阅读习惯和个人知识管理体系
进入互联网时代,知识的获取成本变得前所未有的低廉,但是无论再好的知识,若是没有对个人产生价值的话,那也只不过是一种信息噪音而已。我在《个人知识管理:知识的三种形态》这篇文章中使用“材料 -> 资料 -> 知识”这样的路径来诠释信息的流通,如何方便快捷并且有效地收集材料,再将其整理转化为有价值的个人知识体系结构,在这个信息极度碎片化的时代变得尤为重要。而在《去伪存真的知识管理之路》一文中也详细阐述了如何将网络上的碎片化文章纳入统一的稍后阅读体系,比如有时候在朋友圈看到一篇好文章,但暂时没时间直接看,或是这篇文章值得再读一遍,细读一遍,那么我就会将其存入稍后阅读工具即Instapaper当中,诸如此类的还有Pocket、收趣等等。
稍后阅读中永远读不完的痛点:缺乏追踪
随着时间的推移,Instapaper里面的文章将会变得越来越多,就像我们在代码中所注释的TODO:可能就变成了Never Do,“稍后读”也是一样地被广为诟病:Read it Later=Read Never。其实我发现文章堆积的一个永恒痛点就是没有有效的方式追踪自己的阅读需求与能力,其核心原因在于阅读的速度赶不上添加的速度。从而没办法可视化的评估阅读进度、合理安排阅读计划,也就没办法给予自己适当的奖励,长此以往必然将失去阅读的动力。
在之前的一篇文章——《基于GitHub的敏捷学习方法之道与术》,其中提到使用GitHub Issue来管理自己的学习计划,于是就产生了这么一个想法——将我的稍后阅读列表跟GitHub结合起来,使用ZenHub丰富的图表功能将阅读体系进行追踪与可视化。

可视化Cumulative Flow Diagram
首先让我们直接来看一下最终的具体效果图,在这里简单介绍一下CFD(Cumulative Flow Diagram)即累积流图,这是一种能让你快速了解项目或产品工作概况的图表,关注的是价值的流动效率,价值的流动最直接的体现就是需求卡片在各个队列中的数量。
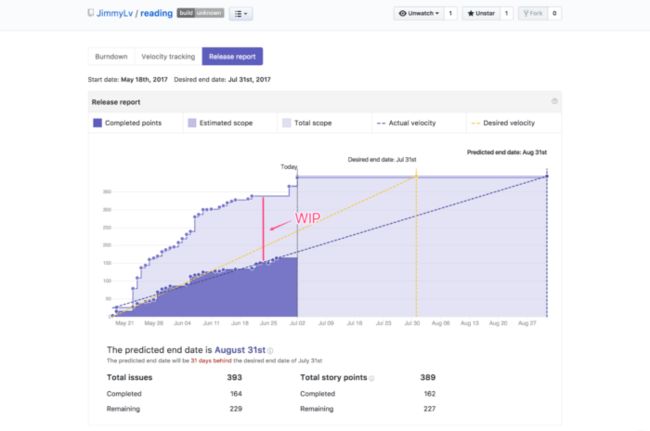
里特定律(Little’s law)告诉我们,交付时间(Delivery time)依赖于在制品数量(Work In Progress, WIP)。WIP是指所有已经初始但还未完成的工作,例如:所有在分析(Analysis)与完成(Done)之间的工作。首先需要留意的就是WIP,如果WIP增加了,交付日期就会有风险。ZenHub所提供的Release Report中最有效果的就是预测完成日期,总之就是跟敏捷方法结合起来,使用项目管理的方式来管理自己的阅读列表,虽然我还处在进一步的探索之中,但是每次看到这个走势图就能对自己的阅读列表有更多的掌控和理解,至少减少了因文章堆积而产生的焦虑感。
IFTTT与Serverless架构
那么这是怎么通过APIs来实现的呢?在真正进入正题之前我们先来简单介绍一下Serverless架构。Serverless指的是在构建Web应用程序的时候,不用担心如何配置服务器,但是这并不意味着应用程序不会在服务器上运行,而是说服务器的管理都可以尽可能地交给相应的云平台,从而最大程度地减轻开发人员的部署与配置工作。与之对应的一个名词可能就是Function As a Service(FAAS),由AWS Lambda这个命名就能想到,当我们在构建Serverless架构时,实际上我们是在写一个个的Function,即函数而已。

流程化:APIs即服务
首先让我们来介绍一下IFTTT即if this then that。通俗的来讲,IFTTT的作用就是当一件事情被触发时,能够执行设定好的另一件事。所谓的「事」,指的是各种应用、服务之间可以进行有趣的连锁反应。IFTTT的宗旨是Put the internet to work for you(让互联网为你服务)。用户可以在IFTTT里设定任何一个你需要的条件,当达成条件时,便会触发下一个指定好的动作。它就像是一座神奇的桥梁,能连接我们日常所用的各种网络服务。

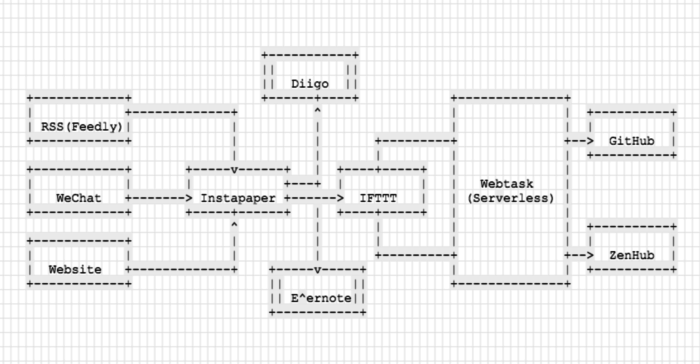
而我们现在遇到的这个串联式的场景是特别合适Serverless架构的,使用IFTTT并且将它跟Instapaper账号绑定,设置文章添加、高亮、归档等行为作为trigger条件,然后将相关信息发到某一个指定API endpoint。先把操作GitHub Issue和ZenHub的各种APIs准备好,结合IFTTT的触发器与Marker工具能够非常方便地与之相集成,最后我们可以产出这样一个APIs交互流程图:
初始化Webtask项目
虽然AWS Lambda是Serverless架构的典范,但它也有一些槽点,而且我觉得已经被人说得足够多了,所以我们今天就来尝尝鲜,着重介绍和使用一下Webtask。你可能没有听说过推出该服务的这家公司——Auth0,但你一定知道大名鼎鼎的JWT即JSON Web Token,这是一种开放标准RFC 7519,通常被运用在身份验证(Authentication)和信息交换等需要安全传输信息的场景下。
首先让我们来安装工具初始化项目以及注册账号,然后使用电子邮件进行登录:
npm install -g wt-cli
wt init
创建项目目录,添加index.js文件并添加以下内容:
module.exports = function (cb) {
cb(null, 'Hello World');
}
然后在该目录中运行以下命令,进行应用程序部署之后,点击控制台中输出的URL就能看到编程史上最有名气、没有之一的HelloWorld!:
wt create index

Webtask的上下文绑定
Webtask有一个实用工具webtask-tools,可以将应用程序绑定到Webtask上下文,让我们将之前所export的简单函数修改为绑定到Webtask的Express app,然后就可以愉快地使用Express进行开发,一切就又回到了熟悉的轨道:
app.use(bodyParser.urlencoded({ extended: false }))
app.use(bodyParser.json())
require('./routes/reading')(app)
module.exports = Webtask.fromExpress(app)
Webtask context还有一个非常重要的用途,就是在部署时传输一些敏感信息,比如安全Token,从而在应用程序当中随时使用它们。下面的部署命令中--secret后面所传入的ACCESS_TOKEN都会在后续与GitHub和ZenHub APIs交互时被用到。
wt create index --bundle --secret GITHUB_ACCESS_TOKEN=$GITHUB_ACCESS_TOKEN
--secretZENHUB_ACCESS_TOKEN=$ZENHUB_ACCESS_TOKEN --secret
ZENHUB_ACCESS_TOKEN_V4=$ZENHUB_ACCESS_TOKEN_V4
# ./routes/reading.js
module.exports = (app) => {
app.post('/reading', (req, res) => {
const { GITHUB_ACCESS_TOKEN, ZENHUB_ACCESS_TOKEN, ZENHUB_ACCESS_TOKEN_V4 } = req.webtaskContext.secrets
}
}
使用GitHub Issue追踪阅读列表
IFTTT:添加Instapaper文章后自动创建GitHub Issue
得益于IFTTT非常丰富的第三方服务,IFTTT可以直接创建Instapaper与GitHub Issue相集成的Applet:If new item saved, then create a new issue - IFTTT,就可以在当Instapaper新增文章的时候,自动在GitHub所指定的仓库Issues · JimmyLv/reading 中创建一个新的Issue并添加相应的标题、链接以及描述等相关信息。

但仅仅只是添加一个Issue还不够,这时候还需要将这个Issue加入到指定的Milestone以便利用ZenHub的图表功能,使用GitHub的Webhooks功能就可以轻松帮我们把Issue更新的状态转发到我们所指定的Webtask地址:
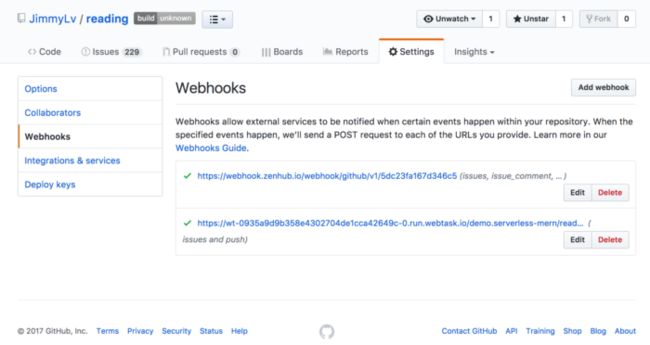
使用GitHub Webhook 更新Issue的Milestone
所以我们的Webtask就需要处理GitHub Webhook所转发的POST请求,其中包括了Issue的类型和内容,在拿到'opened'即新建Issue类型的action之后我们可以对其进行相应的处理,即添加到Milestone当中:
if (action === 'opened') {
fetch(`${url}?access_token=${GITHUB_ACCESS_TOKEN}`, {
method: 'PATCH',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
milestone: 1
})
})
}
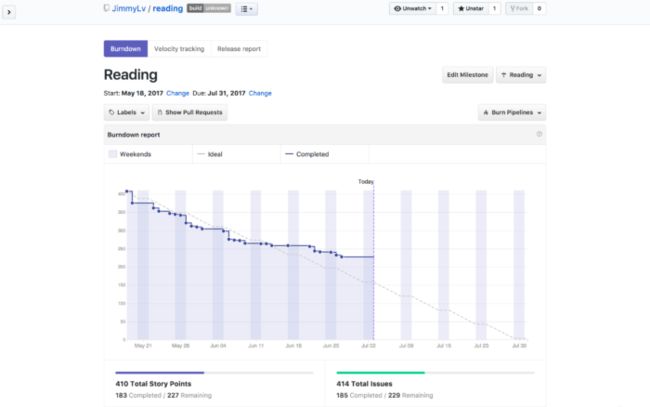
结合ZenHub的Milestone燃尽图我们可以清晰地看到剩余阅读量,并且能够跟理想中的阅读速度进行对比,从而判断自己什么时候能够全部读完所有的文章。可能有些小伙伴看到这里会有所疑问,这些所谓的Story Point是从哪儿来的呢?接下来就要提到我们将要集成的ZenHub API了。
集成ZenHub API:阅读可视化
更新Issue的估点和Release
GitHub Issue的任何变动都会触发Webhook,因此我们可以在Issue被加入Milestone之后再处理下一个'milestoned' action,即:
if (action === 'milestoned') {
fetch(`https://api.zenhub.io/p1/repositories/${REPO_ID}/issues/${number}/estimate?access_token=${ZENHUB_ACCESS_TOKEN}`, {
method: 'PUT',
body: JSON.stringify({ estimate: 1 })
})
.then(() => {
return
fetch(`https://api.zenhub.io/v4/reports/release/591dc19e81a6781f839705b9/items/issues?access_token=${ZENHUB_ACCESS_TOKEN_V4}`,
{
method: 'POST',
})
})
}
这样我们就完成了对每个GitHub Issue的估点,以及设置了对应的Release,接下来所有的变动都将体现在ZenHub的图表当中。
归档Instapaper文章后关闭GitHub Issue
说了这么多,不要忘了整个阅读系统最最核心的部分依然还是「阅读」啊!在众多的稍后阅读工具中我无比喜爱Instapaper并迟迟没有转到Diigo的原因就在于它优秀、简洁、纯粹的阅读体验,让人可以专注在阅读本身这件事情上,在被Pinterest收购之后更是将所有的诸如全文搜索、无限高亮/笔记、速读等Premium功能都变成了免费,岂不美哉?

那么在完成阅读归档之后,最后一步就是在GitHub当中将Issue关闭掉,但是IFTTT的GitHub服务并没有提供close Issue的接口,于是乎我们就只有利用IFTTT新推出的Maker自己创建一个,即将Instapaper规划作为一个IF trigger,然后用Maker发出一个Web请求,可以是GET、PUT、POST、HEAD、DELETE、PATCH或者OPTIONS之中的任何一种,你甚至还可以制定Content Type和Body。

app.get('/reading', (req, res) => {
const { GITHUB_ACCESS_TOKEN } = req.webtaskContext.secrets
const title = req.query.title
let keyword = encodeURIComponent(title.replace(/\s/g, '+'))
fetch(`https://api.github.com/search/issues?q=${keyword}%20repo:jimmylv/reading`)
.then(data => {
if (data.total_count > 0) {
data.items.forEach(({ url, html_url }) =>
fetch(`${url}?access_token=${GITHUB_ACCESS_TOKEN}`, {
method: 'PATCH',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ state: 'closed' }),
})
}
})
}
上述代码就可以用于处理IFTTT Marker所发送的GET请求,我们从query参数中取到文章标题之后再去搜索相对应的Issues,再通过GitHub API将其关闭。
而与此同时,我们在文章的阅读过程中,有时候也会想要对文章中的亮点部分进行高亮,甚至添加自己的一些想法和总结,那我们也可以用IFTTT Marker和Webtask的套路添加至GitHub Issues的comments当中。具体的详细代码就不贴了,更多内容都已经放在我的GitHub上:JimmyLv/demo.serverless-mern,与此同时我的阅读列表也公开在GitHub上:Issues · JimmyLv/reading,欢迎围观。
总结与后续计划
随着时间的推移,日常你只需要在Instapaper添加并阅读文章即可,而背后利用Serverless所搭建的整套阅读追踪系统将会任劳任怨的帮你记录下所有的踪迹和笔记,你只需要在特定的时候定期review、分析阅读的效果与预测效果,与此同时结合自己的时间统计系统,持续不断地改进自己的阅读目标与阅读计划。

最后再来考虑一下后续计划,比如说我现在只是简单把Instapaper中高亮部分和阅读笔记作为评论放到GitHub的comments里面,但是最终我需要把它收藏到自己的个人知识库即Diigo,这也是可以通过API自动实现的,以及最终需要被刻意记忆的部分还需要与Tinycards或者QuizletAPI相集成,对抗艾宾浩斯遗忘曲线。
与此同时,还需要根据文章类型和难易程度具体划分一下估点,而不是现在简简单单的1点,比如说Instapaper也有根据字数来预测的阅读分钟数,以及根据中文或英文、技术或鸡汤等不同种类文章阅读难度进行区分,从而使整套追踪系统更具有效性与参考性。
文/ThoughtWorks吕靖