豆瓣图书爬取并进行评论的特征提取
1.运用python爬虫爬取和数据库的持久化存储
2.运用TF-IDF方法进行特征提取
一、scrapy爬虫框架介绍
· Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛
· 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便
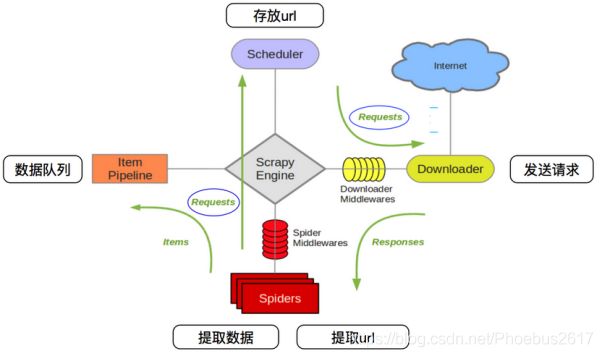
制作 Scrapy 爬虫 一共需要4步:
1.新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
2.明确目标 (编写items.py):明确你想要抓取的目标
3.制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
4.存储内容 (pipelines.py):设计管道存储爬取内容
二、文本特征提取简介
TF(Term Frequency)词频,在文章中出现次数最多的词,然而文章中出现次数较多的词并不一定就是关键词,比如常见的对文章本身并没有多大意义的停用词。所以我们需要一个重要性调整系数来衡量一个词是不是常见词。该权重为IDF(Inverse Document Frequency)逆文档频率,它的大小与一个词的常见程度成反比。在我们得到词频(TF)和逆文档频率(IDF)以后,将两个值相乘,即可得到一个词的TF-IDF值,某个词对文章的重要性越高,其TF-IDF值就越大,所以排在最前面的几个词就是文章的关键词。
TF-IDF算法步骤:
(1)、计算词频:
词频 = 某个词在文章中出现的次数
考虑到文章有长短之分,考虑到不同文章之间的比较,将词频进行标准化
词频 = 某个词在文章中出现的次数/文章的总词数
词频 = 某个词在文章中出现的次数/该文出现次数最多的词出现的次数
(2)、计算逆文档频率
需要一个语料库(corpus)来模拟语言的使用环境。
逆文档频率 = log(语料库的文档总数/(包含该词的文档数 + 1))
(3)、计算TF-IDF
TF-IDF = 词频(TF)* 逆文档频率(IDF
三、实验结果展示及分析
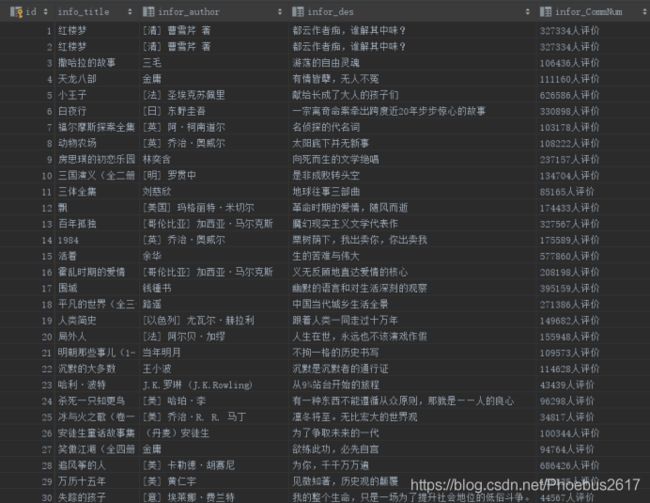
1.爬取相关的字段进入到数据库中,一共爬取了50本书的相关字段内容,这里我用Python里很轻量级的sqlite,因为爬取的字段内容量较小,下图为爬取的结果:
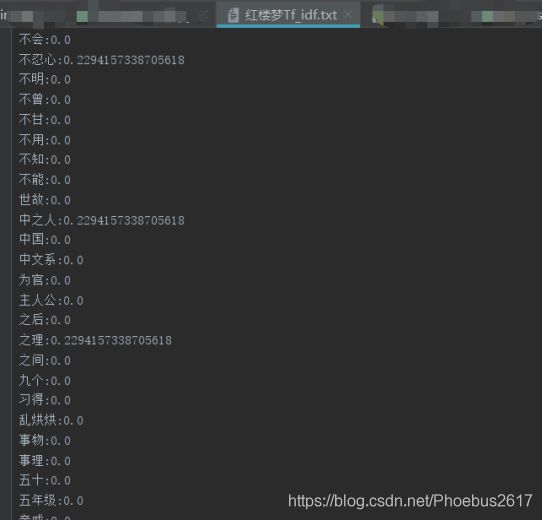
2.运用TF-IDF方法进行特征提取,这里我用了TfidfVectorizer库里的方法,最后将每本书提取到的结果放入了一个txt文件夹中,方便后续的分析:

(1)下图是各个书籍评论的特征提取(只展示部分结果),在第二步中,我们进一步打开其中一个
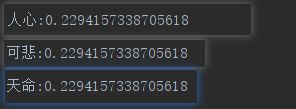
(2)下图是对《红楼梦》进行特种提取时的的结果,(只做部分展示),同时我们看到,一些词语(人心,可悲,天命)的TD-IDF的值到了0.2以上,这些词语代表了广大网友对后楼梦这部著作的评价
四、代码实现
(1)创建工程,scrapy框架在对应目录下用控制台命令创建工程
目录列表如下:
(2)数据解析,scrapy框架通过下载器将start_url中得到的数据传送给response,然后可以利用scrapy中的xpath解析器将相关字段提取出来。代码如下:
item = DoubanBookItem()
# 书名
title = td.xpath('./div[1]/a/text()').extract()
title = ''.join(title).strip()
item['title'] = title
# 作者
author = td.xpath('./p[1]/text()').extract()
author = ''.join(author).split('/', 1)[0].strip()
item['author'] = author
# 评论数
commNum = td.xpath('./div[2]/span[3]/text()').extract()
commNum = ''.join(commNum).split('\n')[1].strip()
item['commNum'] = commNum
(3)翻页爬取:我们最少要爬取50个书本的信息
start_urls = ['https://book.douban.com/top250?start=']
i = 0
def parse(self, response):
if self.i < 2:
next_url = 'https://book.douban.com/top250?start={}'.format(self.i * 25)
self.i += 1
yield scrapy.Request(url=next_url, callback=self.parse)
(4)多级页面爬取:由于要爬取的评论和数据在在两级页面里,所以评论数据的获取需要将上一级爬取到的评论链接交给scrapy的调度器,调度器将得到的url再放入队列依次交给下载器获取响应
# yield使得函数变为一个生成器,Request里的callback参数将指定分析下一级网页的数据解析函数
yield scrapy.Request(url=link, meta={
'item': item}, callback=self.DoubanComm)
(5)数据库存储,在scrapy框架中有管道专门用来进行数据的持久化存储,首先定义item,item是scrapy框架定义好的一个字典,相关字段赋给item然后通过管道文件将数据持久化存储。
# 定义item
class DoubanBookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
commNum = scrapy.Field()
bookdes = scrapy.Field()
link = scrapy.Field()
# 持久化存储,将数据写入数据库
class DoubanBookPipeline:
# 连接数据库,只执行一次
def open_spider(self, spider):
self.conn = sqlite3.connect("doubanbook.db")
self.cursor = self.conn.cursor()
self.conn.commit()
# 将数据插入数据库
def process_item(self, item, spider):
self.s1 = '"' + item['title'] + '"'
self.s2 = '"' + item['author'] + '"'
self.s3 = '"' + item['bookdes'] + '"'
self.s4 = '"' + item['commNum'] + '"'
self.data = []
self.data.append(self.s1)
self.data.append(self.s2)
self.data.append(self.s3)
self.data.append(self.s4)
# print(self.s1,self.s2,self.s3,self.s4)
# print(item['title'])
sql = '''
insert into booktop250(
info_title,infor_author,infor_des,infor_CommNum)
values(%s)'''%",".join(self.data)
self.cursor.execute(sql)
self.conn.commit()
return item
# 关闭数据库,只执行一次
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
(6)特征提取,这里用到了sklearn框架里的TfidfVectorizer库,将提取到的评论进行模型拟合,这个过程涉及到停用词的过滤,最后将特征与对应的TF-IDF的值写到文件中,方便后续的分析
# 过滤停用词的模型拟合,得到TfidfVectorizer对象的实例
stpwrdpath = "C://Users//DELL//Desktop//中文停用词.txt"
with open(stpwrdpath, 'rb') as fp:
stopword = fp.read().decode('utf-8') # 停用词提取
stopwordlist = stopword.splitlines()
tfidf = TfidfVectorizer(stop_words=stopwordlist)
(7)反爬机制,豆瓣图书会检测异常的IP请求,在多次重复爬取时,豆瓣网页提示登录查看,这里我很自然的想到了构建一个代理IP池,
用random模块每次通过不同的IP代理去访问,这里网上免费的代理效果不是很理想,但够用。
I)下面的代码为构建的代理中间件
# 构造代理中间件
import random
from .proxies import proxy_list
class DOubanRadomDownloaderMiddleware(object):
def process_request(self, request, spider):
proxy = random.choice(proxy_list)
request.meta["proxy"] = proxy
def process_exception(self, request, exception, spider):
return request
II)代理池列表
proxy_list = [
'http://113.128.8.237:9999',
'http://175.42.68.160:9999',
'http://171.35.174.214:9999',
'http://58.253.154.192:9999',
'http://113.194.50.95:9999',
'http://120.83.111.36:9999',
'http://171.35.213.97:9999',
'http://175.42.158.72:9999',
]
III)还要记得在sitting中将代理中间件加入,并分配相应的优先级
DOWNLOADER_MIDDLEWARES = {
'douban_book.middlewares.DoubanBookDownloaderMiddleware': 543,
'douban_book.middlewares.DOubanRadomDownloaderMiddleware':300,
}