pandas 如何把时间转成index_Pandas教程:初学者入门必备,很全面,很详细!

学习Panda一些最重要的特性,用于对数据进行探索、清洗、转换、可视化以及从数据中学习。
Pandas库是当今使用Python进行工作的数据科学家和分析师所使用的最重要的工具。强大的机器学习和迷人的可视化工具可能会吸引大家关注,但是,Pandas是大多数数据项目的基础。
[pandas]源自术语“panel data”,这是计量经济学中用于描述数据集的术语,这些数据集是对一些个体在多个时间段内的观察结果。—维基百科
如果你正考虑将数据科学视为一种职业,那么当务之急就是要做的第一件事就是学习Pandas。在本文中,我们将介绍有关Pandas的基本信息,包括如何安装,如何使用以及如何与其他常见的Python数据分析包(例如matplotlib和scikit-learn)一起使用。
Pandas是用来干什么的?
Pandas有很多用途,把它不能做的事情列出来,而不是它能做的事情,也许是有意义的。此工具实际上是你数据的家。通过Pandas,您可以通过清理,转换和分析数据来了解数据。例如,假设您要浏览计算机上以CSV格式存储的数据集。Pandas将从CSV中提取数据到一个DataFrame(基本上是一个表)中,然后让您执行以下操作:
- 计算统计数据并回答有关数据的问题,例如
- 每列的平均值,中位数,最大值或最小值是多少?
- A列与B列相关吗?
- C列中的数据分布是什么样的?

在进入建模或复杂的可视化之前,您需要对数据集的性质有充分的了解,而Pandas是实现此目的的最佳途径。
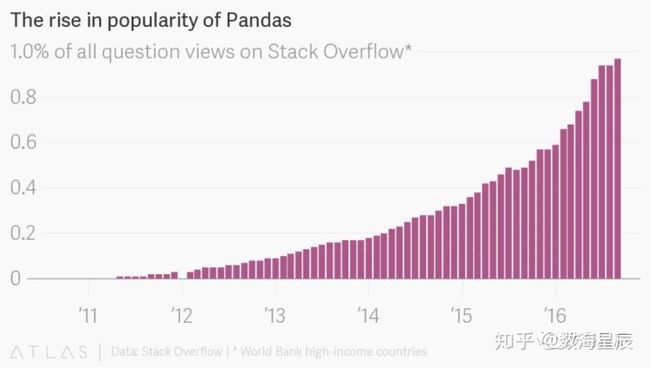
Pandas如何算得上数据科学工具包?
Pandas不仅是数据科学工具包的重要组成部分,而且与该包中的其它库一起使用。
Pandas基于Numpy库构建,这意味着NumPy的许多结构都在Pandas中被使用或复制。Pandas中的数据通常用于SciPy中的统计分析,Matplotlib中的绘图功能以及Scikit-learn中的机器学习算法。
Jupyter Notebook提供了一个使用Pandas进行数据探索和建模的良好环境,但是Pandas也可以轻松地用于文本编辑器中。Jupyter Notebooks使我们能够在特定的单元格中执行代码,而不是运行整个文件。使用大型数据集和复杂转换时,这可以节省大量时间。Notebook还提供了一种简便的方法来可视化Pandas的数据框和图表。
Pandas的基本功能–数据科学家使用的4个主要功能mp.weixin.qq.com
你应该什么时候使用Pandas?
如果您没有使用Python进行编码的经验,那么您应该避免学习Pandas,直到您开始学习为止。您不必一定是软件工程师,但是您应该擅长Python编程的基础知识,例如列表,元组,字典,函数和迭代。另外,由于上述相似之处,我还建议您熟悉NumPy。
此外,对于那些希望进行数据科学训练营或其他一些加速数据科学教育计划的人,强烈建议您在开始该程序之前先自己学习Pandas。
即使集中训练可以教您Pandas,但事先具备更好的技能意味着您将能够最大限度地利用时间来学习和掌握更复杂的材料。
Pandas第一步
安装并导入
Pandas是易于安装的软件包。打开您的终端程序(对于Mac用户)或命令行(对于PC用户),然后使用以下任一命令进行安装:
conda install pandas或者
pip install pandas或者,如果您当前正在Jupyter笔记本中查看本文,则可以运行以下单元格:
!pip install pandas在开处“!”,表示在终端一样运行单元格。要导入Pandas,我们通常使用较短的名称来导入Pandas,因为它使用了很多:
import pandas as pd现在介绍Pandas的基本构成。
pandas库的核心部分: Series和DataFrames
Pandas的主要两个组成部分是Series和DataFrame。Series本质上是一列,而DataFrame是由Series集合组成的多维表。
15个Pandas最佳特性,是什么让Pandas如何特别?mp.weixin.qq.com

DataFrame和Series非常相似,因为您可以对一个进行许多操作,而对另一个进行其他操作,例如填充空值和计算均值。当我们开始使用以下数据进行工作时,您将看到这两个核心组件的用法。
JupyterLab最全详解,如果你还在使用Notebook,那你就out了!mp.weixin.qq.com
从头开始创建DataFrames
在Python中创建DataFrames是一个很好的知识,并且在测试您在pandas文档中发现的新方法和函数时非常有用。
有很多方法可以从头开始创建DataFrame,但是一个不错的选择是只使用一个简单的dict。
假设我们有一个卖苹果和橙子的水果摊。我们希望每个水果都有一列,每个客户购买都有一行。要将其组织为pandas字典,我们可以执行以下操作:
data = {
'apples': [3, 2, 0, 1],
'oranges': [0, 3, 7, 2]
}然后将其传递给pandas DataFrame构造函数:
purchases = pd.DataFrame(data)
purchases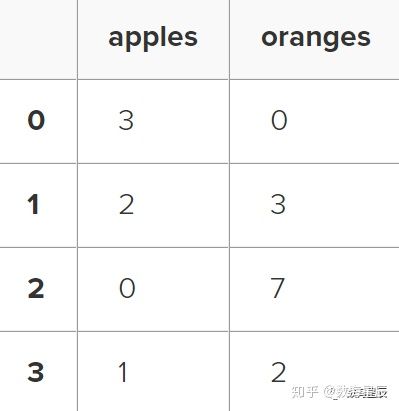
这是怎么回事呢?
数据中的每个(键,值)对都对应于结果DataFrame中的一列。
该数据框的索引是在创建时以数字0-3的形式提供给我们的,但是在初始化数据框时也可以创建自己的索引。让我们以客户名称作为索引:
purchases = pd.DataFrame(data, index=['June', 'Robert', 'Lily', 'David'])
purchases
因此,现在我们可以使用客户名称来查找客户的订单:
>>> purchases.loc['June']
apples 3
oranges 0
Name: June, dtype: int64稍后将有更多关于从DataFrame定位和提取数据的信息,但是现在您应该能够使用任何随机数据创建一个DataFrame进行学习。
让我们继续学习一些从其他各种来源快速创建DataFrame的方法。
如何读取数据
将各种文件格式的数据加载到DataFrame中非常简单。在以下示例中,我们将继续使用苹果和橘子数据,但这一次它来自各种文件。
史上最全的Python基础语法知识清单mp.weixin.qq.com
从CSV读取数据
使用CSV文件,您只需要一行即可加载数据:
df = pd.read_csv('purchases.csv')
df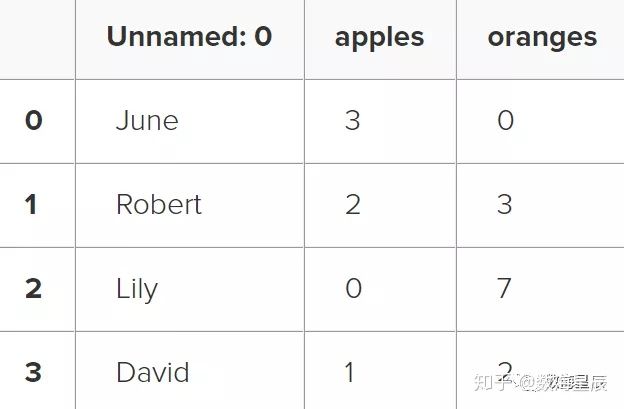
CSV没有像DataFrames这样的索引,因此我们需要做的只是在读取时指定index_col:
df = pd.read_csv('purchases.csv', index_col=0)
df
在这里,我们将索引设置为零列。
您会发现大多数CSV都不会包含索引列,因此通常您不必担心此步骤。
从JSON读取数据
如果您有一个JSON文件-本质上是一个存储的Python字典-Pandas可以轻松读取它:
df = pd.read_json('purchases.json')
df
请注意,这一次我们的索引正确地伴随了我们,因为使用JSON允许索引通过嵌套工作。随时在记事本中打开data_file.json,以了解其工作原理。
Pandas会尝试通过分析JSON的结构来弄清楚如何创建DataFrame,有时它做得不好。通常,您需要根据结构来设置orient关键字参数,因此请查看有关该参数的read_json文档,以查看所使用的方向。
使用Scrapy,帮你快速抓取网页数据(代码可下载)!mp.weixin.qq.com
从SQL数据库读取数据
如果您要使用SQL数据库中的数据,则需要先使用适当的Python库建立连接,然后将查询传递给Pandas。在这里,我们将使用SQLite进行演示。首先,我们需要安装pysqlite3,因此请在您的终端中运行以下命令:pip安装pysqlite3或者,如果您在笔记本电脑中,请运行此单元格:
!pip install pysqlite3sqlite3用于创建与数据库的连接,然后我们可以将其用于通过SELECT查询生成DataFrame。因此,首先我们将连接到SQLite数据库文件:
import sqlite3
con = sqlite3.connect("database.db")SQL提示
如果您在PostgreSQL,MySQL或某些其他SQL Server中具有数据,则需要获取正确的Python库来建立连接。例如,psycopg2(链接)是建立与PostgreSQL连接的常用库。此外,您将连接到数据库URI,而不是像我们在SQLite上所做的那样连接到文件。
在此SQLite数据库中,我们有一个名为purchase的表,并且索引位于名为“ index”的列中。通过传递SELECT查询和我们的骗局,我们可以从购买表中读取:
df = pd.read_sql_query("SELECT * FROM purchases", con)
df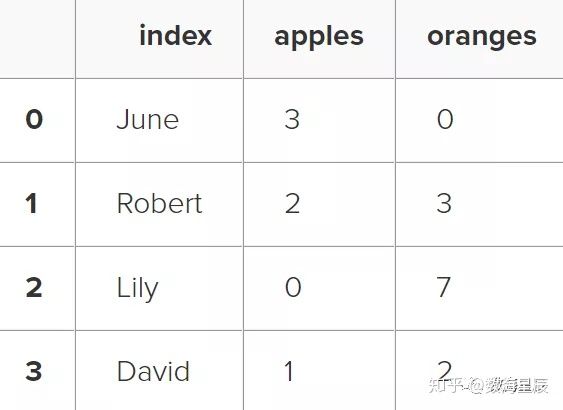
就像CSV一样,我们可以传递index_col ='index',但是我们也可以事后设置索引:
df = df.set_index('index')
df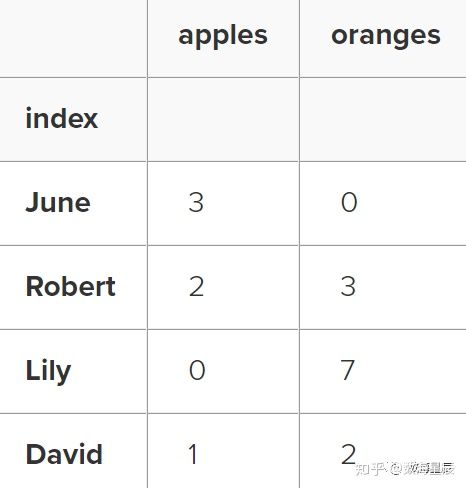
实际上,我们可以随时在任何使用任何列的DataFrame上使用set_index()函数。为Series和DataFrames建立索引是一项非常常见的任务,同时,创建的不同方法是值得记住的。
转换回CSV,JSON或SQL
因此,在完成清理数据的大量工作之后,您现在就可以将其保存为您选择的文件了。与我们读取数据的方式类似,pandas提供了直观的命令来保存数据:
df.to_csv('new_purchases.csv')
df.to_json('new_purchases.json')
df.to_sql('new_purchases', con)当我们保存JSON和CSV文件时,我们需要输入到这些函数中的是带有所需文件扩展名的所需文件名。使用SQL,我们不会创建新文件,而是使用之前的con变量将新表插入数据库。让我们继续导入一些真实世界的数据,并详细介绍一些您将经常使用的操作。
最重要的DataFrame操作
DataFrame具有数百种对任何分析都至关重要的方法和其他操作。作为初学者,您应该知道执行数据简单转换的操作以及提供基本统计分析的操作。让我们加载IMDB电影数据集以开始:
movies_df = pd.read_csv("IMDB-Movie-Data.csv", index_col="Title")我们正在从CSV加载此数据集,并指定电影标题作为索引。
查看数据
打开新数据集时,要做的第一件事是打印出几行以作为可视参考。我们使用.head()完成此操作:
movies_df.head()
.head()默认情况下输出DataFrame的前五行,但是我们也可以传递一个数字:例如movie_df.head(10)将输出前十行。
要查看最后五行,请使用.tail()。tail()也接受一个数字,在这种情况下,我们打印底部的两行:
movies_df.tail(2)
通常,当我们加载数据集时,我们希望查看前五行左右,以了解其背后的内容。在这里,我们可以看到每一列的名称,索引以及每一行中值的示例。您会注意到,DataFrame中的索引是“标题”列,您可以通过“标题”一词比其他列略低些来判断。
获取有关您的数据的信息
.info()应该是加载数据后运行的第一个命令之一:
>>> movies_df.info()
Index: 1000 entries, Guardians of the Galaxy to Nine Lives
Data columns (total 11 columns):
Rank 1000 non-null int64
Genre 1000 non-null object
Description 1000 non-null object
Director 1000 non-null object
Actors 1000 non-null object
Year 1000 non-null int64
Runtime (Minutes) 1000 non-null int64
Rating 1000 non-null float64
Votes 1000 non-null int64
Revenue (Millions) 872 non-null float64
Metascore 936 non-null float64
dtypes: float64(3), int64(4), object(4)
memory usage: 93.8+ KB .info()提供有关数据集的基本详细信息,例如行和列的数量,非空值的数量,每列中的数据类型以及DataFrame使用的内存量。
请注意,在电影数据集中,“收入”和“ Metascore”列中有一些明显的缺失值。我们将稍等一下。快速查看数据类型实际上非常有用。假设您刚刚导入了一些JSON,并且整数被记录为字符串。您需要进行一些算术运算,并找到“不受支持的操作数”异常,因为您无法使用字符串进行数学运算。调用.info()会很快指出您认为所有整数的列实际上都是字符串对象。
另一个快速而有用的属性是.shape,它仅输出(行, 列)的元组:
>>> movies_df.shape
(1000, 11)请注意,.shape没有括号,并且是格式(行, 列) 的简单元组。因此,我们的影片DataFrame中有1000行和11列。清理和转换数据时,您将需要进行很多调整。例如,您可能根据某些条件过滤了一些行,然后想要快速知道删除了多少行。
处理重复项
该数据集没有重复的行,但是确保您没有汇总重复的行始终很重要。为了演示,让我们简单地通过将影片DataFrame附加到自身上来使其加倍:
>>> temp_df = movies_df.append(movies_df)
>>> temp_df.shapev
(2000, 11)使用append()将返回一个副本,而不会影响原始DataFrame。我们正在临时捕获此副本,因此我们不使用实际数据。通知呼叫.shape很快证明我们的DataFrame行已加倍。现在我们可以尝试删除重复项:
>>> temp_df = temp_df.drop_duplicates()
>>> temp_df.shape
(1000, 11)就像append()一样,drop_duplicates()方法也将返回DataFrame的副本,但是这次删除了重复项。调用.shape确认我们回到了原始数据集的1000行。像本例中那样,继续将DataFrames分配给相同的变量有点冗长。因此,pandas的许多方法都具有inplace关键字参数。使用inplace = True将在适当位置修改DataFrame对象:
temp_df.drop_duplicates(inplace=True)现在,我们的temp_df将自动具有转换后的数据。
drop_duplicates()的另一个重要参数是keep,它具有三个可能的选项:
- first :(默认)删除除第一个匹配项外的重复项。
- last:除去最后一次出现的重复项。
- False:删除所有重复项。
由于我们在上一个示例中没有定义保留方式,因此默认情况下将其设置为first。这意味着如果两行相同,则Pandas会掉落第二行并保留第一行。使用last具有相反的效果:删除第一行。另一方面,keep会删除所有重复项。如果两行相同,则都将被丢弃。观察temp_df发生了什么:
>>> temp_df = movies_df.append(movies_df) # make a new copy
>>> temp_df.drop_duplicates(inplace=True, keep=False)
>>> temp_df.shape
(0, 11)由于所有行都是重复的,因此keep = False丢弃了所有行,导致剩下零行。如果您想知道为什么要这样做,原因之一是它允许您查找数据集中的所有重复项。当下面显示条件选择时,您将看到如何执行此操作。
列清理
很多时候,数据集会有冗长的列名,包括符号,大写和小写单词,空格和错别字。为了使按列名选择数据更加容易,我们可以花一些时间清理它们的名称。以下是打印数据集的列名称的方法:
>>> movies_df.columns
Index(['Rank', 'Genre', 'Description', 'Director', 'Actors', 'Year', 'Runtime (Minutes)', 'Rating', 'Votes', 'Revenue (Millions)', 'Metascore'],
dtype='object')如果希望通过简单的复制和粘贴来重命名列,.columns不仅会派上用场,而且当您需要了解为什么按列选择数据时为什么会收到“Key Error”时,.columns也很有用。
我们可以使用.rename()方法通过dict重命名某些或所有列。我们不需要括号,所以让我们重命名它们:
>>> movies_df.rename(columns={
'Runtime (Minutes)': 'Runtime',
'Revenue (Millions)': 'Revenue_millions'
}, inplace=True)
>>> movies_df.columns
Index(['Rank', 'Genre', 'Description', 'Director', 'Actors', 'Year', 'Runtime',
'Rating', 'Votes', 'Revenue_millions', 'Metascore'],
dtype='object')这很好。但是,如果我们要小写所有名称怎么办?除了使用.rename()之外,我们还可以像这样为列设置名称列表:
>>> movies_df.columns = ['rank', 'genre', 'description', 'director', 'actors', 'year', 'runtime',
'rating', 'votes', 'revenue_millions', 'metascore']
>>> movies_df.columns
Index(['rank', 'genre', 'description', 'director', 'actors', 'year', 'runtime',
'rating', 'votes', 'revenue_millions', 'metascore'],
dtype='object')但这是太多的工作。不仅可以手动重命名每列,我们还可以进行列表理解:
>>> movies_df.columns = [col.lower() for col in movies_df]
>>> movies_df.columns
Index(['rank', 'genre', 'description', 'director', 'actors', 'year', 'runtime',
'rating', 'votes', 'revenue_millions', 'metascore'],
dtype='object')列表(和字典)理解通常在使用Pandas处理数据时会派上用场。如果您将使用数据集一段时间,则最好进行小写转换,删除特殊字符并用下划线替换空格。
如何处理缺失值
浏览数据时,您很可能会遇到缺失或空值,它们实际上是不存在的值的占位符。最常见的是,您会看到Python的None或NumPy的np.nan,在某些情况下,每种处理方式都不同。
处理空值有两种选择:
- 移除到包含空值的行或列
- 用非空值替换空值,这种技术被称为插补
让我们计算数据集每一列中的空值总数。第一步是检查DataFrame中的哪些单元格为空:
movies_df.isnull()
请注意,isnull()返回一个DataFrame,其中每个单元格为True或False,具体取决于该单元格的null状态。要计算每列中的空值数量,我们使用聚合函数求和:
>>> movies_df.isnull().sum()
rank 0
genre 0
description 0
director 0
actors 0
year 0
runtime 0
rating 0
votes 0
revenue_millions 128
metascore 64
dtype: int64.isnull()本身并不是很有用,通常与其他方法( 例如sum())结合使用。
现在我们可以看到,我们的数据的Revenue_millions缺少128个值,而metascore缺少64个值。
删除空值
数据科学家和分析师经常会遇到丢弃或插补空值的难题,这是一项需要对您的数据及其上下文有深入了解的决定。总体而言,仅在缺少少量数据的情况下才建议删除空数据。
删除空值非常简单:
movies_df.dropna()此操作将删除至少具有单个null值的任何行,但它将返回一个新的DataFrame而不会更改原始的DataFrame。您也可以在此方法中指定inplace = True。
因此,对于我们的数据集,此操作将删除128个行(其中Revenue_millions为null)和64个行(其中metascore为null)。这显然是一种浪费,因为在那些删除的行的其他列中都有非常好的数据。这就是为什么我们接下来要考虑归因的原因。
除了删除行之外,还可以通过设置axis = 1来删除具有空值的列:
movies_df.dropna(axis=1)在我们的数据集中,此操作将删除Revenue_millions和metascore列。
判断
axis= 1参数是什么?
现在还不清楚轴的来源以及为什么需要将其设为1才能影响列。要查看原因,只需查看.shape
>>> movies_df.shape
(1000,11)如上所述,这是一个表示DataFrame形状的元组,即1000行11列。请注意,行位于该元组的索引零,列位于该元组的索引一。这就是为什么axis = 1影响列的原因。这来自NumPy,是为什么学习NumPy值得您花时间的一个很好的例子。
插补
插补是一种传统的特征工程技术,用于保留具有空值的有价值的数据。在某些情况下,删除具有空值的每一行会从数据集中删除太大的块,因此我们可以使用另一个值(通常是该列的均值或中位数)来估算该空值。让我们看一下在Revenue_millions列中估算缺少的值。首先,我们将该列提取到其自己的变量中:
revenue = movies_df['revenue_millions']使用方括号是我们在DataFrame中选择列的一般方式。如果您还记得我们从头开始创建DataFrame的时候,那么dict的键最终将作为列名。现在,当我们选择DataFrame的列时,就像在访问Python字典一样,我们使用方括号。revenue现在包含一个Series:
>>> revenue.head()
Title
Guardians of the Galaxy 333.13
Prometheus 126.46
Split 138.12
Sing 270.32
Suicide Squad 325.02
Name: revenue_millions, dtype: float64格式与DataFrame略有不同,但是我们仍然拥有Title索引。我们将使用均值估算收入的缺失值。这是平均值:
>>> revenue_mean = revenue.mean()
>>> revenue_mean
82.95637614678897用均值,让我们使用fillna()填充空值:
revenue.fillna(revenue_mean, inplace=True)现在,我们将收入的所有空值替换为该列的平均值。注意,通过使用inplace = True,我们实际上已经影响了原始的movie_df:
>>> movies_df.isnull().sum()
rank 0
genre 0
description 0
director 0
actors 0
year 0
runtime 0
rating 0
votes 0
revenue_millions 0
metascore 64
dtype: int64像这样用相同的值插入整列是一个基本示例。尝试由Genre或Director进行更细化的插补是一个更好的主意。
例如,您将找到每个genre产生的收益的平均值,并使用该genre的平均值推算每个genre中的空值。现在让我们看一下检查和理解数据集的更多方法。
了解您的变量
在整个DataFrame上使用describe(),我们可以得出连续变量分布的摘要:
movies_df.describe()
在考虑用于可视化表示数据的绘图类型时,了解哪些数字是连续的也是很方便的。
.describe()也可以用于分类变量,以获取行数,类别的唯一计数,顶层类别和顶层类别的频率:
>>> movies_df['genre'].describe()
count 1000
unique 207
top Action,Adventure,Sci-Fi
freq 50
Name: genre, dtype: object这告诉我们,genre列有207个唯一值,最高值是Action/Adventure/Sci-Fi, 显示了50次(频率)。.value_counts()可以告诉我们列中所有值的频率:
>>> movies_df['genre'].value_counts().head(10)
Action,Adventure,Sci-Fi 50
Drama 48
Comedy,Drama,Romance 35
Comedy 32
Drama,Romance 31
Action,Adventure,Fantasy 27
Comedy,Drama 27
Animation,Adventure,Comedy 27
Comedy,Romance 26
Crime,Drama,Thriller 24
Name: genre, dtype: int64连续变量之间的关系
通过使用相关方法.corr(),我们可以生成每个连续变量之间的关系:
movies_df.corr()
相关表是数据集中双变量关系的数字表示。正数表示正相关-一个上升,另一个上升-负数表示反相关-一个上升,另一个下降。1.0表示完美的相关性。
因此,在第一行第一列中,我们看到rank与自身之间具有完美的相关性,这是显而易见的。另一方面,votes与Revenue_Millions之间的相关性是0.6。更有趣一点。当您考虑到结果或因变量并且想要查看与结果的增加或减少最相关的功能时,检查双变量关系会很方便。您可以用散点图直观地表示双变量关系(见下图部分)。现在让我们更多地了解如何操作DataFrames。
数据切片,选择,提取
到目前为止,我们只专注于数据的一些基本摘要。我们已经学习了使用单括号进行简单列提取的方法,并使用fillna()在列中估算了空值。以下是切片,选择和提取的其他方法,您需要不断使用它们。
重要的是要注意,尽管许多方法是相同的,但DataFrame和Series具有不同的属性,因此您必须确保知道使用的是哪种类型,否则将收到属性错误。
让我们先来看一下使用列。按列,您已经了解了如何使用方括号提取列,如下所示:
>>> genre_col = movies_df['genre']
>>> type(genre_col)
pandas.core.series.Series这将返回一个Series。要将列提取为DataFrame,您需要传递一个列名的列表。在我们的例子中,这只是一列:
>>> genre_col = movies_df[['genre']]
>>> type(genre_col)
pandas.core.frame.DataFrame由于它只是一个列表,因此添加另一个列名很容易:
subset = movies_df[['genre', 'rating']]
subset.head()
现在我们来看按行获取数据。
按行
对于行,我们有两个选择:
- .loc-按名称查找
- .iloc-通过数字索引定位
请记住,我们仍按电影标题来索引,因此要使用.loc,我们给它指定电影的标题:
>>> prom = movies_df.loc["Prometheus"]
>>> prom
rank 2
genre Adventure,Mystery,Sci-Fi
description Following clues to the origin of mankind, a te...
director Ridley Scott
actors Noomi Rapace, Logan Marshall-Green, Michael Fa...
year 2012
runtime 124
rating 7
votes 485820
revenue_millions 126.46
metascore 65
Name: Prometheus, dtype: object另一方面,使用iloc,我们为它提供Prometheus的数值索引:
prom = movies_df.iloc[1]loc和iloc可以认为类似于Python列表切片。为了进一步说明这一点,让我们选择多行。您将如何处理清单? 在Python中,只需用方括号进行切片,例如example_list [1:4]。在熊猫中,其工作方式相同:
movie_subset = movies_df.loc['Prometheus':'Sing']
movie_subset = movies_df.iloc[1:4]
movie_subset
使用.loc和.iloc选择多行之间的一个重要区别是.loc将电影Sing包含在结果中,但是当使用.iloc时,我们得到的行是1:4,但索引4(自杀小队)的电影却没有 包括在内。.iloc的切片遵循与列表切片相同的规则,不包括末尾索引处的对象。
条件选择
我们已经讨论了如何选择列和行,但是如果要进行条件选择怎么办?
例如,如果我们要筛选电影数据帧以仅显示由Ridley Scott执导的电影或评级大于或等于8.0的电影怎么办?
为此,我们从DataFrame中获取一列,然后对其应用布尔条件。这是布尔条件的示例:
>>> condition = (movies_df['director'] == "Ridley Scott")
>>> condition.head()
Title
Guardians of the Galaxy False
Prometheus True
Split False
Sing False
Suicide Squad False
Name: director, dtype: bool与isnull()相似,这将返回一系列“真”和“假”值:对于由雷德利·斯科特执导的电影而言为“真”,对于不由他执导的电影而言为“假”。
我们想要过滤掉所有非雷德利·斯科特(Ridley Scott)执导的电影,换句话说,我们不想要假电影。要返回条件为True的行,我们必须将此操作传递到DataFrame中:
movies_df[movies_df['director'] == "Ridley Scott"]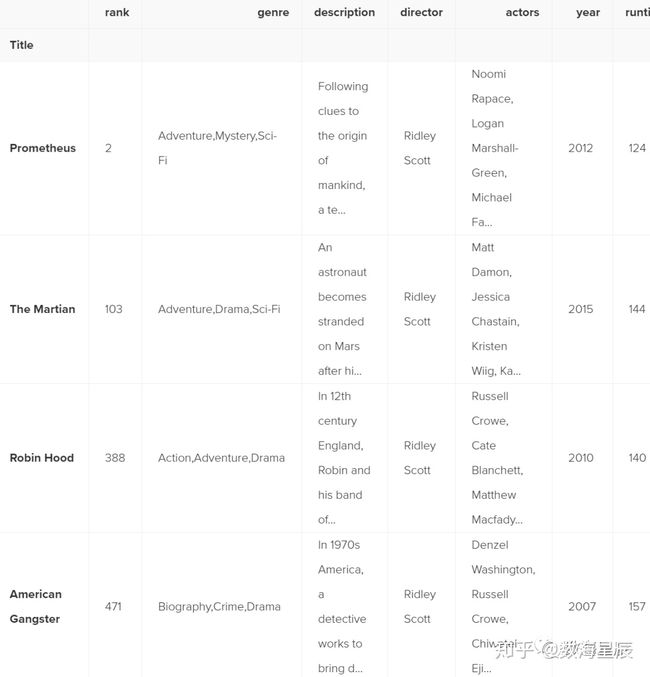
您可以通过阅读以下内容来熟悉这些条件:选择movies_df导演等于里德利·斯科特的movies_df。让我们通过按等级过滤DataFrame来查看使用数值的条件选择:
movies_df[movies_df['rating'] >= 8.6].head(3)
我们可以通过使用逻辑运算符来制作一些更丰富的条件。| 为"或",&为“与”。让我们过滤数据框以仅显示Christopher Nolan或Ridley Scott的电影:
movies_df[(movies_df['director'] == 'Christopher Nolan') | (movies_df['director'] == 'Ridley Scott')].head()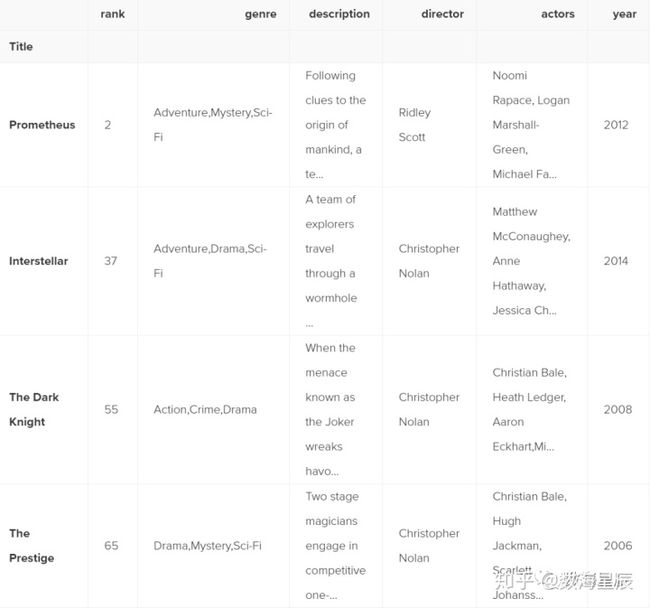
我们需要确保用括号将评估分组,以便Python知道如何评估条件。使用isin()方法,我们可以使它更简洁:
movies_df[movies_df['director'].isin(['Christopher Nolan', 'Ridley Scott'])].head()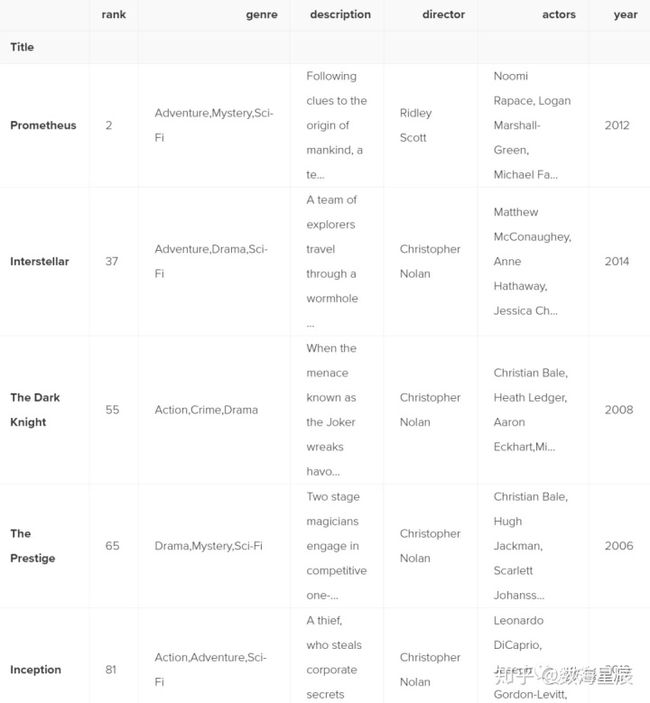
假设我们希望在2005年至2010年之间发行的所有电影的评级都高于8.0,但收入却低于25%。这就是我们可以做的所有事情:
movies_df[
((movies_df['year'] >= 2005) & (movies_df['year'] <= 2010))
& (movies_df['rating'] > 8.0)
& (movies_df['revenue_millions'] < movies_df['revenue_millions'].quantile(0.25))
]
如果您回想起使用.describe()时收入的第25个百分位数大约是17.4,则可以通过使用float值为0.25的Quantile()方法直接访问此值。所以在这里,我们只有四部符合该标准的电影。
使用函数
可以像使用列表那样遍历DataFrame或Series,但是这样做(特别是在大型数据集上)非常慢。一种有效的替代方法是将函数套用到数据集。例如,我们可以使用一个函数将8.0或更高版本的电影转换为字符串值“好”,其余转换为“坏”,然后使用此转换后的值创建一个新列。首先,我们将创建一个函数,该函数在给予评级时确定其好坏:
def rating_function(x):
if x >= 8.0:
return "good"
else:
return "bad"现在,我们要通过此函数发送整个评分列,这是apply()的作用:
movies_df["rating_category"] = movies_df["rating"].apply(rating_function)
movies_df.head(2)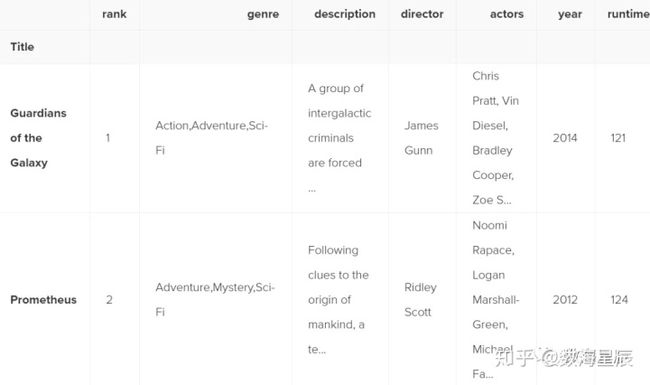
.apply()方法将rating列中的每个值都通过rating_function传递,然后返回一个新的Series。然后将此系列分配给一个新的列,称为“ rating_category”。您还可以使用匿名函数。此lambda函数可达到与rating_function相同的结果:
movies_df["rating_category"] = movies_df["rating"].apply(lambda x: 'good' if x >= 8.0 else 'bad')
movies_df.head(2)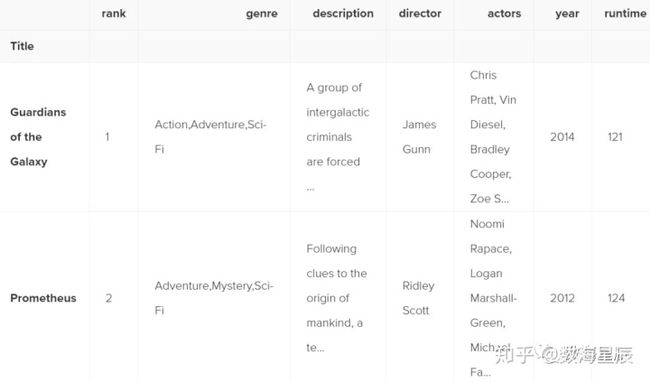
总的来说,使用apply()比手动在行上迭代要快得多,因为Pandas正在利用矢量化。
向量化:一种计算机编程样式,其中将运算应用于整个数组而不是单个元素
— Wikipedia
在自然语言处理(NLP)工作期间,大量使用了apply()是一个很好的例子。您需要将各种文本清除功能应用于字符串以为机器学习做准备。
简单作图
Pandas的另一个优点是它与Matplotlib集成在一起,因此您可以直接从DataFrames和Series中进行绘制。首先,我们需要导入Matplotlib(pip install matplotlib):
import matplotlib.pyplot as plt
plt.rcParams.update({'font.size': 20, 'figure.figsize': (10, 8)}) # set 现在我们可以开始了。绘图不会涉及很多内容,但足以轻松浏览您的数据。
绘图提示
- 对于分类变量,请使用“条形图” *和“箱线图”。
- 对于连续变量,请使用直方图,散点图,折线图和箱线图。
让我们绘制评级和收入之间的关系。我们需要做的就是在movies_df上调用.plot(),其中包含有关如何构建情节的一些信息:
movies_df.plot(kind='scatter', x='rating', y='revenue_millions', title='Revenue (millions) vs Rating');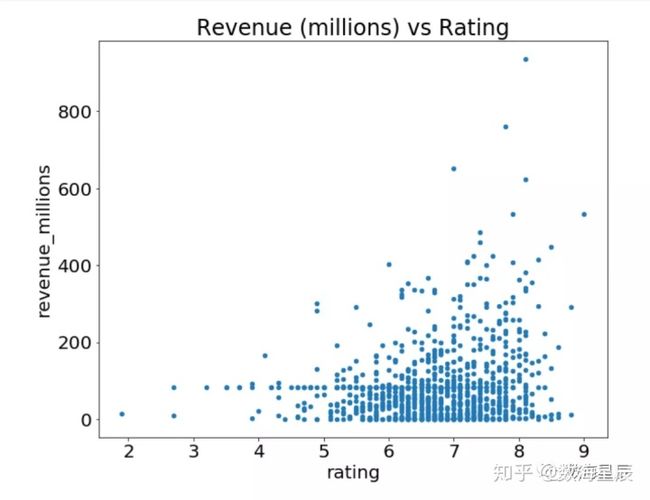
分号是什么?这不是语法错误,只是在Jupyter笔记本中进行绘图时隐藏
如果要基于单个列绘制简单的直方图,则可以在列上调用plot:
movies_df['rating'].plot(kind='hist', title='Rating');
您还记得本教程开始时的.describe()示例吗?好吧,四分位间距的图形表示称为Boxplot。让我们回想一下describe()在评级列上为我们提供的内容:
>>> movies_df['rating'].describe()
count 1000.000000
mean 6.723200
std 0.945429
min 1.900000
25% 6.200000
50% 6.800000
75% 7.400000
max 9.000000
Name: rating, dtype: float64使用箱线图,我们可以可视化此数据:
movies_df['rating'].plot(kind="box");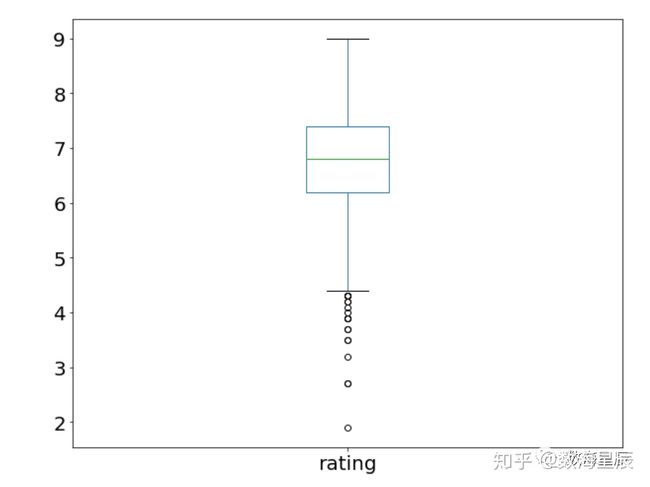
通过组合分类数据和连续数据,我们可以创建收入的箱线图,并按上面创建的评级类别进行分组:
movies_df.boxplot(column='revenue_millions', by='rating_category');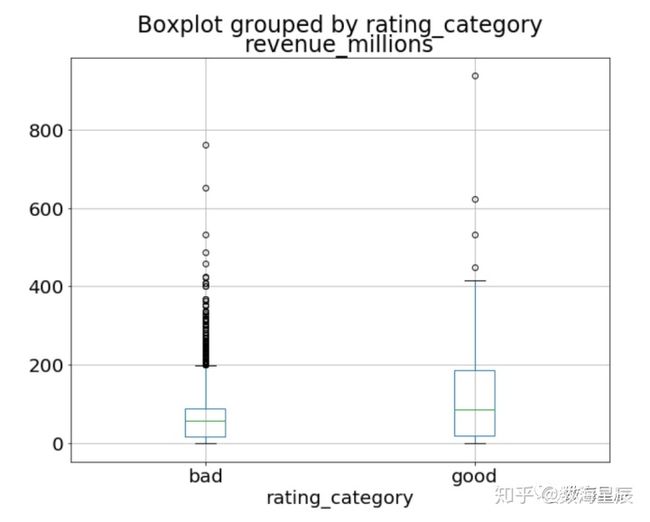
那是与Pandas一起绘图的一般想法。 有太多图要提及,因此绝对可以在这里查看plot()文档,以获取有关其功能的更多信息。
总结
在Python中使用Pandas探索,清理,转换和可视化数据是数据科学的一项基本技能。 作为数据科学家,仅清理争吵的数据是您工作的80%。 经过一些项目和一些实践之后,您应该对大多数基础知识都比较了解了。