【sklearn】dataset模块(2)—— 生成数据集
- 本文介绍sklearn.datasets模块
- 本文是从jupyter文档转换来的,某个代码块不一定能直接复制运行,代码输出结果统一以注释形式添加在代码最后
文章目录
- 1. 生成数据集
-
- 1.1 分类和聚类生成器
-
- 1.1.1 单标签
-
- 1.1.1. make_blobs
- 1.1.1.2 make_classification
- 1.1.1.3 make_gaussian_quantiles
- 1.1.1.4 make_hastie_10_2
- 1.1.1.5 make_circles
- 1.1.1.6 make_moon
1. 生成数据集
-
前文:【sklearn】dataset模块(1)—— 玩具数据集、远程数据集 介绍了几种datasets模块自带的数据集,但有些时候我们需要自定义生成服从某些分布某些形状的数据集,这时就可以使用datasets中提供的各种随机样本的生成器,建立可控制的大小和复杂性人工数据集。
-
全部加载方法
datasets.make_biclusters datasets.make_blobs datasets.make_checkerboard datasets.make_circles datasets.make_classification datasets.make_friedman1 datasets.make_friedman2 datasets.make_friedman3 datasets.make_gaussian_quantiles datasets.make_hastie_10_2 datasets.make_low_rank_matrix datasets.make_moons datasets.make_multilabel_classification datasets.make_regression datasets.make_s_curve datasets.make_sparse_coded_signal datasets.make_sparse_spd_matrix datasets.make_sparse_uncorrelated datasets.make_spd_matrix datasets.make_swiss_roll -
常用方法
生成方法 介绍 make_blobs() 多类单标签数据集,为每个类分配一个或多个正太分布的点集 make_classification() 多类单标签数据集,为每个类分配一个或多个正太分布的点集,提供了为数据添加噪声的方式,包括维度相关性,无效特征以及冗余特征等 make_gaussian-quantiles() 将一个单高斯分布的点集划分为两个数量均等的点集,作为两类 make_hastie-10-2() 产生一个相似的二元分类数据集,有10个维度 make_circle 和 make_moom() 产生二维二元分类数据集来测试某些算法的性能,可以为数据集添加噪声,可以为二元分类器产生一些球形判决界面的数据
1.1 分类和聚类生成器
- 以下生成器将产生一个相应特征的离散矩阵
1.1.1 单标签
1.1.1. make_blobs
-
make_blobs产生多类单标签数据集,它为每个类分配服从一个或多个(每个维度)正态分布的点集,对于中心和各簇的标准偏差提供了更好的控制,可用于演示聚类。 -
方法原型
sklearn.datasets.make_blobs(n_samples=100, n_features=2, *, centers=None, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None, return_centers=False,) -
参数表
参数 类型 默认 说明 n_samples int类型 可选参数 (default=100) 总的点数,平均的分到每个clusters中。 n_features int类型 可选参数 (default=2) 每个样本的特征维度。 centers int类型 or 聚类中心坐标元组构成的数组类型 可选参数(default=3) 产生的中心点的数量, or 固定中心点位置。 cluster_std float or floats序列 可选参数 (default=1.0) clusters的标准差。 center_box 一对floats (min, max) 可选参数 (default=(-10.0, 10.0)) 随机产生数据的时候,每个cluster中心的边界。 shuffle boolean 可选参数 (default=True) 打乱样本。 -
说明:
- 一共
n_samples个数据点,每个数据点有n_features个维度,服从第i维方差为cluster_std[i]的n_features维正态分布,数据点(及其每个维度)分为centers类。每一类中心点的每一维都处于center_box给出的数轴边界内。 - 把每个簇想象成
n_features维超立方体空间中的一个立方体,它的每个维度都服从指定的正态分布
- 一共
-
示例
import numpy as np from sklearn import datasets from matplotlib import pyplot as plt my_datas = datasets.make_blobs(n_samples=1500, n_features=5, centers=3, center_box = (-10,10), cluster_std=[1.0,2.0,3.0]) x,y = my_datas plt.scatter(x[:, 0], x[:, 1], c=y, s=8) #print(x) #print(y)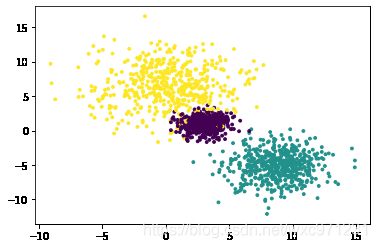
1.1.1.2 make_classification
-
make_classification产生多类单标签数据集,它为每个类分配服从一个或多个(每个维度)正态分布的点集,提供了为数据添加噪声的方式,包括维度相关性,无效特征(随机噪声)以及冗余特征等。 -
方法原型
sklearn.datasets.make_classification(n_samples=100, n_features=20, *, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None,) -
文档:
- 原文:https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html#sklearn.datasets.make_classification
- 翻译:https://blog.csdn.net/n889092/article/details/77126754
-
文档介绍:
- 生成随机的n分类问题。
- 设有
n_informative维,边长为2*class_sep的超立方体,首先创建服从关于其顶点的正态分布(标准差std = 1)的点的簇,并为每个类分配相等数量的簇,它引入了这些特征之间的相互依赖性。然后可以为数据进一步添加各种类型的噪声。 - 在不进行改组(Without shuffling)的情况下,“X”按以下顺序水平排列特征:
n_informative特征- informative特征的线性组合
n_redundant n_repeated重复项,这是从informative和redundant特征中进行替换随机绘制的。- 其余特征用随机噪声填充
- 因此,不进行改组(Without shuffling)时,所有有用的特征都包含在列
X [:,:n_informative + n_redundant + n_repeated]中。
-
参数表
参数 类型 默认 说明 n_samples int optional (default=100) 样本数量. n_features int optional (default=20) 总的特征数量, 其中包括信息特征 n_informative个,冗余特征n_redundant个,重复特征n_repeated个,其余为随机绘制的无用特征。n_informative int optional (default=2) 信息特征的数量。每个类由多个高斯簇组成,每个高斯簇都位于n_informative维子空间中超立方体的顶点周围。 对于每个簇,信息特征是独立地绘制自正态分布N(0,1),然后随机线性组合各个簇中以增加协方差。簇位于在超立方体的顶点上。 n_redundant int optional (default=2) 冗余特征的数量。这些特征是作为信息特征的随机线性组合生成的 n_repeated int optional (default=0) 重复特征的数量。这些特征是从信息特征和冗余特征中随机抽取的 n_classes int optional (default=2) 分类问题的类(或标签)数。 n_clusters_per_class int optional (default=2) 每个类的簇数量。 weights floats列表 or None (default=None) 每个类的权重,用于控制分配给每个类别的样本比例。取值为None时均匀分配,否则根据floats列表给出的比例分配(这个列表长n_classes或n_classes-1,后者会自动推断最后一个类别样本比例)。如果比例之和大于1,返回样本数量可能超过n_samples flip_y float optional (default=0.01) 随机分配类别的样本所占的比例。 较大的值会在标签中引入噪音,并使分类任务更加困难。 请注意,在某些情况下,默认设置flip_y> 0可能导致y中的类别数少于n_class。 class_sep float optional (default=1.0) 超立方体大小的乘数因子。较大的取值分散了簇/类别,使分类任务更加容易。 hypercube boolean optional (default=True) 如果为True,则将簇放置在超立方体的顶点上。 如果为False,则将簇放在随机多面体的顶点上。 shift float,array of shape [n_features] or None optional (default=0.0) 按指定值移动特征。 如果为None,则将特征移动 [-class_sep,class_sep] 中的随机值。 scale float array of shape [n_features] or None optional (default=1.0) 将特征乘以指定值进行缩放。 如果为None,则按[1,100]中随机选取的值缩放特征。 注意特征缩放是在特征移动后发生的。 shuffle boolean optional (default=True) 随机排列样本和特征。 random_state int,RandomState instance or None optional (default=None) 如果int,random_state是随机数生成器使用的种子;如果是随机状态实例,random_state是随机数生成器;如果为None,则随机数生成器是np.random使用的随机状态实例 -
示例1
import numpy as np from sklearn import datasets from matplotlib import pyplot as plt # datasets.make_classification? # 要求:n_classes * n_clusters_per_class <= 2^n_informative data1,target1 = datasets.make_classification(n_samples=100, # 样本总数 n_features=2, # 特征总数 = n_informative + n_redundant + n_repeated + 随机噪声特征 n_informative=1, n_redundant=0, n_repeated=0, n_clusters_per_class=1) # 每个类的簇数量 data2,target2= datasets.make_classification(n_samples=100, n_features=2, n_informative=1, n_redundant=0, n_repeated=1, n_clusters_per_class=1) data3,target3= datasets.make_classification(n_samples=200, n_features=2, n_informative=2, n_redundant=0, n_repeated=0, n_clusters_per_class=1) data4,target4 = datasets.make_classification(n_samples=100, # 样本总数 n_features=2, # 特征总数 = n_informative + n_redundant + n_repeated + 随机噪声特征 n_informative=2, n_redundant=0, n_repeated=0, n_classes=2, n_clusters_per_class=2) # 每个类的簇数量 fig,axes = plt.subplots(1,4) axes[0].scatter(data1[:,0],data1[:,1],c=target1) axes[1].scatter(data2[:,0],data2[:,1],c=target2) axes[2].scatter(data3[:,0],data3[:,1],c=target3) axes[3].scatter(data4[:,0],data4[:,1],c=target4) plt.show()
-
示例2
import matplotlib.pyplot as plt from sklearn.datasets import make_classification plt.figure(figsize=(10,10)) # 创建一个10 * 10 英寸的图像 plt.subplots_adjust(bottom=0.05,top=0.9,left=0.05,right=0.95) plt.subplot(221) plt.title("One informative feature, one cluster per class",fontsize='small') X1,Y1= make_classification(n_samples=1000, n_features=2, n_informative=1, n_redundant=0, n_clusters_per_class=1) plt.scatter(X1[:,0],X1[:,1],marker='o',c=Y1) plt.subplot(222) plt.title("Two informative features, two cluster per class", fontsize='small') X2,Y2 = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=2) plt.scatter(X2[:,0],X2[:,1],marker='o',c=Y2) plt.subplot(223) plt.title("Two informative features, two clusters per class", fontsize='small') X3,Y3 = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=2) plt.scatter(X3[:,0],X3[:,1],marker='o',c=Y3) plt.subplot(224) plt.title("Multi-class, two informative features, one cluster",fontsize='small') X4,Y4= make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_classes=3, n_clusters_per_class=1) plt.scatter(X4[:,0],X4[:,1],marker='o',c=Y4) plt.show()
1.1.1.3 make_gaussian_quantiles
-
make_gaussian_quantiles产生多类单标签数据集。它通过 χ 2 \chi^2 χ2 分布的分位数(quantile)将single Gaussian cluster(单高斯簇)进行近乎相等大小的同心超球面划分,生成各向同性的高斯样本及其标签。简单说,此分类数据集是从一个多维标准正态分布采样得到的,若干嵌套的同心多维球体将采样数据划分为各个类别,这种划分使每个类中的样本数量大致相等 -
方法原型
datasets.make_gaussian_quantiles(*, mean=None, cov=1.0, n_samples=100, n_features=2, n_classes=3, shuffle=True, random_state=None,) -
参数表
参数 类型 默认 说明 mean array of shape [n_features] 可选参数 (default=None) 多维正态分布的均值。如果为None,则使用原点(0,0,…) cov float 可选参数 (default=1) 该值乘以单位矩阵得到协方差矩阵。该数据集仅产生对称的正态分布 n_samples int 可选参数(default=100) 平均分散在各类别中的数据点总数 n_features int 可选参数 (default=2) 每个样本的特征数量 n_classes int 可选参数 (default=3) 类别数量 shuffle boolean 可选参数 (default=True) 打乱样本 random_state int,RandomState instance or None optional (default=None) 如果int,random_state是随机数生成器使用的种子;如果是随机状态实例,random_state是随机数生成器;如果为None,则随机数生成器是np.random使用的随机状态实例 -
示例
import numpy as np from sklearn import datasets from matplotlib import pyplot as plt # datasets.make_gaussian_quantiles? # 要求:len(mean) == n_features X,y = datasets.make_gaussian_quantiles(mean=[1,2,3], cov=2, n_samples=1000, n_features=3, n_classes=3,) fig = plt.figure(figsize = (12,6)) a0 = fig.add_subplot(1,2,1,label='a0') a0.scatter(X[:,0],X[:,1],c=y) a1 = fig.add_subplot(1,2,2,label='a1',projection='3d') #这种方法也可以画多个子图 a1.scatter(X[:,0],X[:,1],X[:,2],alpha=0.5,c=y) # alpha透明度,c颜色序列 #plt.scatter(X[:,0],X[:,1],marker='o',c=y,s=3) plt.tight_layout() plt.show()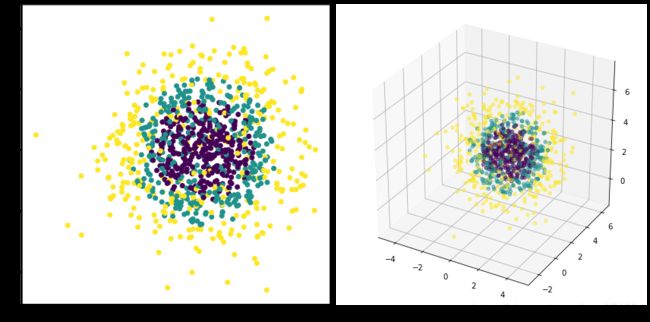
1.1.1.4 make_hastie_10_2
-
make_hastie_10_2产生一个相似的二元分类数据集,每个样本有10个维度,分别服从独立的高斯分布,样本 X[i] 的标签根据以下公式生成- 若np.sum(X[i]**2) > 9.34,y[i] = 1
- 否则 y[i] = -1
-
方法原型
datasets.make_hastie_10_2(n_samples=12000, *, random_state=None) -
示例
import numpy as np from sklearn import datasets from matplotlib import pyplot as plt my_datas = datasets.make_hastie_10_2(n_samples = 10000) X,y = my_datas plt.scatter(X[:, 0], X[:, 1], c=y, s=8)
1.1.1.5 make_circles
-
make_circles产生一个环状二分类单标签数据集。这是一个简单的玩具数据集,生成带有球面决策边界的数据,可以选择性加入高斯噪声,用于可视化聚类和分类算法。 -
方法原型
datasets.make_circles(n_samples=100, *, shuffle=True, noise=None, random_state=None, factor=0.8,) -
参数表
参数 类型 默认 说明 n_samples int or two-element tuple 可选参数 (default=100) 如果为int,则为生成的总点数(对于奇数,内圆将比外圆多一个点);如果是二元组,则为外圆和内圆中的点数。 noise double or None 可选参数 (default=None) 加入的高斯噪声的标准差 n_samples int 可选参数(default=100) 平均分散在各类别中的数据点总数 factor 0 < double < 1 可选参数 (default=0.8) 内外圆之间的比例因子 shuffle boolean 可选参数 (default=True) 打乱样本 random_state int,RandomState instance or None optional (default=None) 如果int,random_state是随机数生成器使用的种子;如果是随机状态实例,random_state是随机数生成器;如果为None,则随机数生成器是np.random使用的随机状态实例 -
示例
import numpy as np from sklearn import datasets from matplotlib import pyplot as plt # datasets.make_circles? my_datas = datasets.make_circles(n_samples=1000, noise=0.1, factor=0.8,) X,y = my_datas plt.scatter(X[:, 0], X[:, 1], c=y, s=8)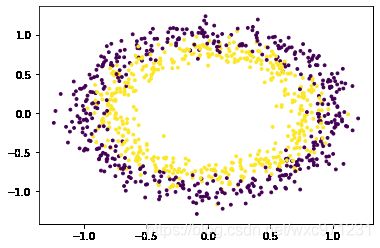
1.1.1.6 make_moon
-
make_moon产生一个月牙形单标签数据集。这是一个简单的玩具数据集,生成带有月牙形决策边界的数据,可以选择性加入高斯噪声,用于可视化聚类和分类算法。 -
方法原型
datasets.make_moons(n_samples=100, *, shuffle=True, noise=None, random_state=None) -
参数表:和
make_circles相比就少一个factor,其他一样 -
示例
import numpy as np from sklearn import datasets from matplotlib import pyplot as plt # datasets.make_moons? my_datas = datasets.make_moons(n_samples=1000, noise=0.1,) X,y = my_datas plt.scatter(X[:, 0], X[:, 1], c=y, s=8)
- 未完待续