如何产生高斯带限白噪声数据_讲座总结 | 概率图模型在fMRI数据分析中的应用...
来自东京大学的Mingbo Cai教授在neurochat(神聊)2020华人心理学与脑科学线上会议中,介绍了incorporating structured assumptions with probabilistic graphical models in fMRI data analysis文章里概率图模型在fMRI数据分析中的应用。在此感谢这篇综述中其他作者的贡献。
fMRI分析中的挑战:
首先数据的维度很高,人脑会有几万个像素点,而样本量很小,一个被试只能得到几百到几千个采样点。 其次人脑与人脑之间的结构是具有很大差异的,不同人脑中的体素起到的作用可能是不一样的。 fMRI中的噪声也不小,这也进一步增加了分析数据的难度。如何应对这些挑战?——概率图模型(PGM)
概率图模型可以通过图的方式来描述我们感兴趣的变量和我们所得到数据之间的概率关系。 图中的节点可以用来 表示变量或数据,节点之间的箭头连接表示着两者之间的因果关系。 图中A到B的箭头( p(B|A ))就表示假设A取某个值,B变量的分布情况。 当建立完这个模型后,我们可以用数据Y来反 推计算我们所感兴趣的变量A(即A的取值为多少时,可以更好地解释数据)。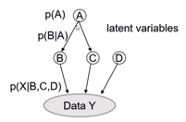
如何使用概率图模型:
第一步:明确问题。
第二步:做假设,计算所关注的变量和数据之间的关系。
第三步:将得到的关系转化为概率图模型。
第四步:通过反推计算所关注的变量最可能的值为多少。

下面将介绍五个领域中概率图模型在fMRI数据分析中的应用:
1
Discovering latent neural dynamics for natural tasks
研究目标:1.不同的人在完成相同任务中脑活动相似的地方。2.如何整合不同人脑的数据。
在观看同一部电影或聆听同一首音乐的时候,人们会在相似的时间做出类似的反应。当然音乐家和普通人对于同样的音乐也会有不同的反应。基于此,Chen等人提出了Shared Response Model(SRM)模型[2]。
因为所有的被试会在任务中的相同时间产生相同的刺激,所以我们假设所有的被试共享相同的低维度的隐含表征(称作shared response),另一方面每个被试之间会有各自特有的空间特征用于根据shared response生成所观测到的fMRI数据。

如上图SRM模型所示,左侧每一个蓝色矩阵Xm(Vm×T)表示每一个被试的脑成像数据,可以看作是右侧两个低维矩阵的乘积。其中橙色的矩阵S(K×T)表示不同的被试所共有特征的低维隐含表征信号,每一个灰色矩阵Wm(Vm×K)表示每一个被试所特有的空间响应特有的模式。之后将被试的数据重新映射回低维的空间之中,这样便可以完成两个目的。第一将数据降维,只需在低维的空间中分析数据。第二可以将不同的被试都在这个空间中进行分析,提高数据的样本量。维度越低,样本量越多,这样可以在训练集中获得更高的精度(例如使用三个被试的数据来预测第四个被试)。不仅可以用来分析不同被试之间共同的神经响应,这个方法还可以分析每个被试特有的神经活动。
这样的SRM概率图模型另一个优点就是扩展性好,例如Searchlight SRM[3],Multi-dataset multi-subject analysis[4],Semi-supervised SRM[5],Matrix-normal SRM[6]。2
Discovering full-brain functional connectivity
传统方法是用结构成像来划分脑区,来看脑区之间神经信号的相关性。这样的缺点显而易见,大脑的结构组织和功能组织并不一定完全一样,另外脑区之间也会有一定的重叠。Manning提出了Topographic Factor Analysis(TFA)[7],假设为在任一时刻所观测到的fMRI pattern是由若干个基本的pattern线性叠加所组成,每一个pattern对应空间中的一个脑区。
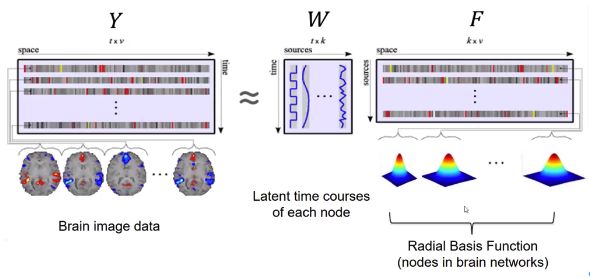
如上图TFA模型所示,Y矩阵(T×V)表示不同时刻各个voxel的活动,W矩阵(T×K)表示各个脑区在不同时刻所占的权重,F矩阵(K×V)表示各个脑区的空间上的隐含系数。在假设中提到fMRI是由若干个spatial pattern线性叠加组成。每个脑区可以看作是局部的spatial pattern(上图中右侧F矩阵中的一行),可以用redial basis function来描述。每个function对应一个脑区,所对应的神经信号也就是这个脑区的神经信号。所以,时刻t的fMRI数据(1×V)都是由W矩阵中的时刻t的行数据(1×K)(表示F矩阵中各个脑区在时刻t的权重占比)与F矩阵(K×V)所得。WTW中的每个元素都是每个时刻两个脑区所占权重的乘积的累加((1×T)×(T×1)),反应了脑区之间的功能连接。

TFA是对单一被试的分析,当然可以对它进行扩展变成对多个被试的分析如图右侧的Hierarchical Topographic Factor Analysis(HTFA)[8]。TFA可以通过weight matrix获得脑网络功能连接的动态变化(如时刻t的脑网络功能连接可以由时刻t的WT 矩阵(K×1)与时刻t的W矩阵(1×K)的乘积)。在进行多个被试的分析时,可以假设各个被试会服从一种全局的分布(每个脑区有相似的部分却又不完全一样),从而获得每个被试脑区更准确的估计。HTFA不仅可以做脑功能连接的分析,还可以当作是降维方法或是做brain decoding。
3
Inferring representational similarity structure
表征相似度分析,目的是研究感兴趣的脑区是如何对不同的实验任务进行表征的。当一个脑区对两个任务的编码方式比较相似的时候,被试进行两个任务时(例如看两张人脸图片)脑区的激活就会比较相似。将这个空间响应的模式展开成一个长的向量,然后来分析不同向量之间的相似度。
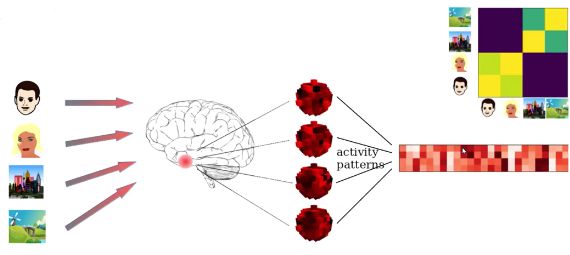
既然要分析相似度,首先就需要定义相似度。一个相关矩阵就是一个协方差矩阵,这个协方差矩阵就反应了不同脑区对于不同任务的响应有多么相似。我们想要得到图中红色activity patterns的相似度,但是我们并没有办法直接观测到它,只能得到由它间接产生的fMRI数据。所以我们需要把所有对数据产生影响的变量之间的关系都描述清楚,然后建立概率模型。然后使用积分去除掉不感兴趣的变量,获得我们感兴趣的协方差矩阵跟数据之间的直接关系。通过最大化似然函数,就可以得到哪一个协方差矩阵能够最好的解释得到的数据。

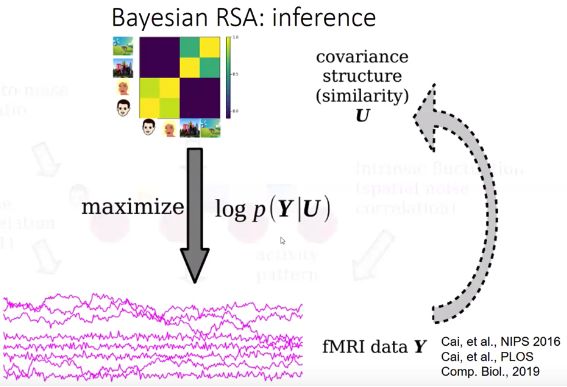

通过模拟的方法可以得到,Bayesian RSA[9][10](上图中BRSA)可以更好地恢复所模拟的相似性结构,而traditional RSA在某些特定条件下,会引入假的相似性结构,在噪声大的情况下,这种假的相似性结构会占据主导地位。

与先前两者类似,BRSA同样是对fMRI数据做了低维度因子分解的假设。三者之间的不同在于根据研究的问题不同,对因子分解的不同方面做了不同的假设。图中X矩阵(T×V)(time × voxels)表示感兴趣区的fMRI数据。S矩阵(T×K)(time × conditions)中T表示总共的时间点,K表示实验中的任务条件数量(例如先前举的人脸例子,一个人脸就代表一个任务条件)。W矩阵(K×V)(conditions × voxels)表示与所有任务条件相关的未知激活模式,其中每一列都共享同一个表示模式之间相似度的协方差矩阵(通过计算不同模式即W矩阵中不同行之间的cosine角度获得)。S0、W0表示与任务无关的空间波动,E表示剩余空间独立噪声。
4
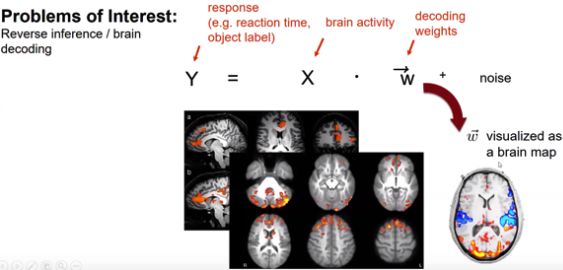
Obtaining biologically informed decoding weights
Brain decoding,从脑成像空间的pattern当中解码每一时刻人所处的状态。例如人受到什么刺激,反应时是怎么样的。便可以当作是一个回归的问题,给定一个脑活动,如何估计一个权重对脑活动进行加权,以此来预测被试的状态、行为。在取得权重后,便可以可视化,得到人脑的那些区域可以帮助我们更好地预测这些行为变量。

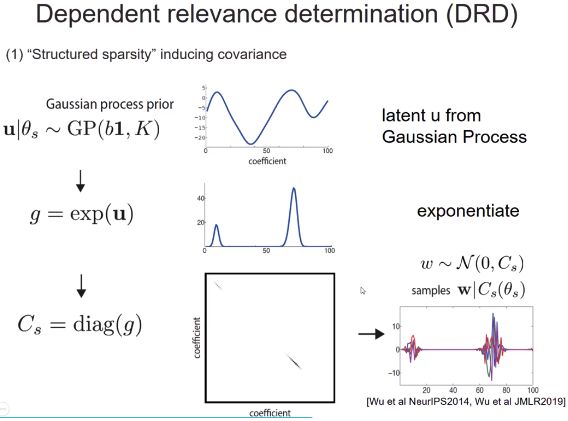

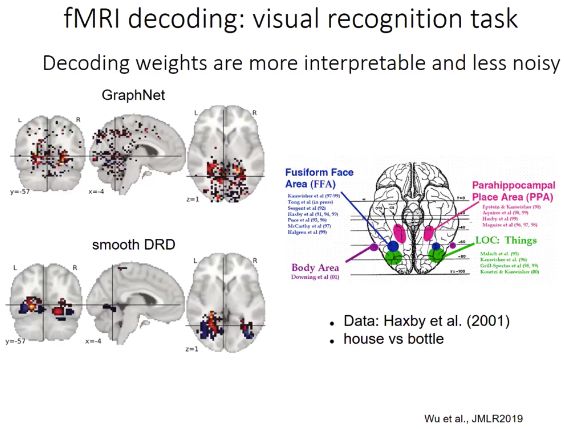
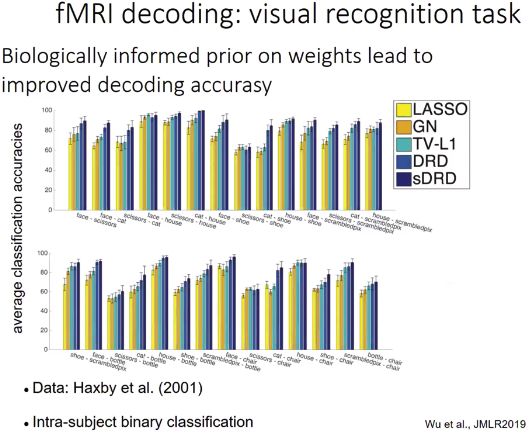
5
Modeling structured residuals
研究目的:如何用概率图模型对噪声进行建模。
fMRI中的噪声并不是独立的,它既有时间上的相关性, 也有空间上的相关性。所以需要将时间与空间上的相关性考虑进去,以防在估计模型变量的值的时候有偏差。接下来我们需要考虑如何引入时间与空间上的相关性。
在下图A中,每一个Voxel都可以当作是一个“瓷砖”(正方形方块),“瓷砖”之间的关系就反应了噪声在空间上的相关性。而每个“瓷砖”内部,即每个Voxel内部又反应了各个时间点的信息,即反应了噪声在时间上的相关性。假设时间和空间的相关性是可以拆分的话,那么就对应了下图B中的Matrix-variate normal model的分布。
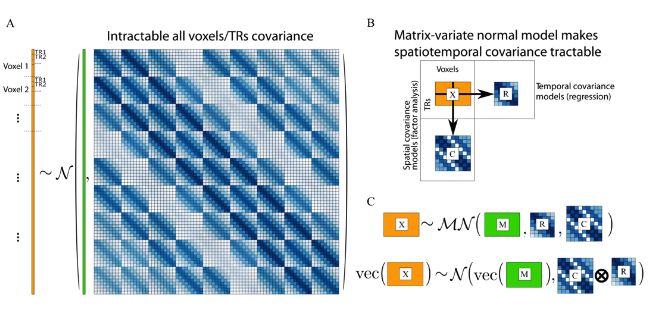
在fMRI分析当中,我们可以把噪声模型与之前介绍的方法(例如SRM、RSA)整合起来。在引入更好的噪声模型之后,可以更好地重构数据,也可以更好地恢复出来表征的相似性结构。
总结(从概率图模型在这五个领域中的应用,可以总结出概率图模型的优势):
概率图模型可以让我们的模型非常透明,需要显示地把知识转换为明确的先验假设。
概率图模型允许我们模拟一些数据,所以可以检验一个算法是否可以真正地恢复模型中的变量。
概率图模型具有灵活性,可以像搭积木的方式将他们结合起来。
References:
[1] Cai, M. B., Shvartsman, M., Wu, A., Zhang, H., & Zhu, X. (2020). Incorporating structured assumptions with probabilistic graphical models in fMRI data analysis. Neuropsychologia, 107500.
[2] Chen, P. H. C., Chen, J., Yeshurun, Y., Hasson, U., Haxby, J., & Ramadge, P. J. (2015). A reduced-dimension fMRI shared response model. In Advances in Neural Information Processing Systems (pp. 460-468).
[3] Zhang, H., Chen, P. H., Chen, J., Zhu, X., Turek, J. S., Willke, T. L., ... & Ramadge, P. J. (2016). A searchlight factor model approach for locating shared information in multi-subject fMRI analysis. arXiv preprint arXiv:1609.09432.
[4] Zhang, H., Chen, P. H., & Ramadge, P. (2018, March). Transfer learning on fMRI datasets. In International Conference on Artificial Intelligence and Statistics (pp. 595-603).
[5] Turek, J. S., Willke, T. L., Chen, P. H., & Ramadge, P. J. (2017, March). A semi-supervised method for multi-subject fMRI functional alignment. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1098-1102). IEEE.
[6] Shvartsman, M., Sundaram, N., Aoi, M., Charles, A., Willke, T., & Cohen, J. (2018, March). Matrix-normal models for fMRI analysis. In International Conference on Artificial Intelligence and Statistics (pp. 1914-1923).
[7] J. R. Manning, R. Ranganath, K. A. Norman, D. M. Blei, Topographic factor analysis: a Bayesian model for inferring brain networks from neural data, PLoS One 9 (2014) e94914.
[8] J. Manning, X. Zhu, T. Willke, R. Ranganath, K. Stachenfeld, U. Hasson, D. Blei, K. Norman, A probabilistic approach to discovering dynamic full-brain functional connectivity patterns, NeuroImage 180 (2018) 243 – 52.
[9] M. B. Cai, N. W. Schuck, J. W. Pillow, Y. Niv, Representational structure or task structure? bias in neural representational similarity analysis and a bayesian method for reducing bias, PLoS computational biology 15 (2019) e1006299.
[10] M. B. Cai, N. W. Schuck, J. W. Pillow, Y. Niv, A bayesian method for reducing bias in neural representational similarity analysis, in: Advances in Neural Information Processing Systems, pp. 4951–4959.
[11] A. Wu, O. Koyejo, J. Pillow, Dependent relevance determination for smooth and structured sparse regression, Journal of Machine Learning Research 20 (2019) 1–43.
文中图片来源:neurochat会议视频屏幕截图(侵权则删)。
写作:曲由之
校对:刘泉影
如需转载请先发邮件咨询:刘泉影,[email protected]
原文链接为bilibili视频网站中neurochat会议录屏,点击“阅读原文”即可观看。
