声明:转载请声明作者,并添加原文链接。
简介
这篇博客主要解读seq2seq 自然语言处理模型,重点有三部分。
1. seq2seq 模型介绍
2. seq2seq 的注意力机制
3. 实战tensorflow tutoral 的实验过程。
本文实战代码是 https://github.com/tensorflow/nmt, 参考的课程主要是stanford CS224N Lecture 9, 10 ,11. http://web.stanford.edu/class/cs224n/
Seq2seq模型
以前的统计翻译法, 都是将句子分解成一段一段的, 然后每一小段进行翻译。 但是这样翻译出来的句子,不够流畅。 我们人类也不是这么翻译句子的。 人类应该是看懂了句子,再进行翻译, 而下面的神经机器翻译 sequence-to-sequence (seq2seq) 模拟了这个过程。
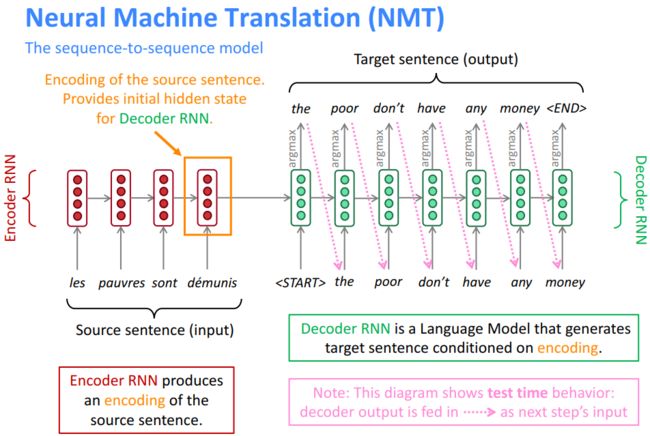
Fig. 1 介绍了一个标准的seq2seq模型。 其中红色的是encoder RNN, 绿色的是decoder RNN. 他们之间 有一个连线, 也就是encoder states 传给decoder RNN,当做initial state. 这个翻译过程可以解释如下。
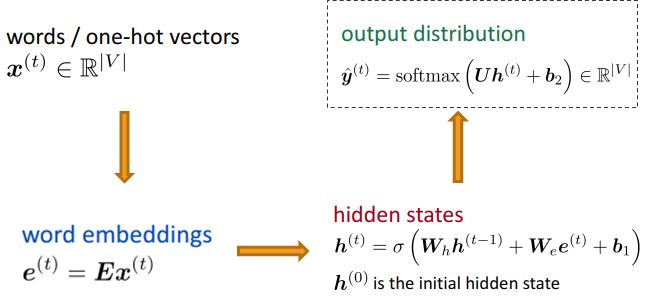
Encoder 过程: 图一就只有一个RNN cell, 每个法语单词都是按照时间顺序输入到这个RNN cell 里。 具体就如Fig. 2中的描述, 对于一个单词, 比如les, 首先要通过one-hot 方法来代表它, 然后通过word embeddings, 其实就是一个全连接的乘法。 不懂得同学可以看我以前的博客。 然后计算RNN隐形层。 对于encoder 的过程是没有输出y的计算的。 接下来, 这样h(t)就算出来了。 再输入下一个单词, h(t+1)就算出来了。 直到最后一个单词对应的隐形层h算出来, 这个h 会当做初始状态输入另一个rnn cell 做decoding.
Decoder 过程: decoding 的过程与encoding的过程相似。 只是多了区分training 和inference 的状态。 Fig. 1 描述的是Inference 的状态, decode 输出来的每一个单词都会当做下一个时刻的输入,来进行翻译。 而在训练过程中, 因为知道翻译出来的单词是什么,就会把这个单词当做输入进行训练。 Fig. 1 的inference的过程中用到了argmax, 这个函数,也就是每次都选择概率最大的那个单词当做翻译。 这个叫做greedy decoding. 这个不是optimal solution。 还可以使用beam searching, 就是多考虑几个单词,
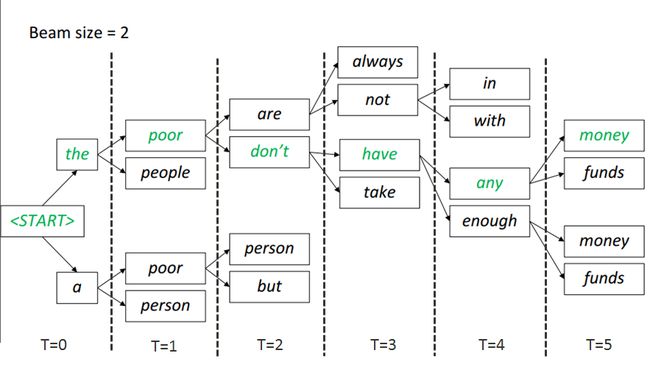
Beam search decoding: 这个方法在每个翻译的步骤 都保存k 个最可能的选择, k 就是beam size, 这个方法虽然不能保证最优解, 但是效率高了很多。 k 一般就是5-10. Fig. 3 就是一个 beam size =2 的例子。 在T=0 的时候, 有两个选择。 在T=1的时候还是两个选择路径 一个是the poor, 一个是a poor. 在T=2的时候选择是are , don't。 那么下面的那条路径就可以丢掉了, 只考虑上面的路径, 以此类推。
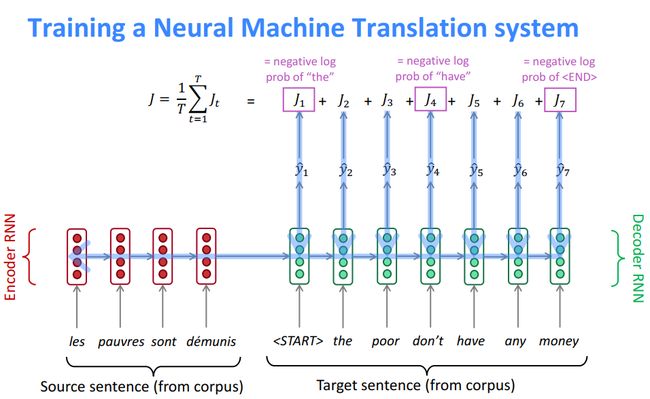
Loss 计算: 神经网络的Loss计算 就如Fig.4 一样,把每个翻译出来的单词和目标单词对应, 算出negative log,求和 就是总的loss.
注意力机制下的seq2seq模型
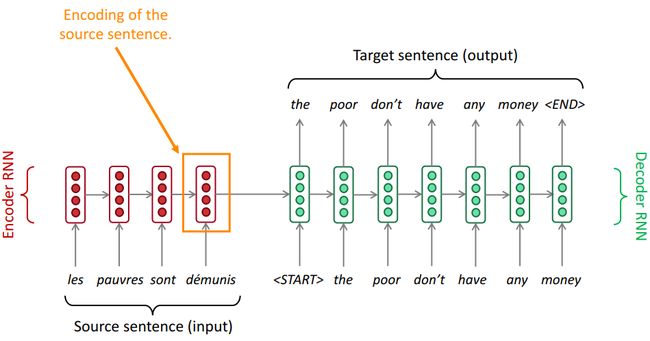
Fig. 5 的图中, 明确的标出了,最后一个state包含了整个句子的信息。 但是问题是,一个vector 是无法包含这么多信息的。 这样势必导致比较远的单词信息的丢失。 另一个优化上的问题是, 求微分时,较远的单词会受到diminishing gradient的影响, 导致失去了long term dependency 的关系。
Attention 注意力机制提供了一个可以和远距离单词保持联系的方式, 解决了一个vector保存信息不足的问题。
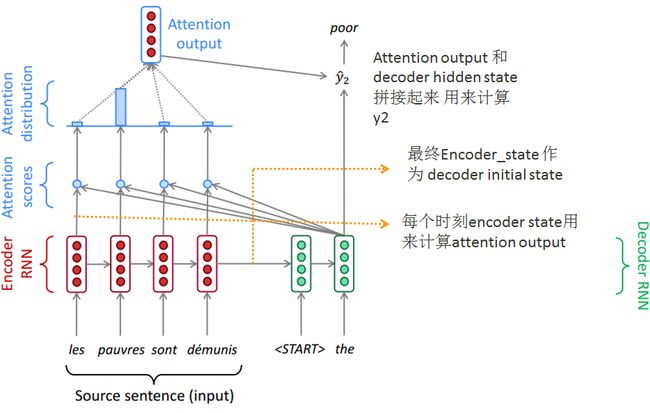
注意力机制的计算发生在decoder 的每一个步骤, 他包含了四个步骤。
首先decoder state 和encoder 所有的source state 进行softmax, 计算, 算出attention weights. 比如Fig. 6 里的 "the" hidden state, 就去和原文中的"les pauvres sont demunis"对应的state 进行softmax 计算。
基于这个attention weights (attention distribution 在Fig. 6里), 我们算出一个上下文向量(attention output)。 这个向量是通过加权平均的 source state.
attention output 再和 decoder hidden state 拼接起来, 最后算出y2. 下面的公式总结了这三步计算过程。
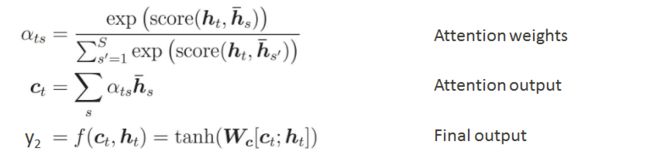
实战
实战使用的模型来自 https://github.com/tensorflow/nmt, 内容也是基于里面代码的介绍。
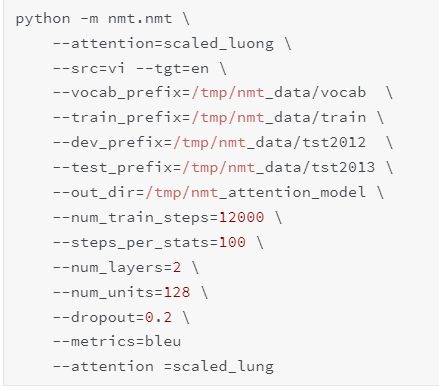
跑代码的方式在nmt 的tutorial 里已经解释的比较清楚了, 就是这两个命令。
训练命令
Inference 命令

训练代码跑起来就会在屏幕输出很多信息。
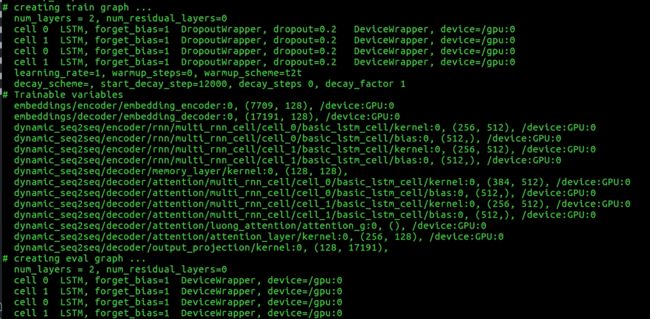
Fig. 7 提供了很多信息, 我的这个训练的代码是two layer LSTM, 然后第一个layer 是256 * 512, 这个矩阵的维度让我思考很久。 看了下LSTM 的计算方式,就容易理解多了。 如下图所示, LSTM 有四个 weight W 和四个 weight U. 这样输出维度就从128*4 = 512, 然后 输入的维度 不仅仅是x, 还有上一个state, 所以 输入维度就是128*2 = 256. 所以第一个LSTM的weight是 256*512. 对于docoder 过程, weight矩阵维度是384*512, 这个是因为输入端又多了一个attention vector , 也是128 维度, 所以128*3 = 384 维度。
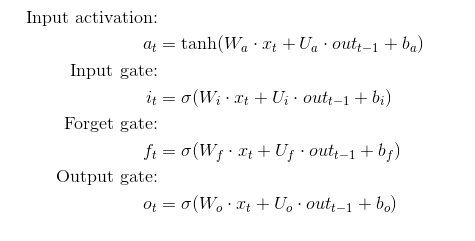
训练中, Result at 12000 steps
成功的例子

失败的例子
如果使用刚才inference命令, 可以翻译整本文件, 比如 我就是翻译的tst2013.vi, 翻译的结果还可以接受呢。 截图显示, 其中&apos 就是单引号。
