Python爬虫(十三)——Scrapy爬取豆瓣图书
文章目录
- Python爬虫(十三)——Scrapy爬取豆瓣图书
-
- 步骤
-
- 建立项目和Spider模板
- 编写Spider
- 编写Pipelines
- 配置settings
- 执行程序
- 完整代码
- 鸣谢
Python爬虫(十三)——Scrapy爬取豆瓣图书
这次我们爬取豆瓣图书的top250的目录后进入书籍界面爬取界面中的书籍标签。
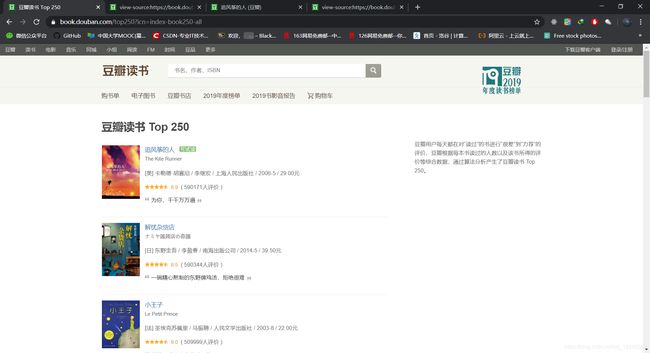
步骤
建立项目和Spider模板
使用以下命令
scrapy startproject demo
cd demo
scrapy genspider book book.douban.com
编写Spider
打开网页,我们发现一页只有25本书,然后打开第二页观察url:
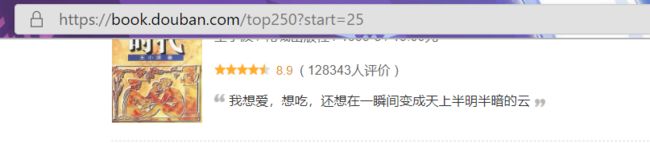
我们发现start变成了25,由此推测每页有25本,于是我们设置start-urls为:
start_urls = ['https://book.douban.com/top250?start='+str(25*i) for i in range(10)]
接下来在top250的界面中爬取到每本书籍的url。打开网页观察代码:

经过观察,我们发现书籍的信息在标签tr属性为item的代码块中,而书籍的url则是在标签a中。利用yield将这个请求的结果返回:
def parse(self, response):
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.find_all('tr', attrs={
'class': 'item'}):
for href in item.find_all('a'):
if href.string != None:
url = href.attrs['href']
yield scrapy.Request(url, callback=self.parse_book)
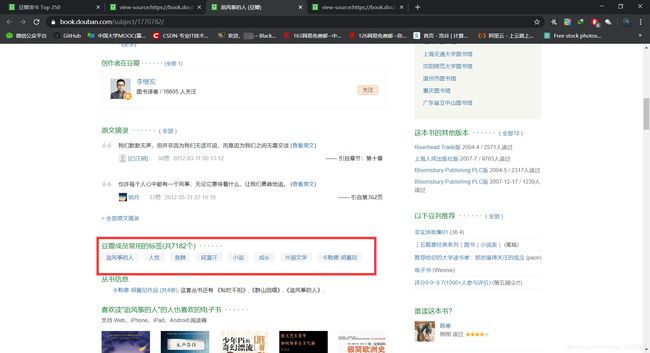
然后打开书籍信息界面的源代码搜索tag找到了书籍标签的所在位置

发现我们可以用正则表达式’tag/.*?"'来得到书籍的标签,然后用yield来返回得到的书籍信息:
def parse_book(self, response):
infoDict = {
}
booksoup = BeautifulSoup(
response.text, 'html.parser')
infoDict.update(
{
'bookname': booksoup.title.string[:-4]})
tagInfo = re.findall('tag/.*?"', response.text)
tag = []
for i in tagInfo:
tag.append(i[4:])
infoDict['tag'] = tag
yield infoDict
编写Pipelines
在pipelines.py文件中我们设定一个filename来存放文件名,然后打开这个文件将得到的内容写进去:
filename = 'book.txt'
def open_spider(self, spider):
self.f = open(self.filename, 'w')
def close_spider(self, spider):
self.f.close()
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item
配置settings
打开settings.py文件,将pipelines设定为我们所编写的类:
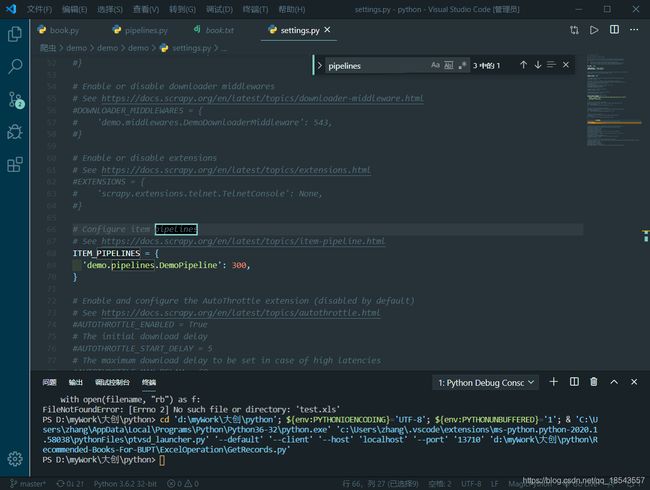
然后修改USER-AGENT
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
执行程序
最后打开命令行执行:
scrapy crawl book
运行结束后文件夹中就会得到一个book.txt文件:
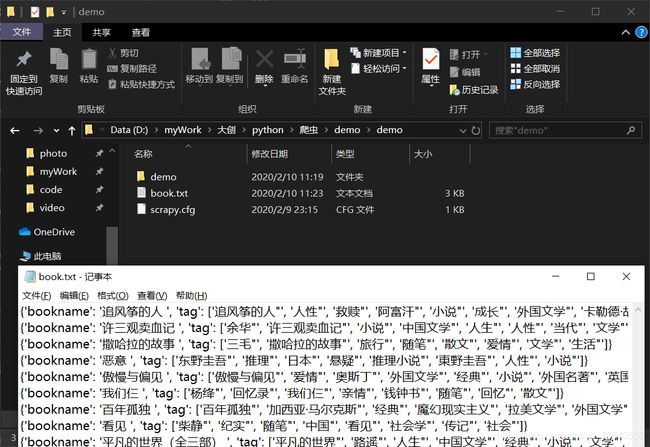
完整代码
book.py
# -*- coding: utf-8 -*-
import scrapy
from bs4 import BeautifulSoup
import re
class BookSpider(scrapy.Spider):
name = 'book'
start_urls = ['https://book.douban.com/top250?icn=index-book250-all']
def parse(self, response):
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.find_all('tr', attrs={
'class': 'item'}):
for href in item.find_all('a'):
if href.string != None:
url = href.attrs['href']
yield scrapy.Request(url, callback=self.parse_book)
def parse_book(self, response):
infoDict = {
}
booksoup = BeautifulSoup(
response.text, 'html.parser')
infoDict.update(
{
'bookname': booksoup.title.string[:-4]})
tagInfo = re.findall('tag/.*?"', response.text)
tag = []
for i in tagInfo:
tag.append(i[4:])
infoDict['tag'] = tag
yield infoDict
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class DemoPipeline(object):
filename = 'book.txt'
def open_spider(self, spider):
self.f = open(self.filename, 'w')
def close_spider(self, spider):
self.f.close()
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item
鸣谢
最后我要感谢慕课网北京理工大学嵩天老师开设的Python网络爬虫与信息提取这门课程,我的学习笔记都是对其课程的记录和自己的实践。没有嵩老师的课程我将无法学习到Python爬虫的那么多知识。感谢嵩老师和他的团队!传送门