csv 输入的第 1 行字段数有错。_Pandas数据分析库1-Pandas基础知识
文章来源:拉钩数据分析训练营
1.Padas简介
- Python在数据处理和准备⽅⾯⼀直做得很好,但在数据分析和建模⽅⾯就差⼀些。Pandas帮助填补了这⼀空⽩,使您能够在Python中执⾏整个数据分析⼯作流程,⽽不必切换到更特定于领域的语⾔,如R(R一般应用于生物领域)。
- 与出⾊的 jupyter⼯具包和其他库相结合,Python中⽤于进⾏数据分析的环境在性能、⽣产率和协作能⼒⽅⾯都是卓越的。
- Pandas是 Python 的核⼼数据分析⽀持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas是Python进⾏数据分析的必备⾼级⼯具。
- Pandas的主要数据结构是 Series(⼀维数据)与 DataFrame (⼆维数据),这两种数据结构⾜以处理⾦融、统计、社会科学、⼯程等领域⾥的⼤多数案例。
- 处理数据⼀般分为⼏个阶段:数据整理与清洗、数据分析与建模、数据可视化与制表,Pandas 是处理数据的理想⼯具。
- Pandas库安装:pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
2.Panas数据结构
Pandas是基于NumPy的升级,想要使用Pandas就必须要安装NumPy,调用时同理
import Numpy as np
import Pandas as pdpandas的数据结构常用的主要有两种:
Series(⼀维数据)与 DataFrame (⼆维数据)
当然Pandas也支持三位数据和四维数据,但是不常用,主要了解一位数据和二维数据。
2.1.Series
pd.series(data,index,dtype,name,copy)
Series是一维的数组,和NumPy数组不一样:Series多了索引
主要有以下几个参数
data:数据
index:定义行索引,参数接收值为str,如果未指定,将会生成由0开始的整形正序数值,0,1,2,3,4,5,6......,如指定,将会生成我们指定的索引,如ABCDEF...,如果指定索引的话,一定要记得和我们数据的个数要相等。
dtype:定义数据类型,参数接收值为str('int','float16','float32'.....),未指定的话会根据我们输入的数据自动识别。
name:定义系列名称(列名),参数接收值为str。
copy:复制输入数据,参数接收值为bool,默认为False。
其中我们经常设置的参数为data,index,以及dtype,
series常用创建方式有三种:
1)只输入data参数不设置索引:
l = np.array([1,2,3,6,9])
s1 = pd.Series(data = l)
display(l,s1)0array([1, 2, 3, 6, 9])
0 1
1 2
2 3
3 6
4 9
dtype: int32
2)按列表指定索引:
s2 = pd.Series(data = l,index = list('ABCDE'),name='a',dtype = 'float64',copy='False')
s2A 1.0
B 2.0
C 3.0
D 6.0
E 9.0
Name: a, dtype: float64
3)按字典键名指定索引
s3 = pd.Series(data = {
'语文':149,'数学':130,'英语':118,'文综':285,'Python':122})
s3语文 149
数学 130
英语 118
文综 285
Python 122
dtype: int64
2.2.DataFrame
pd.DataFrame(
data:数据
index: 定义行索引,参数接收值为str,如果未指定,将会生成由0开始的整形正序数值,0,1,2,3,4,5,6......,如指定,将会生成我们指定的索引,如ABCDEF...,如果指定索引的话,一定要记得和我们数据的第一维度维度尺寸要相等。
columns: 定义列索引,参数接收值为str,如果未指定,将会生成由0开始的整形正序数值,0,1,2,3,4,5,6......,如指定,将会生成我们指定的索引,如ABCDEF...,如果指定索引的话,一定要记得和我们数据的第二维度维度尺寸要相等。
dtype: 定义数据类型,参数接收值为str('int','float16','float32'.....),未指定的话会根据我们输入的数据自动识别。
copy: 复制输入数据,参数接收值为bool,默认为False。
)Series是一维的,功能比较少,DataFrame是二维的,多个Series公用索引(列名),组成了DataFrame,像 Excel一样的结构化关系型数据。
DataFrame的两种创建方式
1)列表定义列索引:
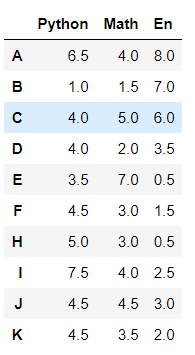
df1 = pd.DataFrame(data = np.random.randint(0,151,size = (10,3)),
index = list('ABCDEFHIJK'), # 行索引
columns=['Python','Math','En'],dtype=np.float16) # 列索引
df1
2)按字典键名指定列索引
df2 = pd.DataFrame(data = {
'Python':[66,99,128],'Math':[88,65,137],'En':[100,121,45]})
df2 # 字典,key作为列索引,不指定index默认从0开始索引,自动索引一样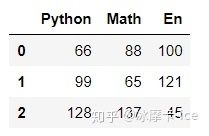
3.Pandas数据查看
常用的数据查看方法:
# 查看其属性、概览和统计信息
df.head(10) # 显示头部10⾏,默认5个
df.tail(10) # 显示末尾10⾏,默认5个
df.shape # 查看形状,⾏数和列数
df.dtypes # 查看数据类型
df.index # ⾏索引
df.columns # 列索引
df.values # 对象值,⼆维ndarray数组
df.describe() # 查看数值型列的汇总统计,计数、平均值、标准差、最⼩值、四分位数、最⼤值 http:// df.info() # 查看列索引、数据类型、⾮空计数和内存信息
import Numpy as np
import Pandas as pd
df = pd.DataFrame(data = np.random.randint(0,151,size = (100,3)),
columns=['Python','Math','En'])
df
df.shape # 查看DataFrame形状(100, 3)
df.head(n = 3) # 显示前N个,默认N = 5
df.tail(3) # 显示后n个,默认N=5
df.dtypes # 数据类型Python int32
Math int32
En int32
dtype: object
df.info() # 比较详细信息
RangeIndex: 100 entries, 0 to 99 #共有三行,行索引从0到99
Data columns (total 3 columns): #共有三列
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Python 100 non-null int32 #Python列有100个非空值,数据类型为int32
1 Math 100 non-null int32 #Math列有100个非空值,数据类型为int32
2 En 100 non-null int32 #En列有100个非空值,数据类型为int32
dtypes: int32(3)
memory usage: 1.3 KB #占用内存1.3KB
df.describe() # 描述:数据条数、平均值、标准差、中位数、四等分位值、最大值,最小值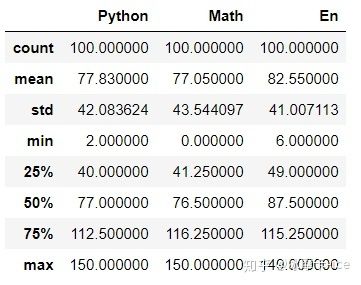
df.values # 查看值,返回的是NumPy数组array([[ 29, 7, 58],
[144, 0, 34],
[103, 113, 83],
.
.
.
[118, 29, 64],
[ 41, 46, 6],
[135, 17, 35]])
df.columns # 查看列索引Index(['Python', 'Math', 'En'], dtype='object')
df.index # 行索引 0 ~ 99RangeIndex(start=0, stop=100, step=1) #起始索引为0,终止所以为100,步长为1
4.Pandas数据输入和输出
Panda常用数据输入和输出有四种类型,csv文件、Excel文件、HDF5以及SQL读写,下面分别介绍:
4.1.CSV
import Numpy as np
import Pandas as pd
df = pd.DataFrame(data = np.random.randint(0,151,size = (100,3)),
columns=['Python','Math','En'])
df # 行索引,列索引4.1.1.csv文件写入
df.to_csv('./data.csv',#输出文件名,注意路径正确,可以用相对路径或者绝对路径
sep = ',', #分隔符,默认是逗号,也尽量用逗号
index = True, # 保存行索引,默认为True,赋值False的话,输出文件不保存行索引
header=True) # 保存列索引,默认为True,赋值False的话,输出文件不保存列索引4.1.2.csv文件加载
pd.read_csv('./data.csv', #要读取的文件名,注意路径正确,可以用相对路径或者绝对路径
index_col=0, #设置读取的行索引,默认为None,不赋值的话会自动添加一列作为行索引
header ='infer') #设置读取的列索引,默认值为'infer',不赋值的话输出会默认把第1行作为列索引展示注意:
1.index_col参数 --设置行索引
- 如果我们的文件没有行索引这一列的话,这个参数尽量不要设置,否则会把数据的第一列作为行索引;
- 而如果我们的文件有行索引这一列的话(一般在第一列),尽量设置这个参数为0,否则会把行索引作为数据的第一列,自动添加一列为行索引;
- 这个也可以赋值其他的索引(如12345..,比如这里赋值2的话,math这一列的值就会成为行索引),赋值哪个列索引,这一列的值就会变成行索引.
2.header参数 --设置列索引
- 如果我们的文件没有列索引这一列的话,一定要设置这个参数为None,否则会把数据的第一行作为列索引。
- 如果我们的文件有行索引这一列的话(一般在第一列),尽量设置这个参数或者设置为'infer',否则会生成一个从0开始的递增数列作为列索引
4.2.Excel
读写Excel之前,需要先安装两个库
读取Excel文件:pip install xlrd -i https:// pypi.tuna.tsinghua.edu.cn /simple
写入Excel文件:pip install xlwt -i https:// pypi.tuna.tsinghua.edu.cn /simple
4.2.1.写入Excel
import numpy as np
import pandas as pd
import xlrd
import xlwt
df = pd.DataFrame(data = np.random.normal(loc = 120,scale = 10, size = (100,3)),
columns=['Python','Math','En'])
df df.to_excel('./data.xls',
sheet_name='score', #sheet页的名称,默认为sheet1
na_rep='', #空值赋值,默认为空
float_format='%.2f', #小数保留位数,默认为None,例如 float_format =“%.2f”``会将0.1234格式化为0.12。
columns= ['Math','En'], #要写入的列,默认为None(全写入),比如这里我们设置了写入math 和 en,那么python就没被写入文件
header=True, #列索引(列名),默认为True,如果我们的数据给定了第一行
index=True, #是否写列索引,默认为True(列名称,控制header)
index_label=None, #设置列索引名,默认为None,如果header和index都设置为Ture,这个没必要管
startrow=4, #设置写入的数据从第几行开始写入,默认为0,比如这里设置为4,那么元数据第一行数据将出现在第5行,上边四行空出
startcol=2, #设置写入的数据从第几列开始写入,默认为0,比如这里设置为2,那么元数据第一行数据将出现在第3列,左边2列空出
freeze_panes=(5,3)) #设置冻结的行和列,默认为None,比如这里我们设置的5,3,就是冻结前5行和前3列,对应上边的4,2,以上即为常用的几个写入Excel方法to_excel的参数,我们一般写入文件的时候就写一个文件名就可以,不用设置这么多的参数。
上边的代码执行完毕写入的数据是这样的:

4.2.2.读取Excel
pd.read_excel('./新建 XLS 工作表.xls',
sheet_name=0,#要查看的sheet页,默认为0,就是第一个sheet
#默认为0:读取第一个sheet
#1:读取第二个sheet
#"Sheet1":加载名称为“ Sheet1”的工作表
#[0,1,"Sheet5"]:加载第一张,第二张和名为“ Sheet5”的sheet
#无:所有工作表。
header=0,#第0行作为列标题,默认为0,如果文件不包含标题行,那么应该赋值header = None。
index_col=0,# 第0列作为行索引,如果文件不包含行索引列,应设置为None
skiprows=[1,2,3,4,5,6,7,8,9,10],#要跳过的行,这里是从Excel第12行开始读的,因为标题占了一行
nrows=10,#要展示的行数,这里读取了10行
usecols=[0,1,2,3,4,5,6,7]) #这里读取了1234567列
#要读取的列,默认为None
#如果为None,则解析所有列。
#如果为str,则表示Excel列字母的逗号分隔列表,如['订单ID','销售额']
#如果为int列表,则表示要解析的列号列表,如[1,7]上边的代码执行完毕读取的数据是这样的:
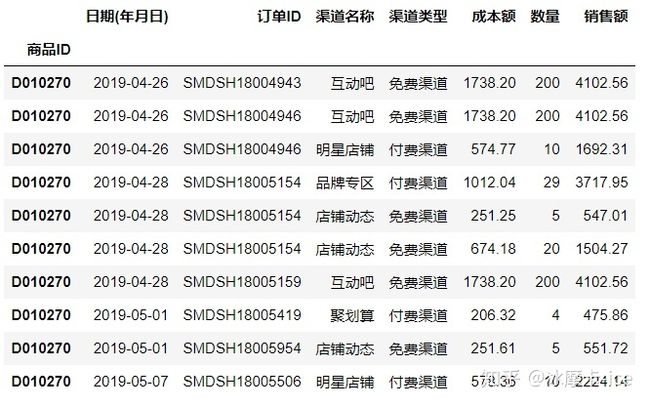
4.3.HDF5
读写HDF5之前,需要先安装包:
pip install tables -i https:// pypi.tuna.tsinghua.edu.cn /simple
HDF5是⼀个独特的技术套件,可以管理⾮常⼤和复杂的数据收集。
HDF5,可以存储不同类型数据的⽂件格式,后缀通常是.h5,它的结构是层次性的。
⼀个HDF5⽂件可以被看作是⼀个组包含了各类不同的数据集。
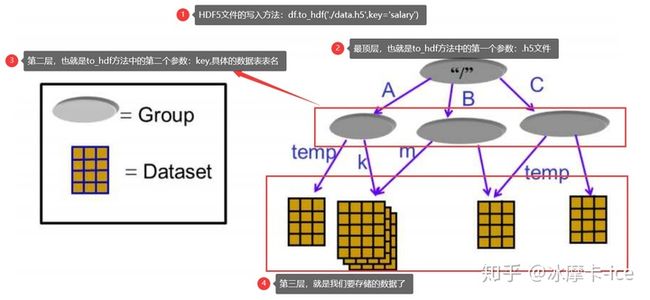
对于HDF5⽂件中的数据存储,有两个核⼼概念:group 和 dataset
dataset 代表数据集,⼀个⽂件当中可以存放不同种类的数据集,这些数据集如何管理,就⽤到了group
最直观的理解,可以参考我们的⽂件管理系统,不同的⽂件位于不同的⽬录下。
⽬录就是HDF5中的group, 描述了数据集dataset的分类信息,通过group 有效的将多种dataset 进⾏管
理和区分;⽂件就是HDF5中的dataset, 表示的是具体的数据。
4.3.1.写入HDF5文件
import numpy as np
import pandas as pd
import tables
df2 = pd.DataFrame(data = np.random.randint(6,100,size = (1000,5)),
columns=['计算机','化工','生物','工程','教育'])
#HDF5文件写入的常用参数设置
df2.to_hdf('./data.h5', #定义HDF5文件名
key = 'salary', #定义键值,也就是我们写入数据的表名
mode = 'a',
#写入的模式,默认为a,a为追加写入,文件可以不存在,w为覆盖写入,如文件已存在会覆盖原文件,r+w也为追加写入,但是文件必须已存在。
index = True,#是否要存行索引,默认是True
format = 'table',
#设置此文件读取的方式,默认为fixed,此模式下不能读取指定列,如果要设置可以单独读取指定列的模式,需要设置为table
complevel = None,
#文件压缩级别,值为0~9,压缩级别越大,文件被压缩的越小,但相应的用时也会变长,默认为None不压缩。
complib = None,#指定要是用的压缩库,默认为None,complevel设置为非None时才可用。
encoding = 'UTF-8') #写入数据的编码,默认为UTF-84.3.2.读取HDF5文件
#HDF5文件读取的常用参数设置
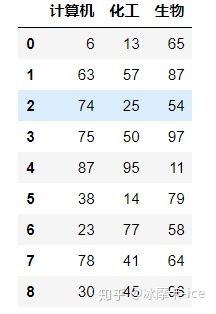
pd.read_hdf('./data.h5', #要读取的HDF5文件名
key = 'salary', #要读取的group(表名)
start = 0,#读取数据的起始行,默认为None从第一行开始,int从0开始,包括索引本身这一行
stop = 9,#读取数据的结束行,默认为None读取到最后,int从0开始,不包括索引本身这一行
columns=['计算机','化工','生物'])
#读取数据的列,默认为None全部读取,list,此参数依赖于文件写入时format参数的设置,如果format参数设置为fixed或者默认,则不能按列表读取,columns只能设置为None或者默认不设置,如要按列表读取,写入时format参数需要设置为table读取结果为:
4.4.SQL
写SQL之前,需要安装两个库
pip install sqlalchemy -i https:// pypi.tuna.tsinghua.edu.cn /simple
pip install pymysql -i https:// pypi.tuna.tsinghua.edu.cn /simp
其中SQLAlchemy是Python编程语⾔下的⼀款开源软件。提供了SQL⼯具包及对象关系映射(ORM)⼯具,可以理解为数据库引擎,
pymysql则是python中类似于mysql的一个包。
数据库的配置,可以查看:https://docs.sqlalchemy.org/en/13/core/engines.html
其中mysql数据库的常见连接方式有三种,常用最后一种连接方式:
#依赖于sqlalchemy,需要先导入sqlalchemy再执行数据库连接操作
from sqlalchemy import create_engine
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysqlclient (a maintained fork of MySQL-Python)
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# PyMySQL
engine = create_engine('mysql+pymysql://scott:tiger@localhost/foo')读写SQL之前的操作:
from sqlalchemy import create_engine # 数据库引擎,构建和数据库的连接
from sqlalchemy.types import Date, String, Float, Numeric, Text,NVARCHAR,Integer
#导入sqlalchemy的数据类型库sqlalchemy.types,具体所有数据类型可查看http://codingdict.com/sources/py/sqlalchemy.types.html。
import numpy as np
import pandas as pd
# PyMySQL
# 连接之前一定要确定已经安装了mysql,且IP地址和密码正确,数据库,用户是存在的,其他参数也要配置正确。
engine = create_engine('mysql+pymysql://root:root@localhost/lagou?charset=utf8')
#参数解析:mysql+pymysql不要动,root用户名,12345678密码,localhost服务器地址IP,lagou数据库名,?后边跟要设置的参数,charset=utf8数据库的编码。基本上和配置mysql数据库是一样的。4.4.1.将数据写入MySQL数据库
df2 = pd.DataFrame(data = np.random.randint(6,100,size = (1000,5)),
columns=['计算机','化工','生物','工程','教育'])#定义每一列的数据类型,并给一个变量dtypedict供下一步写入数据时dtype参数调用。
dtypedict = {
'计算机': Integer,
'化工': Integer,
'生物': Integer,
'工程': Integer,
'教育': Integer}
# 将Python中数据DataFrame保存到Mysql
df2.to_sql('salary', #定义要写入数据库的数据的表名
engine, #把数据库连接写入,就是上边定义的那个连接
index=True, #将行索引作为一列写入数据库中,默认设置为False
index_label='行号',#当index为True的时候,定义行索引列的列名
if_exists = 'replace',
#如果表已存在,如何处理,默认为fail报错,可设为replace:替换原表数据,append:在原表数据后追加写入。
chunksize=10,
#指定每批次写入的行数,默认为None一次性写入,int类型,这个是设置每一批写入多少行,不是一共写入多少行,不论设置多少都是会全写入的
dtype= dtypedict) #设置每一列的数据类型,默认为None,如果设置为None的话,会由系统自动识别,这可能造成资源的浪费。4.4.2.读取MySQL数据库中的数据
#pd.read_sql()即可读取,但是如果我们想要使用读取的数据的话,最好给一个变量接收数据
df3 = pd.read_sql(
'with p as (select * from salary) select *,rank()over(order by 教育+计算机+化工+生物+工程 desc) as 排名 from p limit 10',
#直接写sql即可,用引号括起来,看MySQL的版本,我的是8.0,开窗函数和with字句都可用。
con = engine)#调用的数据库链接
df3 #展示读取的数据读取的数据为:

5.Pandas数据选取
5.1.获取数据
#数据准备
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0,151,size = (10,3)),
index=list('ABCDEFHIJK'),columns=['Python','Math','En'])
df5.1.1.获取单列数据
#列索引方式获取
df['Python'] # 获取数据Series
#对象方式获取
df.Python # 属性,DataFrame中列索引,表示属性5.1.2.获取多列数据
df[['Python','En']] # 获取多列数据5.2.标签选取数据
标签选取,就是按照索引标签选取,调用方法为.loc,即location。
df.loc['A'] #选取行索引标签为A的单行数据Python 0
Math 29
En 113
Name: A, dtype: int32
df.loc[['A','F','K']] #选取多行数据,注意是两个中括号,查询出的数据是一个二维表格
df.loc['A','Python'] #选取行索引标签为A,列索引标签为python的单个数据0
df.loc[['A','C','F'],'Python'] #选取行索引标签为A、C、F,列索引标签为python的单列数据A 0
C 137
F 3
Name: Python, dtype: int32
df.loc['A'::2,['Math','En']] #选取行索引标签以A为起点直到结尾,步长为2,列索引标签为math和en的数据
df.loc['A':'D',:] #选取行索引标签由A起始到D结束,列索引标签为所有的数据
可见,按标签选取数据和之前学的numpy以及python的索引和切片方式是一样的,只不过要注意什么时候用双中括号,什么时候用单中括号,且按照标签选取是左闭右闭的,选取的数据包括结束的那个标签。
5.3.位置选取数据
位置选取类似于标签选取,但是用的是标签所对应的实际索引,行列索引都是从0开始,这时候的选取是左闭右开的,不包括切片结尾的索引数据
数据准备:
import pandas as pd
import numpy as np
df = pd.DataFrame(data = np.random.randint(0,150,size = [10,3]),# 计算机科⽬的考试
成绩
index = list('ABCDEFGHIJ'),# ⾏标签
columns=['Python','Tensorflow','Keras'])
df.iloc[4] # ⽤整数位置选择,选择行索引为4的数据
df.iloc[2:8,0:2] # ⽤整数切⽚,类似NumPy,选取行索引为2到7,列索引为0到1的数据
df.iloc[[1,3,5],[0,2,1]] # 整数列表按位置切⽚,选取行索引为1,3,5,列索引为0,1,2的数据
df.iloc[1:3,:] # ⾏切⽚,选取行索引为1和2,列索引为所有的数据
df.iloc[:,:2] # 列切⽚,选取行索引为所有,列索引为0和1的数据
df.iloc[0,2] # 选取标量值,选取行索引为0,列索引为2的数据5.4.布尔索引(条件选取)
布尔索引,简单来说是我们先设置一个条件,这个条件输出的是布尔值True和False,然后我们用类似于numpy的花式索引的方式选取的方式调用条件,来达到按条件选取数据的目的,具体操作如下:
准备数据
import pandas as pd
import numpy as np
df = pd.DataFrame(data = np.random.randint(0,150,size = [10,3]),# 计算机科⽬的考试
成绩
index = list('ABCDEFGHIJ'),# ⾏标签,⽤户
columns=['Python','Tensorflow','Keras']) # 考试科⽬
#我们先设置一个布尔索引,
df.Python > 80输出值为:
A True
B False
C False
D False
E False
F True
G False
H True
I True
J False
Name: Python, dtype: bool
接下来我们调用这个条件
cond = df.Python > 80 # 将Python大于80分的成绩获取
df[cond]
由结果可见,用布尔索引的方式,达到了按条件选取数据的目的,当然,也可以用与条件和或条件等复杂逻辑运算来做更进一步的筛选:
cond = (df.Python > 70) & (df.Tensorflow > 70) #与条件查询,使用&,选取python成绩和Tensorflow成绩同时大于70的数据
df[cond]
cond = (df.Python > 70) | (df.Tensorflow > 70) #或条件查询,使用|,选取python成绩或Tensorflow成绩大于70的数据
df[cond]也可以使用聚合函数来进行条件选取:
cond = df.mean(axis = 1) > 75 # 选取平均分大于75(axis=1,按行聚合),优秀,筛选出来
df[cond]那么如果想选取与条件相反的数据呢,就在条件前面加上~即可
df[~cond]如果想选取在我们所列出的数组中的数据,可以用isin函数:
cond = df.index.isin(['C','E','H','K']) # 判断数据是否在数组中
df[cond] # 删选出来了符合条件的数据isin 同样也可以使用~来选取不存在数组中的函数,用法同上。
5.5.赋值操作
df['Python']['A'] = 150 # 修改某个位置的值
df
df['Java'] = np.random.randint(0,151,size = 10) # 新增加一列
df
df.loc[['C','D','E'],'Math'] = 147 # 修改多个人的成绩
df
cond = df < 60
df[cond] = 60 # where 条件操作,符合这条件值,修改,不符合,不改变
df
df.iloc[3::3,[0,2]] += 100 #给对应位置的数据增加100
df6.数据集成
数据准备
# np.concatenate NumPy数据集成
df1 = pd.DataFrame(np.random.randint(0,151,size = (10,3)),
columns=['Python','Math','En'],
index = list('ABCDEFHIJK'))
df2 = pd.DataFrame(np.random.randint(0,151,size = (10,3)),
columns = ['Python','Math','En'],
index = list('QWRTUYOPLM'))
df3 = pd.DataFrame(np.random.randint(0,151,size = (10,2)),
columns=['Java','Chinese'],index = list('ABCDEFHIJK'))6.1.concat数据合并
6.1.1.行合并,竖直方向增加
pd.concat([df1,df2],axis = 0)
# axis = 0变是行合并,行增加,注意进行合并的时候,列索引要一致,否则会出现类似SQL中outer join关联不上的出现None值的情况行合并还可以用append的方式
df1.append(df2) # append追加,在行后面直接进行追加,同时也要注意列索引一致6.1.2.列合并,水平方向增加
pd.concat([df1,df3],axis = 1)
# axis = 1表示列增加,注意进行合并的时候,行索引要一致,否则会出现类似SQL中outer join关联不上的出现None值的情况6.2.insert数据插入
df1.insert(loc = 1, # 插入位置,插入为列索引为1的位置
column='C++', # 插入一列,这一列名字
value = np.random.randint(0,151,size = 10)) # 插入的值insert只能插入列,不能插入行,插入行用append
dfn = pd.DataFrame(np.random.randint(0,151,size = (1,4)),columns=['Python','C++','Math','En'],index= list('X'))
dfn
df1.append(dfn) # 插入的值6.3.merge 合并
merge合并的效果类似于SQL中的表连接,具体使用方法如下:
准备数据:
import numpy as np
import pandas as pd
df1 = pd.DataFrame(data = {
'name':['softpo','Brandon','Ella','Daniel','张三'],
'height':[175,180,169,177,168]}) # 身高
df2 = pd.DataFrame(data = {
'name':['softpo','Brandon','Ella','Daniel','李四'],
'weight':[70,65,74,63,88]}) # 体重
df3 = pd.DataFrame(data = {
'名字':['softpo','Brandon','Ella','Daniel','张三'],
'salary':np.random.randint(20,100,size = 5)}) # 薪水
#注意df1和df2的索引4键值不一样,df3和df1的第一个键(列名不一样)
display(df1,df2,df3)上边用concat的列合并,是直接在水平方向上叠加,并不考虑连接的值是否相等的问题,比如
pd.concat([df1,df2],axis = 1)得出来的数据是将两个Dataframe横向叠加了

这时候如果想要实现像MySQL的表连接一样的效果,就需要用到merge方法:
# 根据共同的属性,合并数据
# df1 和 df2 全外连接,共同属性:name
pd.merge(df1, #要合并的左表
df2, #要合并的右表
how = 'outer',#合并的方式:inner-内连接,outer--全外连接,left--左外连接,right--右外连接,外连接的时候,没有数据的地方会填充为NaN,默认为inner。
on=None,
#默认为None,合并的根据,要写出两个DataFrame共有的列,注意一定要是列名相同的,否则会报错,为list类型(多个列)或str(一列)
#如:['name']或者'name',默认None的时候,merge会自动寻找相同列名的列。
left_on=None,
right_on=None,
#当两表连接的根据列名字不一样的时候,用left on和right on列出两表连接的根据列,数值类型和on一样,默认None,比如df1和df3合并就需要用到left_on = 'name',right_on = '名字'。
left_index = False,
right_index = False,
#当进行连接的两表没有共同的根据列的时候,可以使用行索引进行合并,将left_index和right_index都设置为True即可,默认为False
sort = True) #根据连接用的列进行排序,默认为False
#df1和df3内连接,共有属性:name和名字,但是两个列索引的索引名不一样,所以要用到left_on和right_on
pd.merge(df1,df3,left_on='name',right_on='名字')
df4 = pd.DataFrame(data = np.random.randint(0,151,size = (10,3)),
columns=['Python','Math','En'],index = list('ABCDEFHIJK'))
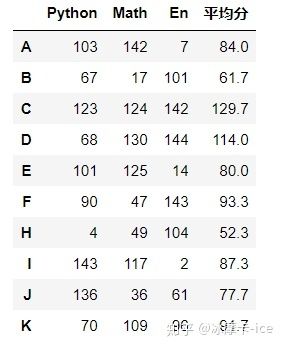
#将df4求出平均值,数据结构是一列十行
score_mean = df4.mean(axis = 1).round(1)
#给score_mean设置一个名字,否则执行下一步时会报错
score_mean.name = '平均分'
#将df4和score_mean根据行索引合并,这时两个df不必有共同的列,直接按照行索引连接即可,其实也可以理解成两个df以行索引为根据列合并
pd.merge(df4,score_mean,
left_index=True, # 数据合并根据行索引,对应
right_index=True) # 右边数据根据行索引,对应
7.数据清洗
准备数据:
df = pd.DataFrame(data = {
'color':['red','blue','red','green','green','blue',None,np.NaN,'green'],
'price':[20,15,20,18,18,22,30,30,22]})
df7.1.重复数据删除:drop_duplicates
# 重复数据删除
df.drop_duplicates() # 非重复数据,None和NaN都表示空值,且price列值也相等,所以算作重复数据drop_duplicates的参数:一个不写全按照默认值处理 1. subset: 列标签或标签序列,可选仅考虑某些列来标识重复项,默认使用所有列 2. keep:确定要保留的重复项(如果有),默认为first
- ‘first’:保留第一次出现的重复项,其余全删除。
- ’last‘:保留最后一次出现的重复项,其余全删除。
- False:删除所有重复项,一个也不留。
注意first和last是str,要加引号,False不用加。
3.inplace: 是否改变原变量数据,默认为False,如果设置为Ture将会改变原变量,慎用。 4.ignore_index: 是否为结果重新编排新的行索引,默认为False,设置为True的话,返回的结果行索引为从0开始重新递增的新行索引,比如默认返回的数据行索引是0,3,5,6,8,10,设置为True的话返回的结果的行索引就会变成0,1,2,3,4,5。
7.2.空数据过滤:dropna
构造数据:
from numpy import nan as NA
dfa = pd.DataFrame (np.random .randn(8,7))
dfa.iloc[0,:] = NA
dfa.iloc[1,:6] = NA
dfa.iloc[2,:5] = NA
dfa.iloc[3,:4] = NA
dfa.iloc[4,:3] = NA
dfa.iloc[5,:2] = NA
dfa.iloc[6,0] = NA
dfa
dfa.dropna() # 空数据过滤,参数未进行设置,全部按照默认值来处理
dropna参数解析: 1) axis=0, 确定要删除的是包含空值的行还是列,默认是0即行,1为列 2) how='any', 确认要删除这一行或这一列需要满足的条件,默认为any,只要有一个空值就删除,all要这一行或这一列都为空值才删除 thresh=None, 此行或者此列非空值的个数要大于等于int的情况下才保留这一行或这一列,默认为None,比如上表
- 当thresh=None或者不写时,默认只要有空值就删除这一行,那么最后剩下行索引为7的这一行
- 当thresh=0时,保留所有行,因为所有行的非空值个数都大于等于0个
- 当thresh=1时,去掉第1行,因为其他行的非空值个数都大于等于1个
- 当thresh=2时,去掉前2行,因为其他行的非空值个数都大于等于2个
- 当thresh=3时,去掉前3行,因为其他行的非空值个数都大于等于3个
- 当thresh=4时,去掉前4行,因为其他行的非空值个数都大于等于4个
- 当thresh=5时,去掉前5行,因为只有最后三行的非空值个数都大于等于5个
- 当thresh=6时,去掉前6行,因为只有最后两行的非空值个数都大于等于6个
- 当thresh=7时,去掉前7行,因为只有最后一行的非空值个数都大于等于7个
- 当thresh=8或以上时,去掉所有行,因为只有七列,不可能存在有8个非空值的行
3)subset=None, 只删除指定列中含有缺失值的行,sunset 的值要为数组或者none
dfa.dropna(subset=np.array([3])) #这里就是只删除了列索引3中含有空值的行
4)inplace=False,是否改变原变量数据,默认为False,如果设置为Ture将会改变原变量,慎用。
7.3.删除指定的行或列:labels
数据准备:
midx = pd.MultiIndex(levels=[['lama', 'cow', 'falcon'],
['speed', 'weight', 'length']],
codes=[[0, 0, 0, 1, 1, 1, 2, 2, 2],
[0, 1, 2, 0, 1, 2, 0, 1, 2]])
dfb = pd.DataFrame(index=midx, columns=['big', 'small'],
data=[[45, 30], [200, 100], [1.5, 1], [30, 20],
[250, 150], [1.5, 0.8], [320, 250],
[1, 0.8], [0.3,0.2]])
dfb
dfb.drop(index='length', level=1)#删除二级行索引为length的行
dfb.drop(labels=['big'],axis=1)#删除列索引为big的列drop参数解析:
1) labels=None,确定要删除的项目,可以是行列索引(0,1,2,3..)也可也是行列的标签,删除单个的时候可以是str/int或者list,删除多个的时候必须是一个列表['big','small','mid']...。 2) axis=0,确定要删除的是列还是行,0为行,1为列,默认0. 3) index=None,相当于axis=0,默认为None 4) columns=None,相当于axis=1,默认为None 5) level=None,当索引为多重索引的时候,删除指定级别的对应索引行数据,默认为None。
比如此例中,行为2重索引,那么我们在删除行索引标签为length的行时候,要制定level=1,因为length的索引级别在第二级别,否则会报错;而当索引不是多重索引不要设置level的值或者设置None,否则也会报错。 6) inplace=False,是否改变原变量数据,默认为False,如果设置为Ture将会改变原变量,慎用。
7.4.保留筛选--filter
数据准备:
df = pd.DataFrame(data = {
'color':['red','blue','red','green','green','blue',None,np.NaN,'green'],'price':[20,15,20,18,18,22,30,30,22]})
df#items,精确匹配
df.filter(items=['price']) # 保留列标签为price的数据
df.filter(items=[0,1,2,3],axis = 0) #保留行索引为0,1,2,3的所有行
#like
df.filter(like = 'i') # 模糊匹配,保留了列标签中带有i这个字母的所有列
# 正则表达式,方式很多,用到可以再查
df.filter(regex = 'e$') # 保留列标签是以e结尾的所有列filter参数解析: items:精确匹配,保留标签/索引为列表中所列的值的行或者列,items的值为列表,默认为None。 like:模糊匹配,保留了标签/索引含有所列字符串内字符的行或者列,like的值为str,默认为None。 regex:正则匹配,默认为None。 axis:确定要进行筛选的是行还是列,0为行,1为列,注意这里和之前不同的是, filter的axis参数默认值是1。
7.5.异常值过滤
数据准备:
a = np.random.randint(0,1000,size = 200)
cond = (a <=800) & (a >=100) # 定义异常值:大于800,小于100。
a[cond] #调用过滤条件
# 定义一个平均值是0,标准差是1的正态分布数组。
b = np.random.randn(100000)
# 正态分布中,有个3σ定律,即绝对值为标准差3倍即以上的值为异常值,所以可以使用这个定律过滤呈正态分布的数据中的异常值
cond = np.abs(b) > 3*1 # 定义异常值:绝对值大于3σ
b[cond] #调用过滤条件8.数据转换
数据准备:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,10,size = (10,3)),
columns=['Python','Tensorflow','Keras'],
index = list('ABCDEFHIJK'))8.1.索引标签的替换--rename
df.rename(index = {
'A':'X','K':'Y'}, # 行索引
columns={
'Python':'人工智能'}, # 列索引修改
) rename参数解析 mapper=None,定义要修改的值,mapper值为字典,冒号前为要修改的值,冒号后为要改为的值,与axis配合使用,默认为None。 axis=None,定义要修改行还是列,与mapper配合使用,默认为None。 index=None,定义要修改的值,修改行索引,mapper值为字典,冒号前为要修改的值,冒号后为要改为的值,默认为None。 columns=None,定义要修改的值,修改列索引,mapper值为字典,冒号前为要修改的值,冒号后为要改为的值,默认为None。
一般常用的是index和columns,mapper和axis不常用。 inplace=False,是否改变原变量数据,默认为False,如果设置为Ture将会改变原变量,慎用。 level=None,当索引为多重索引的时候,修改指定级别的对应的索引标签,默认为None。
8.2.数据的替换
8.2.1.replace
#非指定列一对一替换
df.replace(5,50)
#非指定列多对一替换
df.replace([2,7],1024)
#非指定列多对多替换
df.replace([2,7],[10,24])
#指定列一对一替换
df.replace({
'Tensorflow':1024},-1024) # 指定某一列,进行数据替换
#指定列多对一替换
df.replace({
'Tensorflow':[8,6]},100) # 指定某一列,进行数据替换
#指定列多对多替换
df.replace({
'Tensorflow':[8,6]},{
'Tensorflow':[100,240]}) # 指定某一列,进行数据替换replace参数解析(常用): to_replace=None,要修改的值,值类型可以是int,float,列表,字段等 value=None,要改为的值,值类型可以是int,float,列表,字段等 注意多对多修改to_replace和value值的个数要相等。 inplace=False,是否改变原变量数据,默认为False,如果设置为Ture将会改变原变量,慎用。
8.2.2.map映射元素转变
map 只能针对一列,就是Series,map是起到映射的作用,即把df的值传递给它里边的参数,map既可以是序列,也可以是函数
# 有一些没有对应,那么返回就是空数据
df['人工智能'].map({
1024:3.14,2048:2.718,6:1108}) # 跟据字典对数据进行改变X NaN
B NaN
C 3.140
D 3.140
E 2.718
F NaN
H 1108.000
I 3.140
J NaN
Y 2.718
Name: 人工智能, dtype: float64
df['Keras'].map(lambda x :True if x > 0 else False) # 如果大于 0 返回True,不然返回FalseX True
B True
C True
D True
E True
F True
H True
I True
J True
Y True
Name: Keras, dtype: bool
def convert(x):
if x >= 1024:
return True
else:
return False
df['level'] = df['Tensorflow'].map(convert) # map映射,映射是Tensorflow中这一列中每一个数据,传递到方法中
df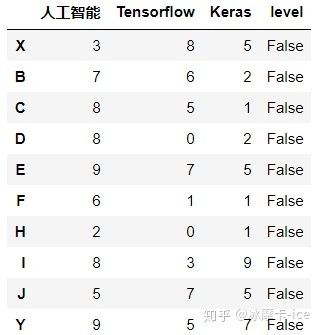
8.2.3.apply、applymap、transform映射元素转变
apply既可以操作Series又可以操作DataFrame
apply是起到映射的作用,即把df的值传递给它里边的参数,apply既可以是序列,也可以是函数
当apply操作的是一列的时候,用法和效果是和map一样的,是一个Series
df['人工智能'].apply(lambda x : x + 100) #给人工智能这一列的所有值都+100
df['level'].apply(lambda x:1 if x else 0) #level如果为Ture返回1,False返回0当apply操作的是多列的时候,返回的结果是个DataFrame
# 定义一个函数,返回中位数,奇数,最小值,最大值和标准差。
def convert(x):
return pd.Series([x.median(),x.count(),x.min(),x.max(),x.std()],
index = ('中位数','计数','最小值','最大值','标准差'))df.apply(convert).round(1) # axis默认值是0,是对每列所有行的值进行统计
df.apply(convert,axis = 1).round(2) # axis = 1,是对每行所有列的值进行统计
df['Tensorflow'].apply([np.sqrt,np.square,np.cumsum]) # 针对一列,进行不同的操作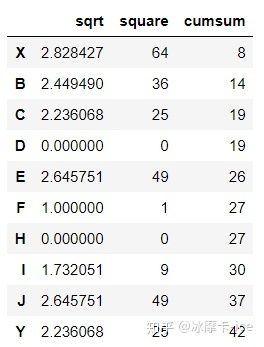
def convert(x):
if x > 5:
return True
else:
return False
df.apply({
'人工智能':np.cumsum,'Tensorflow':np.square,'Keras':convert}) # 对不同的列,执行不同的操作
针对单列和多列的计算,applay和transform的用法和效果是一样的,但是transform不能对整体进行操作,也就是说使用transform时必须要指定对哪一列或者那几列进行什么样的操作,关于applay和transform的具体异同点,可查看下方链接
applay和transform的异同点: https://www. jb51.net/article/149789 .htm
而applymap是对DataFrame中的所有元素进行操作,不能聚合,只能逐个操作,关于apply和applymap的具体区别可查看以下链接
pandas中的map()、apply()、applymap()函数的区别: https://www. cnblogs.com/jason--/p/1 1427145.html
def abc(n):
return n+1
df.applymap(abc)8.2.4.打乱随机抽样和哑变量
1)打乱随机抽样
有时候需要从大量数据中随机抽样,但是按顺序选难免没有参考性,这时候就可以使用permutation和take的组合进行重排打乱选取样本数据:
# 重排,索引打乱
df1 = df.take(np.random.permutation(8)) #取原Dataframe的数据,打乱顺序,
df1[3:7] #从被打乱顺序的数据中取出一部分值
# 将原有的少量数据进行增量打乱重排
df.take(np.random.randint(0,10,size = 20)) # 随机抽样20个数据2)哑变量
df2 = pd.DataFrame(data = {
'数值':['a','b','a','b','c','b','c','我是谁']})
df2
# one-hot,哑变量,返回结果会显示原表中的数据在哪行出现了和没出现,出现标1,没出现标0
# str类型数据,经过哑变量变换可以使用数字表示
pd.get_dummies(df2,prefix='',prefix_sep='') # 1表示,有;0表示,没有
#prefix不进行定义的话会默认使用原DataFrame的列标签,prefix_sep不写的话会默认加一个_,get_dummies的结果列标签会变成 数值_a 数值_b 数值_c 数值_我是谁,把这两个参数都设置为''的话返回的列标签就会变成 a ,b,c,我是谁
9.数据重塑(行列转换)
前面在numpy说到过行列转置,行列转置是直接将行列的位置调换,但是时对行列的整体进行转置,在遇到多层索引的时候,不能对某一层索引进行单独的行列转置,这时候就用到了pandas的行列转置操作。
df2 = pd.DataFrame(np.random.randint(0,10,size = (20,3)),
columns=['Python','Math','En'],
index = pd.MultiIndex.from_product([list('ABCDEFHIJK'),['期中','期末']])) # 多层索引
df2
由图可见,行索引是分两级的,这时候如果想对行索引进行单级别的行列转换,就需要用到unstack函数:
df2.T #Numpy的行列转换效果
df2.unstack(level = -1, #索引级别指定,0表示第一级索引,-1则表示最后一级索引,默认值为-1
fill_value=0) # 当出现空值的时候,用0替代,fill_value默认值为None,不处理,就还为None
有行转列就有列转行,列转行要用到的函数是stack
df2.stack(level=0, #索引级别指定,0表示第一级索引,-1则表示最后一级索引,默认值为-1。
dropna=True) # 当出现空值的时候是否去掉,默认为False保留,True为去掉。
#因为原DF只有一级列索引,所以转化之后DF会变成Series,所以我们加一个转换,把Series转换回DF
df3 = pd.DataFrame(df2.stack(level=0,dropna=True),columns=['考试成绩'])
df3
数据大概就是上图这样。
行列转换还可以套着用:
df2.unstack().stack(level = 0)
这样就把原来的二级行索引变成了列索引,列索引变成了二级行索引。
行列转换还可以配合聚合函数使用,直接计算某一级索引的聚合值:
df2.mean(level=1,axis = 0) # 计算2级行索引级别的平均值
df2.mean(level=0,axis = 0) # 计算1级行索引级别的平均值