数据结构秘籍之链表
文章目录
-
- 啥是链表?
- 单链表的实现
- 链表的带环问题
-
- 解题思路
- 解题思路
- 复制带随机指针的链表
- 解题思路
- 双向循环链表的实现
啥是链表?
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
让我们来一步步了解
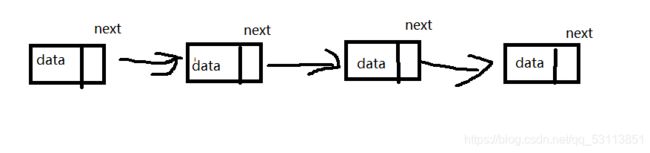
1.链表的大概形式(博主画得有点丑)
2.链表分为数据域和指针域,数据域就是图中data部分,这个部分是用来存储数据的,而指针域就是next,next是记录下一个链表的指针,最后一个指针为NULL,代表链表结束。
3.链表的数据类型,链表往往是由整形和xx指针组成的一个结构体,xx=结构体类型,代码如下:
typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType data;
struct SListNode* next;
}SListNode;
单链表的实现
1.动态申请一个节点
SListNode* BuySListNode(SLTDateType x)
{
SListNode* tmp = (SListNode*)malloc(sizeof(SListNode*));
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
tmp->data = x;
tmp->next = NULL;
return tmp;
}
2.尾插
void SListPushBack(SListNode** pplist, SLTDateType x)
{
assert(pplist);
SListNode* cur = *pplist;
if (cur == NULL
{
cur = BuySListNode(x);
*pplist = cur;
return;
}
while (cur->next != NULL)
{
cur = cur->next;
}
cur->next = BuySListNode(x);
}
有的小伙伴可能要不知道这里为什么要传二级指针,让我们来康康
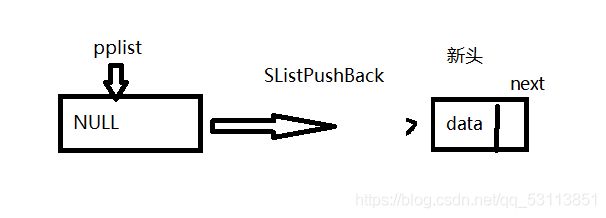
当cur为NULL,尾插会改变表头,如果只传一级指针,只是原指针的拷贝,不会改变原指针pplist的内容(此时pplist指向的内容依然是NULL,而我们用来接收动态开辟的空间的指针会在出函数是销毁,故动态开辟的内存的地址就不得而知了)。所以当表头会变时,需穿二级指针。
下面的一系列可能改变表头的接口都需要传二级指针。
3.头插
void SListPushFront(SListNode** pplist, SLTDateType x)
{
SListNode* tmp = *pplist;//拷贝旧的表头
*pplist = BuySListNode(x);
(*pplist)->next = tmp;//将新的表头链在旧表头前
}
4.尾删
void SListPopBack(SListNode** pplist)
{
SListNode* cur = *pplist;
if (cur == NULL)//此情况为链表为空,直接返回
{
return;
}
else if (cur->next = NULL)//该情况为链表只有一个,当free过后需将头指针置空
{
free(cur);
*pplist = NULL;
return;
}
while (cur->next != NULL)//找尾
{
cur = cur->next;
}
free(cur);
cur = NULL;
}
5.头删
void SListPopFront(SListNode** pplist)
{
SListNode* cur = *pplist;
if (cur == NULL)
{
return;
}
SListNode* tmp = cur->next;
free(cur);
*pplist = tmp;
}
6.查找
SListNode* SListFind(SListNode* plist, SLTDateType x)
{
assert(plist);
SListNode* cur = plist;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
printf("不存在\n");
return NULL;
}
7.在pos位置之后插入x
void SListEraseAfter(SListNode* pos)
{
assert(pos);
SListNode* dst = pos->next;
assert(dst);
SListNode* next = dst->next;
free(dst);
dst = NULL;
pos->next = next;
}
8.链表的销毁
void SListDestory(SListNode* plist)
{
assert(plist);
SListNode* cur = plist;
while (cur)
{
SListNode* tmp = cur->next;
free(cur);
cur = tmp;
}
}
链表的带环问题

解题思路
使用快慢指针,快指针每次走2步,慢指针每次走一步,如果链表不带环,快指针先走到NULL结束循环;
如果链表带环,快指针先进环,当慢指针进环时,它们相差x步(环的大小>x),而快指针比慢指针快一步,所以在x次循环后会满足快指针==慢指针。
代码如下
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
bool hasCycle(struct ListNode *head) {
struct ListNode * fastp=head;
struct ListNode * slowp=head;
if(!head)
{
return NULL;
}
while(fastp && fastp->next)
{
fastp=fastp->next->next;
slowp=slowp->next;
if(fastp==slowp)
{
return true;
}
}
return false;
}
这道题是上一道题的进阶,需找到成环的第一个点。
解题思路
这道题有个巧妙的解法,我们创建两个指针,一个指向链表表头,一个指向题目1中的环中相遇点,这两个指针同时迭代下一个节点,当这两个指针相遇时,这个节点就是所求的入环的第一个节点。
那么这是为什么呢? 我们来看看。
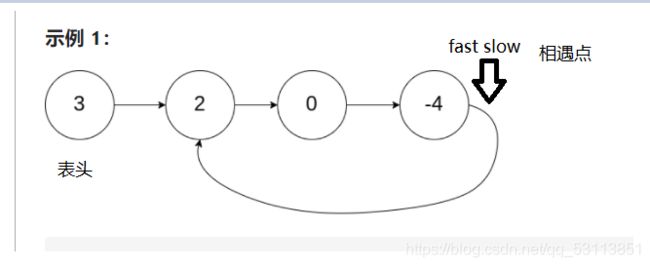
1.首先我们假设表头到入环的第一个节点的距离为m,入环点到相遇点的距离为x,slow入环前fast在环中循环了n圈,环的大小k
2.fast=m+nk+x
3.slow=m+n
4.fast=2slow

代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode * fastp=head;
struct ListNode * slowp=head;
struct ListNode * meet=NULL;
if(!head)
{
return NULL;
}
while(fastp && fastp->next)
{
fastp=fastp->next->next;
slowp=slowp->next;
if(fastp==slowp)
{
meet=fastp;
break;
}
}
if(meet)
{
while(1)
{
if(head==meet)
{
return meet;
}
head=head->next;
meet=meet->next;
}
}
return NULL;
}
复制带随机指针的链表

简单来说就是这个链表多了一个random指针,这个指针指向的内容时随机的,可能是任意一个链表,也可以是NULL。
这道题的难度就是如何拷贝random
解题思路
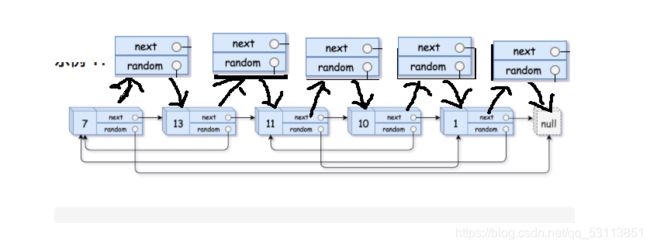
1.首先,我们将原链表的每一个节点拷贝并链接在其后(只拷贝数据和next,不拷贝random)
2.以第一个节点为例(下面通常cur),我们将通过cur->next找到cur的备份(下面通常bcp),bcp的random就是cur的random所指的节点的下一个,依次把整个链表遍历一遍
3.将原链表和备份链表分别指向自己的next
4.返回备份链表的头节点
代码
/**
* Definition for a Node.
* struct Node {
* int val;
* struct Node *next;
* struct Node *random;
* };
*/
struct Node* copyRandomList(struct Node* head) {
struct Node* cur=head;
struct Node* next=NULL;
if(!head)
{
return NULL;
}
while(cur)//拷贝子链表并插入在每个子链表之后
{
next=cur->next;
struct Node* copy=(struct Node*)malloc(sizeof(struct Node));
copy->val=cur->val;
copy->next=next;
cur->next=copy;
cur=next;
}
struct Node* copy=head->next;
cur=head;
while(copy)//原子链表的random->next就是新子链表的random
{
if(cur->random==NULL)
{
copy->random=NULL;
}
else
{
copy->random=cur->random->next;
}
if(copy->next==NULL)
{
break;
}
copy=copy->next->next;
cur=cur->next->next;
}
copy=head->next;
struct Node* newhead=copy;
cur=head;
while(copy->next)//将新旧链表分开
{
cur->next=copy->next;
cur=cur->next;
copy->next=cur->next;
copy=copy->next;
}
return newhead;
}
双向循环链表的实现
结构体类型
typedef int LTDataType;
typedef struct ListNode
{
LTDataType _data;
struct ListNode* _next;
struct ListNode* _prev;
}ListNode;
与单链表相比,多了一个prev指针。
1.创建节点
ListNode* ListBuy(int x)
{
ListNode* tmp = (ListNode*)malloc(sizeof(ListNode));
if (tmp == NULL)
{
printf("malloc fail\n");
exit(-1);
}
tmp->_prev = tmp->_next = NULL;
tmp->_data = x;
return tmp;
}
2.创建链表的头节点(该节点的数据无效)
ListNode* ListCreate()
{
ListNode* tmp = ListBuy(0);
tmp->_prev = tmp->_next = tmp;
return tmp;
}
3.销毁
void ListDestory(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->_next;
while (cur != pHead)
{
ListNode* next = cur->_next;
free(cur);
cur = next;
}
}
4.尾插
void ListDestory(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->_next;
while (cur != pHead)
{
ListNode* next = cur->_next;
free(cur);
cur = next;
}
}
5.尾删
void ListPopBack(ListNode* pHead)
{
assert(pHead);
assert(pHead->_next!=pHead);
ListNode* tail = pHead->_prev;
tail->_prev->_next = tail->_next;
tail->_next->_prev = tail->_prev;
free(tail);
}
6.头插
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* head = pHead->_next;
ListNode* tmp = ListBuy(x);
tmp->_prev = pHead;
pHead->_next = tmp;
tmp->_next = head;
head->_prev = tmp;
}
7.头删
void ListPopFront(ListNode* pHead)
{
assert(pHead);
ListNode* head = pHead->_next;
pHead->_next = head->_next;
head->_prev = pHead;
if (head != pHead)
{
free(head);
}
}
8.查找
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* cur = pHead->_next;
while (cur != pHead)
{
if (cur->_data == x)
{
return cur;
}
cur = cur->_next;
}
return NULL;
}
9.在pos前插入
void ListInsert(ListNode* pos, LTDataType x)
{
assert(pos);
ListNode* tmp = ListBuy(x);
ListNode* prev = pos->_prev;
tmp->_prev = prev;
tmp->_next = pos;
pos->_prev = tmp;
prev->_next = tmp;
}
10.删除pos处的节点
void ListErase(ListNode* pos)
{
assert(pos);
assert(pos->_next != pos);
pos->_prev->_next = pos->_next;
pos->_next->_prev = pos->_prev;
free(pos);
}
此类型的链表相对与单链表,不用找尾,不会移动头节点,进行修改数据的效率高。