爬取豆瓣网新书传递信息,关系型数据库的储存
爬取豆瓣网新书传递信息,数据保存到数据库中。
爬取信息包括书名、评分、作者、出版社、出版时间、图书介绍。豆瓣图书新书速递的网址为
需要爬取的网页地址–点击
一、实例
首先我们要做的事情,是打开网页,用F12观察结构

发现该该网页没有分页,只有左右两个div盒子,但是按照以前的爬取方法,我们只能爬取一个div,那么这次的解决方法是什么呢?是要分开爬取?还是有其他的解决方法,就接着往下看吧!
这次解析网页是使用的xpath。
1,得到网页 ——get_html
def get_html(url,headers,time=10): #get请求通用函数,去掉了user-agent简化代码
try:
r = requests.get(url, headers=headers,timeout=time) # 发送请求
r.encoding = r.apparent_encoding # 设置返回内容的字符集编码
r.raise_for_status() # 返回的状态码不等于200抛出异常
return r.text # 返回网页的文本内容
except Exception as error:
print(error)
2,解析网页 ——parse_html
bookinfos=[]
def parse_html(html):
doc=etree.HTML(html)
for row in doc.xpath("//div[@id='content']//li"):
bookname=row.xpath("./div/h2/a/text()")[0]
score=row.xpath("./div/p[1]/span[2]/text()")[0].strip()
apt=row.xpath("./div/p[2]/text()")[0].strip()
aptt=apt.split('/')
author=aptt[0]
press=aptt[1]
pubdate=aptt[2]
describe=row.xpath("./div/p[3]/text()")[0].strip()
bookinfo=(bookname,score,author,press,pubdate,describe)
bookinfos.append(bookinfo)
可以看出虽然是左右两个div,这时我们向上查找找到包含左右两个div的大盒子进行xpath的分析。 注意到aptt 我们用split函数进行了分割成列表,取了第1个第2个第3个值。是因为在本次要爬取的网页里面是放在一个标签里面的,我们观察它的结构发现每一个我们需要爬取值是由‘/’ 分割开的,联系我们的python语法知识 我们就可以得知 解决方案。
3,保存到mysql ——save_html
def save_html(sql,vals,**dbinfo):
try:
conn = pymysql.Connect(**dbinfo)
cursor=conn.cursor()
cursor.executemany(sql,vals)#批量处理添加数据
conn.commit()
print("insert success")
except:
conn.rollback()
print("insert faild")
finally:
cursor.close()
conn.close()
4,main函数
if __name__=="__main__":#main函数,流程设计
url='https://book.douban.com/latest?icn=index-latestbook-all'
headers={
"User-Agent":
"Mozilla/5.0 (Windows NT 6.3; Win64; x64)\
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/89.0.4389.82 Safari/537.36"
}
html=get_html(url,headers)
parse_html(html)
print(bookinfos)
parms={
"host":'localhost',
"port":3306,
"user":'root',
"passwd":'root',
"db":'beautifulsoup-sql',
"charset":'utf8'
}
sql="insert into doubanbook(BookName,Score,Autor,Press,Pubdate,describ) values(%s,%s,%s,%s,%s,%s)"
save_mysql(sql,bookinfos,**parms)
二、关系型数据库存储
**![]()
**
关系型数据库是基于关系模式的数据库,而关系模式是通过二维表来保存的,他的储存方式就是行列组成的表,每一列是一个字段,每一行是一条记录。
1,链接数据库
pyMySQL 库的安装操作如下:
pip install pymysql
pymysql 库安装后,可在命令下进行测试,具体指令:
import pymysql
pymysql.VERSION
pymysql库提供connect() 可连接数据库,具体语法如下:
pymysql.connect(host=mysql_host,port=port,user=user,password=password,db=db,charset='')

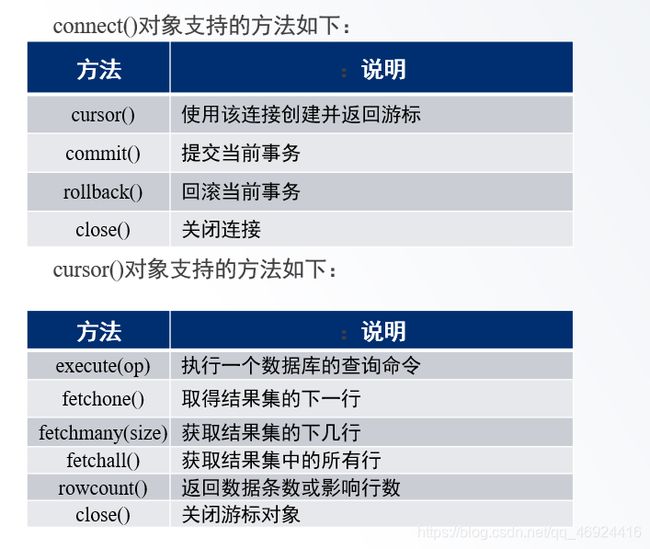
链接数据库读写、选择、整理、描述:

2,插入数据


如果表新增字段,比如gender性别字段,sql语句则需要修改,这增加了我们的代码维护难度,这种方式及其不方便,可以传入一个动态变化的字典,插入方式不需要修改就可以增加新的字段:
(id,name,age,gender)
{
'id':'12345678',
'name':'hdjk',
'age':20
}
使用动态字典插入数据,具体代码如下:
import pymysql
data={
'id':'12345678',
'name':'hdjk',
'age':20
}
table ='students' # 表名
keys=','.join(data.keys()) #得到字典的键 并用join函数把它分成一个字符串
values=','.join(['/s']*len(data)) #跟据sql语句 vaules 后面需要与字段名数相对应的/s
db=pymysql.connect(host='lcoalhost',user='root',password='root',port=3306)
cursor=db.cursor()
aql='insert into {table}({keys}) vaules ({valeus})'.format(table=table,keys=keys,values=values)
try :
if cursor.execute(sql,tuple(data.values())):
print('success')
db.commit()
except:
print('failed')
db.rollback()
db.close()
3,更新数据
可想而知 构建动态字典的语句几乎一样的,在这里我们就只特定说明sql语句。
sql= ','.join([' {keys}=%s'.format(keys=keys) for key in data])
4,删除数据
aql ='delete from {table } where {condition}'.format(table = table,condition=condition)
根据具体情况分析,try-except里面的语句也会有差微变化。