配置Hadoop3.3.0完全分布式集群
前言:
本文主要介绍配置Hadoop3.3.0完全分布式集群;
一、部署环境规划
1.服务器地址规划

2.需要部署的环境
(1)关闭火墙(开机自启可以不设置)
[root@localhost java]# systemctl stop firewalld
[root@localhost java]# systemctl disable firewalld
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
#火墙为dead即可
[root@localhost ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
(2)关闭SELinux
#修改配置文件
[root@localhost java]# vi /etc/selinux/config
SELINUX=disabled
#修改完需要重启才能生效:
[root@localhost java]# reboot
#查看为disabled即可
[root@localhost ~]# getenforce
Disabled
3.统一/etc/hosts解析
[root@localhost ~]# vi /etc/hosts
192.168.56.88 Master.Hadoop
192.168.56.55 Slave1.Hadoop
192.168.56.77 Slave2.Hadoop
4.修改主机名(方便辨识,可以不修改)
hostnamectl set-hostname masterhostnamectl set-hostname salve1
hostnamectl set-hostname salve2
修改完需要重启,才可生效;
5.SSH无密码验证配置
(1)Master(192.168.56.88)操作
[root@master ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
#一路回车即可
[root@master ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
(2)分发公钥到两个Slave上面
- Slave1(192.168.56.55)
[root@slave1 ~]# scp [email protected]:~/.ssh/id_dsa.pub ~/.ssh/master_dsa.pub
[email protected]'s password: #第一次需要输入密码;
id_dsa.pub 100% 601 212.8KB/s 00:00
[root@slave1 ~]# cat ~/.ssh/master_dsa.pub >> ~/.ssh/authorized_keys
- Slave2(192.168.56.77)
[root@slave2 ~]# scp [email protected]:~/.ssh/id_dsa.pub ~/.ssh/master_dsa.pub
[email protected]'s password:
id_dsa.pub 100% 601 197.2KB/s 00:00
[root@slave2 ~]# cat ~/.ssh/master_dsa.pub >> ~/.ssh/authorized_keys
- Master测试连接Slave
[root@master ~]# ssh Slave1.Hadoop
Last login: Thu Oct 29 23:04:22 2020 from master.hadoop
[root@slave1 ~]# logout
Connection to slave1.hadoop closed.
[root@master ~]# ssh Slave2.Hadoop
Last login: Thu Oct 29 23:06:14 2020 from master.hadoop
[root@slave2 ~]# logout
Connection to slave2.hadoop closed.
二、Hadoop安装以及环境配置
1.Master操作
1.1安装java环境
[root@master ~]# tail -4 /etc/profile
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
1.2查看java环境
[root@master ~]# source /etc/profile #修改完配置文件之后需要source一下才能生效;
[root@master ~]# java -version #我的java为1.80版本
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
2.Hadoop安装以及环境配置
2.1安装
[root@master~]#wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz #hadoop-3.3.0下载地址
[root@master ~]# tar -zxf hadoop-3.3.0.tar.gz -C /usr/
[root@master ~]# mv /usr/hadoop-3.3.0/ /usr/hadoop/
配置hadoop环境变量
[root@master hadoop]# vi /etc/profile
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
[root@master hadoop]# source /etc/profile
2.2配置hadoop-env.sh
[root@slave1 ~]# echo $JAVA_HOME #查看你此时的java_home
/usr/java/jdk1.8.0_131
[root@master hadoop]# vi /usr/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_131
[root@master hadoop]# source /usr/hadoop/etc/hadoop/hadoop-env.sh
[root@master hadoop]# hadoop version #配置生效后可查看hadoop版本
Hadoop 3.3.0
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r aa96f1871bfd858f9bac59cf2a81ec470da649af
Compiled by brahma on 2020-07-06T18:44Z
Compiled with protoc 3.7.1
From source with checksum 5dc29b802d6ccd77b262ef9d04d19c4
This command was run using /usr/hadoop/share/hadoop/common/hadoop-common-3.3.0.jar
2.3.创建Hadoop所需的子目录
[root@master hadoop]# mkdir /usr/hadoop/{tmp,hdfs}
[root@master hadoop]# mkdir /usr/hadoop/hdfs/{name,tmp,data} -p
2.4.修改Hadoop核心配置文件core-site.xml
配置是HDFS master(即namenode)的地址和端口号
[root@master hadoop]# vim /usr/hadoop/etc/hadoop/core-site.xml
hadoop.tmp.dir
/usr/hadoop/tmp
true
A base for other temporary directories.
fs.default.name
hdfs://192.168.56.88:9000
true
io.file.buffer.size
131072
2.5.配置hdfs-site.xml文件
[root@master hadoop]# vim /usr/hadoop/etc/hadoop/hdfs-site.xml
dfs.replication
2
副本个数,默认是3,应小于datanode机器 数目
dfs.name.dir
/usr/hadoop/hdfs/name
dfs.data.dir
/usr/hadoop/hdfs/data
dfs.namenode.secondary.http-address
master.hadoop:9001
dfs.webhdfs.enabled
true
dfs.permissions
false
2.6.配置mapred-site.xml文件
|
|
2.7.配置yarn-site.xml文件
[root@master hadoop]# vim /usr/hadoop/etc/hadoop/yarn-site.xml
yarn.resourcemanager.address
Master.Hadoop:18040
yarn.resourcemanager.scheduler.address
Master.Hadoop:18030
yarn.resourcemanager.webapp.address
Master.Hadoop:18088
yarn.resourcemanager.resource-tracker.address
Master.Hadoop:18025
yarn.resourcemanager.admin.address
Master.Hadoop:18141
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
2.8.配置workers文件(主从节点都需要配置)
[root@slave1 hadoop]# vi /usr/hadoop/etc/hadoop/workers
[root@slave1 hadoop]# cat /usr/hadoop/etc/hadoop/workers
Slave1.Hadoop
Slave2.Hadoop
2.9 配置yarn-env.sh文件
[root@master hadoop]# vi yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_131 #加入JAVA_HOME
2.10配置start-dfs.sh stop-dfs.sh
[root@slave1 sbin]# pwd
/usr/hadoop/sbin
[root@slave1 sbin]# vi start-dfs.sh
[root@slave1 sbin]# vi start-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2.11配置 start-yarn.sh staop-yarn sh
[root@slave1 sbin]# pwd
/usr/hadoop/sbin
[root@slave1 sbin]# vi start-yarn.sh
[root@slave1 sbin]# vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3、Slave服务器安装及配置
3.1.拷贝jdk到Slave
[root@master ~]#scp -rp /usr/java/jdk1.8.0_181 [email protected]:/usr/java/
[root@master ~]#scp -rp /usr/java/jdk1.8.0_181 [email protected]:/usr/java/
3.2.拷贝环境变量/etc/profile
[root@master ~]#scp -rp /etc/profile [email protected]:/etc/
[root@master ~]#scp -rp /etc/profile [email protected]:/etc/
3.3.拷贝/usr/hadoop
[root@master ~]#scp -rp /usr/hadoop [email protected]:/usr/
[root@master ~]#scp -rp /usr/hadoop [email protected]:/usr/
到此环境已经搭建完毕
4.启动以及验证Hadoop
4.1启动
4.1.1格式化HDFS文件系统
在master机器上,任意目录输入 hdfs namenode -format 格式化namenode,第一次使用需格式化一次,之后就不用再格式化,如果改一些配置文件了,可能还需要再次格式化,
注意:格式化次数过多的话会出现问题。
[root@master bin]# pwd
/usr/hadoop/bin
[root@master bin]# hdfs namenode -format
4.1.2启动Hadoop集群所有节点
[root@master sbin]# sh /usr/hadoop/sbin/start-all.sh
4.1.4关闭Hadoop集群所有节点
[root@master sbin]# sh /usr/hadoop/sbin/stop-all.sh
4.1.3查看Hadoop进程
[root@master sbin]# jps
20753 SecondaryNameNode
20995 ResourceManager
20488 NameNode
23613 Jps
4.1.3 Slave1 Slave2查看Hadoop进程
[root@slave1 sbin]# jps
4336 DataNode
4610 Jps
4445 NodeManager
[root@slave2 current]# jps
11985 DataNode
12205 Jps
12094 NodeManager
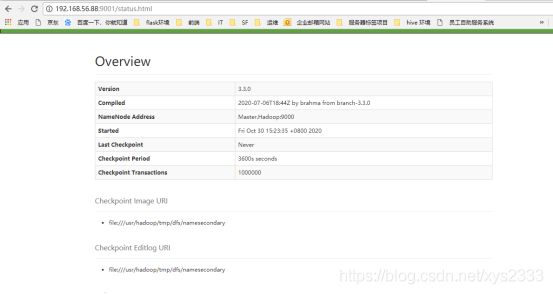
4.1.4 在浏览器也可以看到
http://192.168.56.88:9001/
5.在进行添加节点,配置用户等效性的时候,报错:
[oracle@rac2 ~]$ ssh oracle@rac1 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: POSSIBLE DNS SPOOFING DETECTED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
The RSA host key for rac1 has changed,
and the key for the corresponding IP address 186.168.100.22
is unknown. This could either mean that
DNS SPOOFING is happening or the IP address for the host
and its host key have changed at the same time.解决:
[oracle@rac2 ~]$ vi .ssh/known_hosts
将rac1有关的记录全部删掉。
6.多次格式化之后导致datanode不启动
[root@master bin]# pwd
/usr/hadoop/bin
[root@master bin]# hdfs namenode -format
hadoop namenode -format
多次格式化后,datanode启动不了解决办法:
/data/hadoop/dfs/name/current/VERSION
用name下面的clusterID,修改datanode的/data/hadoop/dfs/data/current/VERSION 里面的clusterID
每次格式化,name下面的VERSION的clusterID会产生一个新的ID,要去修改各个节点的VERSION的clusterID……/dfs/data/current
1.找到data和name配置的dir路径,找到hdfs-site.xml文件
vim /usr/hadoop/etc/hadoop/hdfs-site.xml
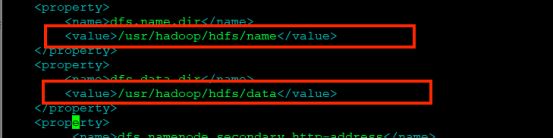
2.分别将name的clusterID改到主从节点的data的clusterID
[root@master current]# pwd
/usr/hadoop/hdfs/name/current
[root@master current]# vim VERSION

[root@master current]# pwd
/usr/hadoop/hdfs/data/current
[root@master current]# vim VERSION

文章到这里已经结束了,欢迎关注后续!!!!