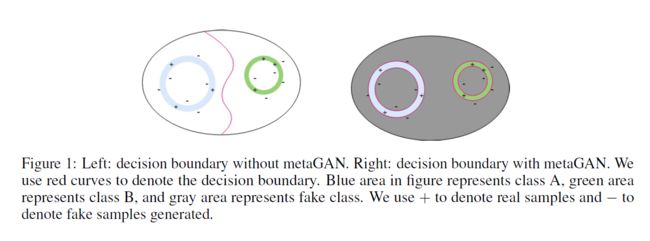
根据在半监督学习环境中研究的理论证明背后的思想,我们在小样本学习问题中提供了类似的证明。我们在补充材料中包括了假设的正式陈述。
首先,如[Dai等人,2017]所述,对于特定任务,我们假设分类器依赖于特征提取器来执行分类。我们还假设是每个任务的“分离补体生成器(separating complement generator)”(我们在补充材料中定义)。直观地说,这意味着生成器满足两个条件:1)生成器分布具有与所有类的数据流形不相交的高密度区域(high density region);2)的高密度区域可以分离不同类的流形。
然后,通过以下与[Dai等人,2017]中类似的论点,我们可以证明:
定理1:设表示从采样的每个任务中的独立补码生成器(separating complement generator)。表示支持集,表示生成的伪数据集。我们假设我们学习的元学习器能够学习一个分类器,它可以在增广支持集上得到一个强的正确决策边界。那么如果然后,几乎可以肯定地从任务的数据分布中正确分类所有真实样本。

这个定理是说,如果我们有一个既不太好也不太坏的生成器,但是它可以围绕实类流形生成数据,并且有一个高密度区域,可以帮助将不同的类分开,那么生成的数据和一些真实数据可以帮助我们确定正确的决策边界。
5 实验(EXPERIMENTS)
5.1 数据集
omniglot是一个由50种语言的手写字符图像组成的数据集。共有1623类字符,每个类中有20个示例。根据之前的训练和【Vinyals等人,2016年】中使用的评估方案,我们将所有图像缩小到28×28,并将数据集随机分成1200个训练类和432个测试类。利用[Santoro等人,2016]提出的相同数据增强技术,将每个图像随机旋转90度,形成新的类。
mini-imagenet是ilsvrc-12数据集的一个改进子集,由100个类的84×84幅彩色图像组成,每个类有600个随机样本。我们采用与[Ravi和Larochelle,2017]相同的班级划分,共64个训练类、16个验证类和20个测试类。
5.2 有监督的小样本学习(SUPERVISED FEW-SHOT LEARNING)
在Omniglot数据集上,MetaGAN与MAML共享相同的判别器网络架构,并且大多数模型超参数设置与Vanilla卷积MAML(vanilla convolutional MAML)相同[Finn等人,2017]。我们将5-way分类的元批次大小(meta batch-size)设置为16,将20-way分类的元批次大小(meta batch-size)设置为8,以满足GPU的内存限制。对于带有RN的MetaGAN,我们为每个类批处理15个查询图像,分别用于1-shot 5-way和5-shot 5-way分类,为每个类批处理5个查询图像,分别用于1-shot 20-way和5-shot 20-way任务。在所有的实验中,我们用RN模型将MetaGAN的元批量大小设置为1。
在Mini-Imagenet数据集上,考虑到计算成本,我们使用MAML模型来训练我们的MetaGAN,使用(如FINN等人,2017)中提出的1梯度步长(1 gradient step)的一阶近似方法(first-order approximation method)。
对于条件生成器,我们在两种模型中都采用了受[Gullajani等人,2017]启发的类ResNet架构(ResNet-like architecture);请参阅补充材料中生成器架构的更多详细信息。
我们使用初始学习率为0.001,和的Adam优化器来训练生成器和判别器网络。对于Omniglot,我们从10K批次更新开始降低学习率,并在更新后每10K将学习率减半。对于Mini-Imagenet,我们从3万批次开始更新降低学习率,每1万次将学习率更新减半。
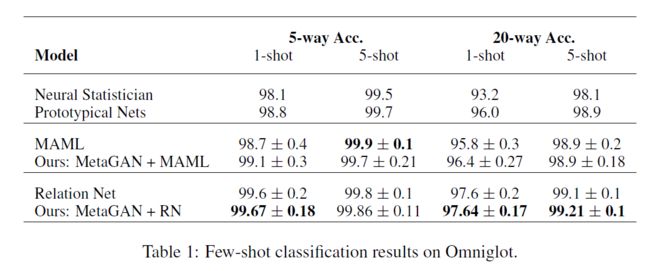
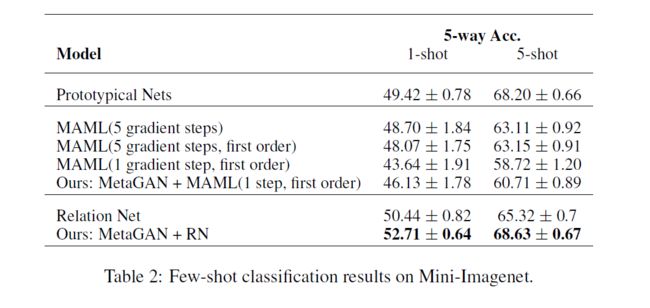
我们在表1中给出了Omniglot数据集的5-way和20-way小样本分类的结果,并在表2中显示Mini-Imagenet数据集的结果。我们发现,我们提出的MetaGAN持续改进了基线分类器,并在具有挑战性的Mini-Imagenet基准上实现了可比或优于当前状态的性能。
5.3 样本级半监督小样本学习(SAMPLE-LEVEL SEMI-SUPERVISED FEW-SHOT LEARNING)
如第3.4节所述,我们评估了我们提出的Metagan在样本水平半监督少镜头学习环境中的有效性,遵循了与[Ren等人,2018]中提出的类似的无“干扰”的训练和评估方案(我们稍后将指出方案中的差异)。对于omniglot数据集,我们对每个类的10%图像进行采样以形成标记集,并将所有剩余数据作为未标记集。对于mini-imagenet,我们将每个类40%的图像作为标记集进行采样,并为每个训练集对每个类的5个图像进行采样。
请注意,我们的模型仅在培训阶段利用未标记样本,而[Ren等人,2018]中提出的精炼模型在培训(每类5个样本)和评估阶段(每类20个样本)都使用未标记样本。与[Ren等人,2018]相比,这使得我们的模型在评估期间获得的信息更少。与基于KMeans的精炼模型(Ren et al.,2018)不同,使用我们提出的Metagan公式训练的分类器能够利用未标记和虚假数据形成更好的决策边界,并且在测试过程中不受未标记样本的要求,KMeans的精炼模型强烈依赖未标记数据进行测试。
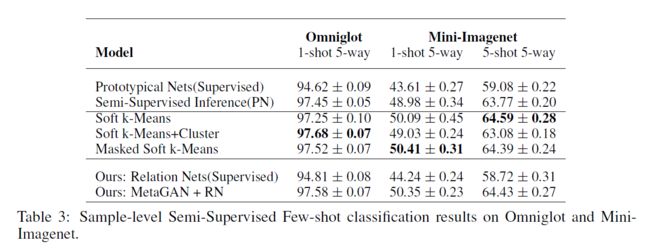
我们在Omniglot和Mini ImageNet上显示了样本级半监督少镜头分类结果,如表3所示。尽管我们的模型不能直接与前面讨论的kmeans优化模型进行比较,但是我们在单镜头和五镜头任务上都获得了可比较的最新结果,同时显著改进了纯监督基线模型。
5.4 任务级半监督小样本学习(TASK-LEVEL SEMI-SUPERVISED FEW-SHOT LEARNING)
在第3.4节:任务级半监督少镜头学习中,我们提出了一种新的学习环境。在该学习设置中,现有的少量镜头学习模型〔Ravi和LaoCelle,2017,Sung等人,2018,任等人,2018〕无法有效地利用纯无监督任务,其仅由支持集和查询集中的未标记样本组成。
为了证明我们提出的metagan模型能够成功地从无监督任务中学习,我们创建了omniglot和mini imagenet数据集的新分割。对于omniglot数据集,我们从训练集中随机抽取10%的类作为标记类集,其余90%的类作为未标记类集。对于mini-imagenet数据集,我们随机抽取40%作为标记类,其余60%未标记。每个数据集的验证集和测试集保持不变,使用所有类来评估模型的性能。在训练过程中,我们只从标记的类集合中抽取有监督任务,而从未标记的类集合中抽取无监督任务。为了训练metagan模型,我们在抽样有监督任务和抽样无监督任务之间切换,而只使用抽样有监督任务训练基线模型。
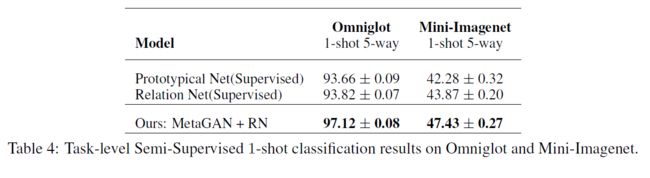
我们将omniglot和mini imagenet上的任务级半监督少镜头分类结果显示在表4中。通过将基线模型集成到metagan框架中,该模型有效地学会了利用无监督任务帮助分类任务,表明metagan可以从完全无监督任务中学习可转移的知识。
6 结论
我们提出了一个简单的通用框架MetaGAN来提高小样本学习模型的性能。我们的方法是基于这样一个想法:由生成器生成的假样本可以帮助分类器从几个样本中学习不同类之间更清晰的决策边界。
我们将小样本学习和半监督学习做了一个类比——它们都只有少量的标记数据,并且都可以从不完善的生成器中获益。然后我们改进了使用GAN的半监督学习技术,使之适用于小样本学习场景。我们对所提出的方法给出了直观和理论上的证明(theoretical justifications)。
我们在一系列的小样本学习和半监督的小样本学习任务中证明了我们算法的优势。为了将来的工作,我们计划将MetaGAN扩展到小样本模拟学习环境。
参考资料
[1] 英伟达最新图像转换神器火了!试玩开放,吸猫爱好者快来
[2] # StarGAN论文及代码理解
[3] starGAN 论文学习
论文下载
[1] MetaGAN: An Adversarial Approach to Few-Shot Learning
在线测试链接
[1] https://nvlabs.github.io/FUNIT/petswap.html
代码
[1] # NVlabs/FUNIT