计算机原理学习(4)-- 操作系统发展和程序编译
前言
前面的文章主要都是计算机硬件相关的一些工作原理。而前一篇文章介绍了内存的工作原理,编址方式,逐步过渡到软件上面来了。前面也说过,内存是一个非常重要的部件,因为CPU所需的指令和数据都在内存中。所以从这一篇开始我们主要看看程序运行时在内存中的布局。
我们知道对于计算机系统来说,最底层的是硬件,硬件之上是操作系统,而我们的程序都是基于操作系统来运行的,而不是基于硬件,这样操作系统为我们提供了一层抽象,所以对于程序员来说,不需要特别的关注计算机硬件。所以正常来说介绍完硬件后,应该来介绍操作系统。但是我们知道在计算机在不断的发展,硬件,操作系统都在不断发展。而无论怎么发展,程序运行都离不开内存,所以我决定以内存和出发点,来看硬件,操作系统以及应用程序的发展过程。
1. 操作系统和内存布局
在第一代计算机时期,构成计算机的主要元器件是电子管,计算机运行速度慢(只有几千次/秒),当时没有操作系统,甚至没有任何软件。程序员首先编写程序,然后直接在计算机的控制台上操纵程序运行。
1.1 人工操作方式
当时的计算机有一个控制面板,上面有一些开关,当要启动计算机的使用,就是要把启动程序用手工输入到机器里去,其方法就是利用机柜面板上的一排开关,用二进制代码把指令一条一条拨进去。但是指令有限,干不了太多事情。
所以当时程序员使用机器码编写程序,然后通过打孔机,将程序转换到打孔的纸袋上。纸袋每排有八个孔的位置,穿了孔的代表1,没穿孔的代表0。然后通过纸带机等设备手工将程序装入计算机的内存,按动控制台开关和按扭确定程序的起始地址并启动程序执行。程序员只能通过控制台上的显示灯来观察程序执行情况。当程序运行出错时,程序员直接通过控制台开关来停止程序运行,检查内存及寄存器内容并调试程序。程序运行结果可以通过打印机或穿孔机输出。


上图就是纸袋和纸袋读入机器。但是存储程序的介质是纸袋,而加载程序是通过纸带机。其实这里我也有个疑问:
- 纸带机是如何把纸袋上的程序加载到内存的呢?
- 程序被加载到内存的地址是如何确定的呢?
我没有找到答案,不过这个并不影响我们对早期程序内存模型运行的理解。在当时,整个计算机资源(CPU,内存)是由当前运行才程序独占的。所以我们可以想象当时内存的模型。程序的第一条指令被加载到内存的最低地址,比如0x00000000。通过控制面板指定程序首地址,这样CPU就能够按照我们前面介绍的方式来一条条运行。当一个程序运行完成后,要运行下一个程序,需要在使用更换纸袋。清空当前内存,在加载新的程序。
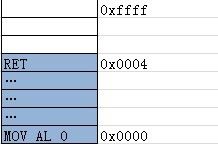
这种方式对于程序来说:
- 内存范围,可以读写可用的所有内存空间。
- 独占资源,在更换纸袋时CPU和内存资源是空闲的。
1.2 脱机输入/输出方式
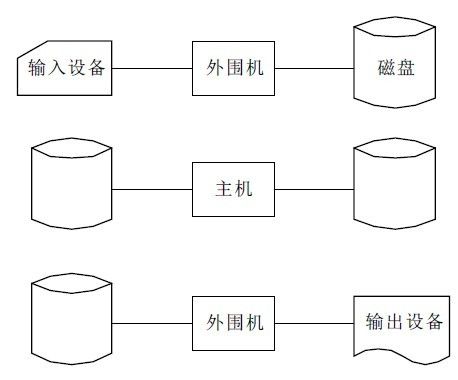
人工操作方式的主要问题在于,从纸袋读取或写入时浪费了CPU时间,于是就出现了脱机方式。就是首先把要执行的程序通过外围机控制纸带机输入到磁带上。相对于纸带机,从磁带上加载数据到内存要快的多。这个也符合我们前面介绍的存储器分层。脱机方式的有点在于:
- 减少了CPU空闲的时间,解决人机速度差距的矛盾
- 通过磁带,提高了I/O速度,进一步减少了CPU的空闲时间
1.3 单道批处理系统
我们知道那个时候的CPU是非常宝贵的资源。所以必须充分利用,尽量使多个程序能连续的运行。所以一般都会把一批程序以脱机方式输入到磁带上。然后当一个程序执行完成之后,马上运行下一个程序。但是这个过程不是由人来调度的,所以我们需要一个监控程序来控制这些程序一个一个的执行。于是除了我们要运行的程序之外,在内存中还存在这样一个监控程序,我们可以把他看看做早期操作系统的雏形,也就是单道批处理系统。
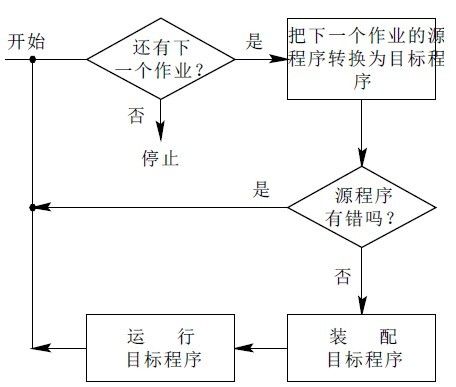
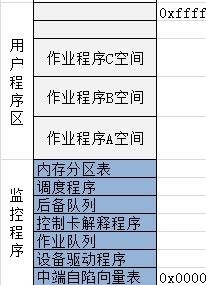
上图是单道批处理系统的流程图,看起来很简单。这个小程序需要常驻内存,也就是在开始执行其他程序之前,需要把他加载到内存中。当然加载的方式和其他程序相同。然后CPU开始执行这个监控程序。然后这个程序就开始进行批处理操作。于是在内存中,同一时间需要存放两个程序。下图是此时的内存布局.
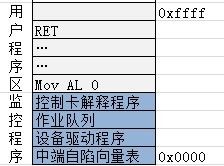
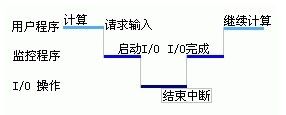
从此图我们可以发现,这个程序或许并不如我们想象的简单:
- 控制卡解释程序: 对于监控程序来说,他必须知道当前是那个程序在运行,这就需要每个程序能唯一的标识自己,所以需要在作业程序中加入一段控制卡代码,来唯一标识自己。所以监控程序也需要一个控制卡解释程序来识别这些标识。
- 设备驱动程序: 我们知道驱动程序是用来控制硬件控制芯片的,而批处理系统在一个程序运行完成时需要通过I/O设备加载下一个程序,所以需要驱动程序完成这些操作。
- 作业队列:监控程序能够根据控制卡提供的信息自动形成作业队列,所以当程序解释时监控程序可以加载下一个程序。
- 中端自陷向量表: 关于中端我们前面有介绍过,这里当系统执行I/O操作后,会以中端的方式通知,而这里的向量表则定义了不同中端对应的处理方式。
在这里我们可以发现,对于单道批处理程序来说,内存不再是独享,而是作业程序和监控程序共享,共享就会有一些问题:
- 作业程序加载的地址如何确定?
- 如何切换程序的控制权?
所以,我个人觉得,决定程序加载的位置应该是监控程序来确定。比如0x0000~0x050的内存区域是监控程序的区域,这样作业程序的起始地址就是0x0051,而监控程序通过修改PC计数器,来修改CPU要执行的下一条代码来切换程序控制权。
1.4 多道批处理程序
对于单道操作系统来说,他可以连续的运行多个程序,减少了程序切换时的CPU等待时间。但是它的问题在于,当执行I/O操作加时,CPU是空闲的。于是出现了多道批处理程序。多道批处理程序,把多个程序同时加载到内存中,当其中正在运行的程序执行I/O操作时,CPU可以继续执行其他的程序,而当I/O操作结束后,程序可以继续被执行。
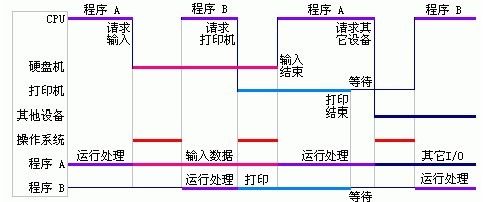
上图是多道批处中会存在2个以上的程序,所以需要一个内存分区表来标识每个程序占用的内存范围,以保证每个程序内存空间的独立。
- 后备队列: 虽然内存中存在多个程序,但是一个时间内只有一个程序会被执行,而其他没有被执行的程序如果单道程序的作业一样也有一个队列,我们叫后备队列。
- 调度程序:对于多道批处理程序来说,它除了要监控之外,还需要一个调度程序,来决定在I/O操作时,后备队列中的那一个程序获得CPU时间。
多道批处理系统的优点在于资源利用率高、系统吞吐量大、平均运行时间长。同样也存在物交互能力,而且需要内存管理,作业调度,设备管理等功能,这就增加了程序的负责的度。
1.5 现代操作系统
可以说批处理操作系统是现代操作系统的雏形。从DOS到Windows3.1,到Win95,WinXP,Win8,Unix,Linux。现代操作系统可以说是一个庞大的程序,多CPU,多进程,多线程,虚拟内存等等,相比多道批处理应用程序复杂了千万倍。而内存布局也随着硬件和操作系统的发展而发生了变化。但是主要的目的都是提高系统效率,提高系统稳定性安全性。提供更好的交互体验。
2 程序的编译和链接
到目前为止,我们都只是一直在谈论,程序被加载到内存然后执行的过程,而没有提及到程序是如何从我们编写的代码变为可执行文件的。在我们开始介绍现代操作系统中程序内存布局之前,先看看程序是如何被编译成可执行文件的。因为计算机的发展是和硬件,操作系统,编译器等共同发展分不开的。
2.1 编译过程
现在我们基本都是在可视环境下进行开发,比如Eclipse,VS等开发工具。这些工具功能相当的强大,我们只需专注代码的编写,点几下鼠标,一个可执行文件就被生成出来了。但是在这背后,开发工具到底做了什么呢? 下面一个简单的C程序是如何被编译成可执行文件的呢?
#include
int main()
{
printf("Hello, world.\n");
return 0;
} 一般来说,一个程序从源代码到可执行文件是通过编译器来完成的,简单的说,编译器的工作就是把高级语言转换为机器码,一个现代的编译器工作流程是:(源代码)--预处理--编译---汇编---链接--(可执行文件)。在Linux下一般使用GCC来编译C语言程序, 而VS中使用cl.exe。下图就是上面的代码在GCC中编译的过程。我们后面讨论的都以C语言为例。编译器
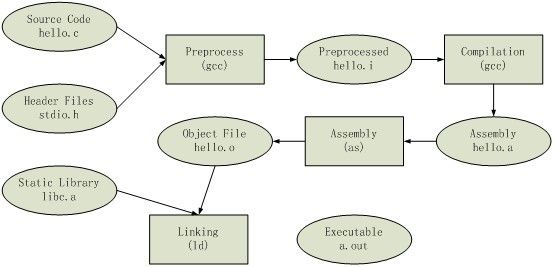
2.1.1 预处理
预处理是程序编译的第一步,以C语言为例, 预编译会把源文件预编译成一个 .I 文件。而C++则是编译成 .ii。 GCC中预编译命令如下
#gcc -E hello.c -o hello. I当我们打开hello.i 文件是会发现这个文件变的好大,因为其中包含的
# 1 "hello.c"
# 1 ""
# 1 "<命令行>"
# 1 "hello.c"
# 1 "/usr/include/stdio.h" 1 3 4
# 28 "/usr/include/stdio.h" 3 4
# 1 "/usr/include/features.h" 1 3 4
# 324 "/usr/include/features.h" 3 4
# 1 "/usr/include/i386-linux-gnu/bits/predefs.h" 1 3 4
# 325 "/usr/include/features.h" 2 3 4
# 357 "/usr/include/features.h" 3 4
# 1 "/usr/include/i386-linux-gnu/sys/cdefs.h" 1 3 4
# 378 "/usr/include/i386-linux-gnu/sys/cdefs.h" 3 4
# 1 "/usr/include/i386-linux-gnu/bits/wordsize.h" 1 3 4
# 379 "/usr/include/i386-linux-gnu/sys/cdefs.h" 2 3 4
# 358 "/usr/include/features.h" 2 3 4
# 389 "/usr/include/features.h" 3 4
# 1 "/usr/include/i386-linux-gnu/gnu/stubs.h" 1 3 4# 940 "/usr/include/stdio.h" 3 4
# 2 "hello.c" 2
int main()
{
printf("Hello, world.\n");
return 0;
} 总结下来预处理有一下作用:
- 所有的#define删除,并且展开所有的宏定义
- 处理所有的条件预编译指令,比如我们经常使用#if #ifdef #elif #else #endif等来控制程序
- 处理#include 预编译指令,将被包含的文件插入到该预编译指令的位置。这也就是为什么我们要防止头文件被多次包含。
- 删除所有注释 “//”和”/* */”.
- 添加行号和文件标识,以便编译时产生调试用的行号及编译错误警告行号。比如上面的 # 2 "hello.c" 2
- 保留所有的#pragma编译器指令,因为编译器需要使用它们。
2.1.2 编译
编译是一个比较复杂的过程。编译后产生的是汇编文件,其中经过了词法分析、语法分析、语义分析、中间代码生成、目标代码生成、目标代码优化等六个步骤。大学时有一门《编译原理》的课程就是讲这个的,只可惜当时学的并不好,感觉太枯燥太难懂了。所以当我们语法有错误、变量没有定义等问题是,就会出现编译错误。
#gcc -S hello.i -o hello.s通过上面的命令,可以从预编译文件生成汇编文件,当然也可以之际从源文件编译成汇编文件。实际上是通过一个叫做ccl的编译程序来完成的。
.file "hello.c"
.section .rodata
.LC0:
.string "Hello, world."
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $16, %esp
movl $.LC0, (%esp)
call puts
movl $0, %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu/Linaro 4.6.3-1ubuntu5) 4.6.3"
.section .note.GNU-stack,"",@progbits上面就是生成的汇编文件。我们看出其中分了好几个部分。我们只需要关注,LFB0这个段中保存的就是C语言的代码对于的汇编代码.。
2.1.3 汇编
汇编的过程比较简单,就是把汇编代码转换为机器可执行的机器码,每一个汇编语句机会都对应一条机器指令。它只需要根据汇编指令和机器指令的对照表进行翻译就可以了。汇编实际是通过汇编器as来完成的,gcc只不过是这些命令的包装。
#gcc -c hello.s -o hello.o
//或者
#as hello.s -o hello.o汇编之后生成的文件是二进制文件,所以用文本打开是无法查看准确的内容的,用二进制文件查看器打开里面也全是二进制,我们可以用objdump工具来查看:
cc@cheng_chao-nb-vm:~$ objdump -S hello.o
hello.o: file format elf32-i386
Disassembly of section .text:
00000000 :
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 83 e4 f0 and $0xfffffff0,%esp
6: 83 ec 10 sub $0x10,%esp
9: c7 04 24 00 00 00 00 movl $0x0,(%esp)
10: e8 fc ff ff ff call 11
15: b8 00 00 00 00 mov $0x0,%eax
1a: c9 leave
1b: c3 ret
上面我们看到了Main函数汇编代码和机器码对应的关系。关于objdump工具后面会介绍。这里生成的.o文件我们一般称为目标文件,此时它已经和目标机器相关了。
2.1.4 链接
链接是一个比较复杂的过程,其实链接的存在是因为库文件的存在。我们知道为了代码的复用,我们可以把一些常用的代码放到一个库文件中提供给其他人使用。而我们在使用C,C++等高级语言编程时,这些高级语言也提供了一些列这样的功能库,比如我们这里调用的printf 函数就是C标准库提供的。 为了让我们程序正常运行,我们就需要把我们的程序和库文件链接起来,这样在运行时就知道printf函数到底要执行什么样的机器码。
#ld -static crt1.o crti.o crtbeginT.o hello.o -start-group -lgcc -lgcc_eh -lc-end-group crtend.o crtn.o
我们看到我们使用了链接器ld程序来操作,但是为了得到最终的a.out可执行文件(默认生成a.out),我们加入了很多目标文件,而这些就是一个printf正常运行所需要依赖的库文件。
2.1.5 托管代码的编译过程
对于C#和JAVA这种运行在虚拟机上的语言,编译过程有所不同。 对于C,C++的程序,生成的可执行文件,可以在兼容的计算机上直接运行。但是C#和JAVA这些语言则不同。他们编译过程是相似的,但是他们最终生成的并不是机器码,而是中间代码,对于C#而言叫IL代码,对于JAVA是字节码。所以C#,JAVA编译出来的文件并不能被执行。
我们在使用.NET或JAVA时都需要安装.NET CLR或者JAVA虚拟机,以.NET为例,CLR实际是一个COM组件,当你点击一个.NET的EXE文件时,它和C++等不一样,不能直接被执行,而是有一个垫片程序来启动一个进程,并且初始化CLR组件。当CLR运行后,一个叫做JIT的编译器会吧EXE中的IL代码编译成对应平台的机器码,然后如同其他C++程序一样被执行。
有关C#程序的编译和运行可以参考之前写的: .Net学习笔记(一) ------ .NET平台结构
参考
《程序员的自我修养》
《计算机操作系统》