论文翻译 —— Disambiguation-Free Partial Label Learning 非消歧偏标记学习(PL-ECOC)
- 标题:Disambiguation-Free Partial Label Learning
- 文章链接:http://aaai.org/ocs/index.php/AAAI/AAAI17/paper/view/14210
- 提出方法:PL-ECOC
- 领域:弱监督学习 - 偏标记学习
- 注:方括号为原文中参考文献引用,具体引用文章请下载原文查看
文章目录
- 非消岐偏标记学习
- 1. 引言
- 2. 相关工作
- 3. PL-ECOC方法
-
- 3.1 多分类器归纳分解为二分类器
- 3.2 使用ECOC进行偏标签学习
- 4. 实验
-
- 4.1 实验计划
- 4.2 实验结果
-
- 4.2.1 Controlled UCI数据集
- 4.2.2 真实世界数据集
- 4.3 进一步分析
-
- 4.3.1 参数敏感度
- 4.3.2 算法特性
- 4.3.3 二分类学习方法
- 5. 结论
- 句子摘抄
非消岐偏标记学习
- 摘要:在偏标签学习中,每个训练示例都与一组候选标签相关联,其中只有一个是真实标签(ground-truth label)。 引入预测模型的常见策略是尝试消除候选标签集的歧义,即区分各个候选标签的建模输出(modeling outputs)。具体地,可以通过迭代地识别真实标签或通过均等地对待每个候选标签来执行基于区分的消歧。 但是,基于消岐的策略很容易被与真相标签同时出现的伪标签误导。 在本文研究了一种新的偏标记学习策略,该策略不进行消岐。 具体而言,通过采用纠错输出码(ECOC),将候选标签集作为整体来使用,我们提出一种简单而有效的方法,称为PL-ECOC。 在训练阶段,要对每个列编码(column coding)构建二分类器,任何偏标记示例,只有在其候选标签集完全落入编码分类(coding dichotomy)时,才被视为正或负的训练示例。在测试阶段,通过基于损耗的解码( loss-based decoding)来确定未见样本的类别标签,这种解码考虑了二分类器的经验性能(empirical performance)和预测余量(predictive margin)。大量的实验表明,PL-ECOC相对于SOAT的部分标签学习方法表现出色。
1. 引言
-
偏标记(PL)学习处理的问题是,每个训练示例都与一组候选标签相关联,其中只有一个对应于真实标签[14] [26]。近年来,许多实际应用,从带有部分标签的数据中学习的需求提升了。 例如,在自动人脸命名任务中,对于新闻文档(图1(a)),可以将从新闻图片中检测到的每个人脸作为一个实例,将从关联标题中提取的那些名字作为候选标签,而每张人脸及其真实标签的关系都是未知的 [13] [35]; 在在线对象注释任务中(图1(b)),对于绘画图像,可以将Web用户在其绘画样式上的免费注释视为候选标签,而绘画图像与其地面标签之间的实际对应关系未知 [25]。偏标记学习技术还成功应用于对象分类[27]、面部年龄估计[34] [38]、生态信息学[7] 等任务。(下图为图1(b),1(a)为政治人物照片不过审)

-
形式化地说,让 X = E d \mathcal{X} = \mathbb{E}^d X=Ed 代表 d 维样本空间, Y = { y 1 , y 2 , . . . , y q } \mathcal{Y} = \{y_1,y_2,...,y_q\} Y={ y1,y2,...,yq} 是有 q q q 个类别的标记空间。训练数据集 D = { ( x i , S i ) ∣ 1 ≤ i ≤ m } \mathcal{D} = \{(x_i,S_i)|1\leq i \leq m\} D={ (xi,Si)∣1≤i≤m} 含有 m m m 个偏标记训练样例数据,其中每个样本 x i ∈ X x_i \in \mathcal{X} xi∈X 都表示为一个 d d d 维特征向量 ( x i 1 , x i 2 , . . . , x i d ) ⊤ (x_{i1},x_{i2},...,x_{id})^\top (xi1,xi2,...,xid)⊤ , S i ⊆ Y S_i \subseteq \mathcal{Y} Si⊆Y 是和 x i x_i xi 关联的候选标记集。偏标记学习的任务是利用 D \mathcal{D} D 学得多分类器 f : X ↦ Y f:\mathcal{X} \mapsto \mathcal{Y} f:X↦Y。偏标记学习中,假设样本 x i x_i xi 的真实标记 t i t_i ti 被包含于其候选标记集 S i S_i Si 中,即 t i ∈ S i t_i \in S_i ti∈Si
-
显然,部分标签学习的主要困难在于,PL训练示例的真实标签隐藏在其候选标签集中,因此学习算法无法直接访问。因此,偏标记数据中学习的一般策略是消除歧义(disambiguation),即区分单个候选标签(individual candidate labels)的建模输出,从而恢复真实标签信息。为了实现这一点,一种方法是基于辨识(identification-based)的消岐策略,这种方法以竞争性方式区分各个候选标签的建模输出,具体而言,将偏标记样本的真实标记作为隐变量,通过诸如EM [22] [26] [27] [29] [32] 之类的迭代方式优化内嵌隐变量的目标函数以实现消歧。另一种方法是基于平均 (averaging-based)的消岐策略,这种方法以协作方式区分各个候选标签的模型输出,具体而言,赋予偏标记样本的各个候选标记相同的权重,通过综合学习模型在各候选标记上的输出实现消歧。
-
尽管消歧是从偏标记数据中学习的一种直观且实用的策略,但由于伪标签(即 S i ∖ { t i } S_i\setminus\{t_i\} Si∖{ ti})在候选标签集中与真实标签同时出现,这种方式的有效性很大程度上受伪标签的影响。
- 对于基于辨识的消歧策略,每次迭代中识别出的识别标签 t i ^ \hat{t_i} ti^ 可能为对象的伪标记而非真实标记;
- 对于基于平均的消歧策略,对象真实标记的模型输出可能湮没于其伪标记的模型输出中。
此外,对于这两种消岐方法来说,随着候选标签集的大小增加,由伪标签引入的负面影响将更加明显。
-
有鉴于此,本文提出了一种从偏标记数据中学习的新策略,该策略不会通过区分各个候选标签的建模输出来进行歧义消除。具体来说,利用众所周知的纠错输出代码(ECOC)技术 [17] [40],我们提出了一种简单而有效的方法,称作 PL-ECOC,它把候选标记集视作一个整体,从而避免了使用候选标签进行消岐的问题。关键的修改在于如何根据ECOC编码矩阵训练二分类器。对于二进制编码矩阵的每一列,利用二元训练样本构建一个二分类器,这些二元训练样本是源自于偏标记训练数据集的。在这里,所有偏标记样本都用于生成二元训练数据,对于每个偏标记样本 x i x_i xi,当且仅当其候选样本集 S i S_i Si 完全落入列编码指定的正类空间或负类空间时,此样本才作为正样本或负样本加入二元训练数据集。在测试阶段,通过基于损失的解码来确定未见实例的类别标签,该解码考虑了二进制分类器的经验性能和预测余量。
-
为了彻底评估本文提出无消歧策略的有效性,我们在大量 Controlled UCI 数据集和真实的偏标记数据集上进行了广泛的实验。结果清楚地验证了 PL-ECOC 与几种公认的偏标记学习方法相比,具有优越的性能。
-
本文其他部分组织如下:第二节简要回顾了有关偏标记学习的相关工作。 第3节介绍了 PL-ECOC 方法的技术细节。第4节报告了相对于SOAT偏标记学习方法的实验比较结果。最后第5节总结并指出了未来工作的几个问题。
2. 相关工作
- 如第1节所示,PL训练样本传达的监督信息是隐含的,因为真实标签被隐藏在候选标签集中。因此,偏标签学习可以看作是带有隐含标签信息的弱监督学习框架。它位于监督学习光谱的两端之间,即具有明确监督(explicit supervision)的监督学习和具有盲监督(blind supervision)的无监督学习之间。偏标签学习与其他流行的弱监督学习框架有关,例如半监督学习,多实例学习和多标签学习。 然而,通过偏标签学习处理的弱监督信息的类型与那些问题的对应框架不同。
- 此处关于弱监督学习框架区别的介绍省略
- 现有的偏标签学习方法旨在通过消除候选标签集的歧义来完成学习任务,这可以通过两种基本方式来实现。通常,让 F ( x , y ; Θ ) F(x,y;\Theta) F(x,y;Θ) 为实例 x x x 在标签 y ∈ Y y\in \mathcal{Y} y∈Y 上的建模输出。
- 基于辨识的消岐方法将真实标签作为隐变量对待,它被识别为 t i ^ = a r g max y ∈ S i F ( x , y ; Θ ) \hat{t_i} = arg\max_{y \in S_i} F(x,y;\Theta) ti^=argmaxy∈SiF(x,y;Θ)。利用PL训练数据,基于特定准则对模型参数 Θ \Theta Θ 迭代调优,例如最大似然准则: ∑ i = 1 m l o g ( ∑ y ∈ S i F ( x i , y ; Θ ) ) \sum_{i=1}^m log(∑_{y\in S_i}F(xi,y;\Theta)) ∑i=1mlog(∑y∈SiF(xi,y;Θ)) [10] [22] [26] [27] [32] 或最大间隔准则: ∑ i = 1 m ( max y ∈ S i F ( x , y ; Θ ) − m a x y ∉ S i F ( x , y ; Θ ) ) ∑_{i=1}^m(\max_{y\in S_i} F(x,y;\Theta)− max_{y\notin S_i}F(x,y;\Theta)) ∑i=1m(maxy∈SiF(x,y;Θ)−maxy∈/SiF(x,y;Θ)) [29] [34]。
- 基于平均的消岐方法假设建模过程中每个候选标签有均等贡献。对于判别模型,将平均结果作用在所有候选标签上,即 1 ∣ S i ∣ ∑ y ∈ S i F ( x , y ; Θ ) \frac{1}{|S_i|} \sum_{y\in S_i} F(x,y;\Theta) ∣Si∣1∑y∈SiF(x,y;Θ) 区别于非候选标签的输出 F ( x , y ; Θ ) , ( S i ∖ { t i } ) F(x,y;\Theta), (S_i\setminus\{t_i\}) F(x,y;Θ),(Si∖{ ti}) [14] [31]。 对于基于实例的模型,未见样本 x ∗ x^∗ x∗ 的类标签是通过其近邻样本集合 N ( x ∗ ) \mathcal{N}(x^*) N(x∗) 中各样本候选标签投票确定的,即 f ( x ∗ ) = a r g max y ∈ Y ∑ j ∈ N ( x ∗ ) I ( y ∈ S j ) f(x^*) = arg\max_{y\in \mathcal{Y}} \sum_{j \in \mathcal{N(x^*)}}\mathbb{I}(y \in S_j) f(x∗)=argmaxy∈Y∑j∈N(x∗)I(y∈Sj) [24] [37]
- 对于任何一种消除歧义的方法,其有效性都将在很大程度上受伪标记影响,即我们需要计算伪标签的建模输出 F ( x , y ; Θ ) ( y ∈ S i ∖ { t i } ) F(x,y;\Theta) (y\in S_i\setminus\{t_i\}) F(x,y;Θ)(y∈Si∖{ ti})。在下一节中,为了规避消歧过程中的潜在问题,我们提出一种简单而有效的非消歧偏标记学习方法。
3. PL-ECOC方法
3.1 多分类器归纳分解为二分类器
- 如第1节所述,偏标记学习的最终目标是学得从实例空间到标签空间的多类分类器映射 f : X ↦ Y f:\mathcal{X} \mapsto \mathcal{Y} f:X↦Y 。对于多类分类器归纳,可以说最流行的做法是将多分类任务转换为许多二分类任务,常用的分解方式有一对余分解(one-vs-rest)或一对一分解(one-vs-one)。
- 对于一个有 q q q 个类的多分类问题,把每个类标签记作 y j ( 1 ≤ j ≤ q ) y_j(1\leq j \leq q) yj(1≤j≤q)。
- 对于一对余分解,共需构造 q q q 个二分类器,每个类标记一个。第 j j j 个二分类器时通过将类标签为 y j y_j yj 的训练样本作为正样本,其余的训练样本作为负样本来训练的。对于未见样本,把每个二分类器的输出作为预测置信度,选择具有最大输出的分类器对应的类标签作为预测标签。
- 对于一对一分解,共需构造 C 2 q = N ( N − 1 ) 2 C_2^q = \frac{N(N-1)}{2} C2q=2N(N−1) 个二分类器,每一对类标签 ( y j , y k ) ( 1 ≤ j < k ≤ ) (y_j,y_k)\space\space (1≤j
- 然而,在偏标记学习任务中,一对一分解和一对余分解都不能使用。由于PL训练样本的真实标签不能直接访问,因此不能从PL训练集中正确地推导出构建二分类器所需的训练样本。本文通过改进ECOC技术,提出了一种名为PL-ECOC的新方法,该方法不但继承了二类分解机制简单的优点,而且可以从PL训练样本中学习。
3.2 使用ECOC进行偏标签学习
-
ECOC [17] [40]基于编码-解码过程进行二类分解,是针对多分类器归纳的一种广为认可的机制。
-
编码阶段,借助具有二进制元素的 q × L q×L q×L 编码矩阵 M ∈ { + 1 , − 1 } q × L \mathrm{M}\in \{+1,-1\}^{q\times L} M∈{ +1,−1}q×L 进行学习过程。编码矩阵的每一行 M ( j , : ) \mathrm{M}(j,:) M(j,:) 对应于类标签 y j ( 1 ≤ j ≤ q ) y_j(1\leq j\leq q) yj(1≤j≤q) 的一个 L L L 位码字。编码矩阵的每一列 M ( : , l ) \mathrm{M}(:,l) M(:,l) 指定了标记空间 Y \mathcal{Y} Y 上的一个划分,正反例空间为 Y l + = { y j ∣ M ( j , l ) = + 1 , 1 ≤ j ≤ q } , Y l − = { y j ∣ M ( j , l ) = − 1 , 1 ≤ j ≤ q } \mathcal{Y}_l^+ = \{y_j|\mathrm{M}(j,l) = +1,1\leq j \leq q\},\mathcal{Y}_l^- = \{y_j|\mathrm{M}(j,l) = -1,1\leq j \leq q\} Yl+={ yj∣M(j,l)=+1,1≤j≤q},Yl−={ yj∣M(j,l)=−1,1≤j≤q}。把来自 Y l + \mathcal{Y}_l^+ Yl+ 的训练样本视为正例,来自 Y l − \mathcal{Y}_l^- Yl− 的训练样本视为负例,编码矩阵的每一列都可构造一个二分类器 h l : X ↦ R h_l:\mathcal{X} \mapsto \mathbb{R} hl:X↦R。
-
在解码阶段,给定未见样本 x ∗ x^∗ x∗,串联 L L L 个二分类器的(有符号)输出生成 L L L 位码字: h ( x ∗ ) = [ s i g n ( h 1 ( x ∗ ) ) , s i g n ( h 2 ( x ∗ ) ) , . . . , s i g n ( h L ( x ∗ ) ) ] ⊤ h(x^*)= [sign(h_1(x^*)),sign(h_2(x^*)),...,sign(h_L(x^*))]^\top h(x∗)=[sign(h1(x∗)),sign(h2(x∗)),...,sign(hL(x∗))]⊤,其中
s i g n ( z ) = { + 1 , z > 0 − 1 , o t h e r w i s e sign(z) = \left\{ \begin{aligned} +1, & & z > 0 \\ -1, & & otherwise \end{aligned} \right. sign(z)={ +1,−1,z>0otherwise
然后,返回码字(编码矩阵中一行)最接近 h ( x ∗ ) h(x^*) h(x∗) 的类标签作为对 x ∗ x^∗ x∗ 标记的最终预测,即
f ( x ∗ ) = a r g min y j d i s t ( h ( x ∗ ) , M ( j , : ) ) ( 1 ≤ j ≤ q ) (1) f(x^*) = arg\min_{y_j} dist(h(x^*),\mathrm{M}(j,:)) \space\space\space(1 \leq j\leq q) \tag 1 f(x∗)=argyjmindist(h(x∗),M(j,:)) (1≤j≤q)(1)
这里距离函数 d i s t ( ⋅ , ⋅ ) dist(·,·) dist(⋅,⋅) 可以通过各种方式实例化,例如汉明距离 [17],欧几里德距离 [30],基于损耗的距离 [2] [19] 等。
-
-
在本文中,我们展示了如何自然地扩展ECOC技术使其适用于处理偏标记数据。在编码阶段,关键的调整在于如何对每个列编码构建二分类器。具体地说,让 v = [ v 1 , v 2 , . . . , v q ] ⊤ ∈ { + 1 , − 1 } q v = [v_1,v_2,...,v_q]^\top \in \{+1,-1\}^q v=[v1,v2,...,vq]⊤∈{ +1,−1}q 代表 q q q 位列编码,每个列编码都把标记空间划分为 Y l + \mathcal{Y}_l^+ Yl+ 和 Y l − \mathcal{Y}_l^- Yl− 两部分,即
Y l + = { y j ∣ v j = + 1 , 1 ≤ j ≤ q } Y l + = Y ∖ Y l + (2) \begin{aligned} &\mathcal{Y}_l^+ = \{y_j|v_j=+1,1\leq j\leq q\} \\ &\mathcal{Y}_l^+ = \mathcal{Y} \setminus \mathcal{Y}_l^+ \end{aligned} \tag 2 Yl+={ yj∣vj=+1,1≤j≤q}Yl+=Y∖Yl+(2)
给定任意PL训练样本 ( x i , S i ) (x_i,S_i) (xi,Si),PL-ECOC不会尝试消除与 x i x_i xi 相关联的候选标签集 S i S_i Si 的歧义,而是将 S i S_i Si 视为一个整体来帮助构建二进制分类器。从这个角度看,可以从原始PL训练集 D \mathcal{D} D 导出二分类器训练集 B v \mathcal{B}_v Bv,只有当 S i S_i Si 完全落入 Y l + \mathcal{Y}_l^+ Yl+ 或 Y l − \mathcal{Y}_l^- Yl− 时, x i x_i xi 才用作正例或负例,即
B v = { ( x i , + 1 ) ∣ S i ⊆ Y l + , 1 ≤ i ≤ m } ∪ { ( x i , − 1 ) ∣ S i ⊆ Y l − , 1 ≤ i ≤ m } (3) \begin{aligned} \mathcal{B}_v = &\{(x_i,+1)|S_i \subseteq \mathcal{Y}_l^+,1 \leq i \leq m\} \cup \\ &\{(x_i,-1)|S_i \subseteq \mathcal{Y}_l^-,1 \leq i \leq m\} \end{aligned} \tag 3 Bv={ (xi,+1)∣Si⊆Yl+,1≤i≤m}∪{ (xi,−1)∣Si⊆Yl−,1≤i≤m}(3)
如上式所示,若PL训练样本的候选标签集不能完全落入 Y l + \mathcal{Y}_l^+ Yl+ 或 Y l − \mathcal{Y}_l^- Yl− ,这个样本就不会生成二分类训练示例。为了避免二分类训练集含有样本太少以至于不具有信息性(non-informative),PL-ECOC 通过控制二分类器训练集 B v \mathcal{B}_v Bv 的最小允许尺寸,对列编码 v v v 施加了一个合格条件。因此,通过在 B v \mathcal{B}_v Bv 上调用二分类学习方法 L \mathcal{L} L,可以得到一个二分类器 h l h_l hl,即 h l ← L ( B v ) h_l\gets \mathcal{L}(\mathcal{B}_v) hl←L(Bv)- 注:编码矩阵 M \mathrm{M} M 是随机生成的,但是每一列需要满足 B v \mathcal{B}_v Bv 的最小允许尺寸的限制
-
图2给出了 PL-ECOC 编码阶段的一个说明性示例。以第一个PL训练样本 ( x 1 , S 1 ) , S 1 = { y 1 , y 3 } (x_1,S_1),S_1=\{y_1,y_3\} (x1,S1),S1={ y1,y3} 为例,由于 S 1 S_1 S1 完全落入第三列编码的负类, x 1 x_1 x1 被用作第三个分类器 h 3 h_3 h3 训练的负训练样本 ;由于 S 1 S_1 S1 完全落入第五列编码的正类, x 1 x_1 x1 被用作第五个分类器 h 5 h_5 h5 训练的正训练样本。因此,如图2所示,关于每一个列编码的二分类训练数据自然遵循相应的编码矩阵和PL训练集。

-
在解码阶段,关键的调整在于如何基于分解出的二分类器 h l ( 1 ≤ l ≤ L ) h_l(1\leq l \leq L) hl(1≤l≤L) 对未见样本标签进行预测。在各种解码策略中,PL-ECOC 选择采用损失加权解码 [19],该算法利用经验性能以及分解的二分类器的预测置信度来对等式(1)进行概括。给定编码矩阵 M \mathrm{M} M,定义一个 q × L q\times L q×L 的性能矩阵 H \mathrm{H} H,其中每个元素 H ( j , l ) \mathrm{H}(j,l) H(j,l) 记录二进制分类器 h l ( 1 ≤ l ≤ L ) h_l(1\leq l \leq L) hl(1≤l≤L) 关于类别标签 y j ( 1 ≤ j ≤ q ) y_j(1\leq j \leq q) yj(1≤j≤q) 的经验性能,即
H ( j , l ) = 1 ∣ D j ∣ ∑ ( x i , S i ) ∈ D j I ( s i g n ( h l ( x i ) ) = M ( j , l ) ) w h e r e D j = { ( x i , S i ) ∣ y j ∈ S i , 1 ≤ i ≤ m } (4) \begin{aligned} &\mathrm{H}(j,l) = \frac{1}{|\mathcal{D_j}|} \sum_{(x_i,S_i)\in \mathcal{D_j}} \mathbb{I(sign(h_l(x_i))=\mathrm{M}(j,l))} \\ &where \space\space\space \mathcal{D_j} = \{(x_i,S_i)|y_j \in S_i,1\leq i \leq m\} \end{aligned} \tag 4 H(j,l)=∣Dj∣1(xi,Si)∈Dj∑I(sign(hl(xi))=M(j,l))where Dj={ (xi,Si)∣yj∈Si,1≤i≤m}(4)
其中 ∣ ⋅ ∣ |·| ∣⋅∣ 返回一个集合的基数, I ( ⋅ ) \mathbb{I}(·) I(⋅) 当等号中条件 ⋅ · ⋅ 成立时返回 1,否则返回 0 -
如式(4)所示, D j \mathcal{D}_j Dj 由候选标签集包含类标签 y j y_j yj 的PL训练样本组成。因此 H ( j , l ) \mathrm{H}(j,l) H(j,l) 记录 D j D_j Dj 包含的样本中由二分类器 h l h_l hl 产生的预测类别与二进制编码 M ( j , l ) \mathrm{M}(j,l) M(j,l) 一致的样本的比例。例如,要获得上面图2中的经验性能 H ( 2 , 4 ) \mathrm{H}(2,4) H(2,4) , D 2 \mathcal{D}_2 D2 含有三个偏标记样本 { ( s 2 , S 2 ) , ( s 5 , S 5 ) , ( s 6 , S 6 ) } \{(s_2,S_2),(s_5,S_5),(s_6,S_6)\} { (s2,S2),(s5,S5),(s6,S6)} ,它们的候选标记集合都包含 y 2 y_2 y2。假设二分类器 h 4 h_4 h4 将 D 2 \mathcal{D}_2 D2 中的例子分类为: h 4 ( x 2 ) = + 1 h_4(x_2) = +1 h4(x2)=+1, h 4 ( x 5 ) = − 1 h_4(x_5)=−1 h4(x5)=−1, h 4 ( x 6 ) = − 1 h_4(x_6)=−1 h4(x6)=−1,由于编码矩阵中 M ( 2 , 4 ) = − 1 \mathrm{M}(2,4) = -1 M(2,4)=−1 那么经验性能 H ( 2 , 4 ) = 0 + 1 + 1 3 = 0.67 \mathrm{H}(2,4) = \frac{0+1+1}{3} = 0.67 H(2,4)=30+1+1=0.67 。
-
为了考虑每个二分类器的相对性能,可以通过将 H \mathrm{H} H 的每一行归一化来生成权重矩阵 H ^ \hat{\mathrm{H}} H^,即
H ^ ( j , l ) = H ( j , l ) ∑ l = 1 L H ( j , l ) ( 1 ≤ j ≤ q , 1 ≤ l ≤ L ) (5) \hat{\mathrm{H}}(j,l) = \frac{\mathrm{H}(j,l)}{\sum_{l=1}^L\mathrm{H}(j,l)} \space\space\space(1\leq j \leq q,1\leq l \leq L) \tag 5 H^(j,l)=∑l=1LH(j,l)H(j,l) (1≤j≤q,1≤l≤L)(5)
给定未见样本 x ∗ x^∗ x∗,其类标签由以下损失加权解码规则预测:
f ( x ∗ ) = a r g min y j ∑ l = 1 L H ^ ( j , l ) e x p ( − h l ( x ∗ ) ⋅ M ( j , l ) ) ( 1 ≤ j ≤ q ) (6) f(x^*) = arg\min_{y_j} \sum_{l=1}^L \hat{\mathrm{H}}(j,l) exp(-h_l(x^*)·\mathrm{M}(j,l)) \space\space\space (1\leq j \leq q) \tag 6 f(x∗)=argyjminl=1∑LH^(j,l)exp(−hl(x∗)⋅M(j,l)) (1≤j≤q)(6)
如等式(6)所示,通过二分类器的预测置信度 h l ( x ∗ ) h_l(x^∗) hl(x∗) 和码字位 M ( j , l ) \mathrm{M}(j,l) M(j,l) 之间的加权指数损失来测量。- 注:与基于汉明距离的流行解码规则相比: f ( x ∗ ) = a r g min y j ∑ l = 1 L I ( h l ( x ∗ ) ≠ M ( j , l ) ) f(x^*) = arg\min_{y_j} \sum_{l=1}^L \mathbb{I}(h_l(x^*)\neq \mathrm{M}(j,l)) f(x∗)=argminyj∑l=1LI(hl(x∗)=M(j,l)) ,(6) 式给出的加权解码规则旨在利用二分类器的经验性能(即 H \mathrm{H} H)来产生更好的解码结果。
-
表1总结了所提出的PL-ECOC方法的完整编码阶段(步骤1至11)和解码阶段(步骤12至15)。在编码阶段,随机生成一个潜在的列编码 v v v(步骤3),一旦列资格条件满足后(步骤6),将接受潜在的编码 v v v 来实例化编码矩阵 M \mathrm{M} M 的一个新列(步骤7至8),然后构造相应的二进制分类器(步骤9)。在解码阶段,根据构造的二分类器的经验性能计算出权重矩阵 H ^ \hat{\mathrm{H}} H^(步骤12至13)。之后,根据损失加权解码规则预测未见样本的类标签(步骤14至15)。

-
如表1所示,PL-ECOC 对候选标签集没有任何消歧的操作,而是以综合的方式进行处理。PL-ECOC继承了标准ECOC机制的优点,概念简单,可以适用各种二分类学习方法 L \mathcal{L} L。如下一节所述,PL-ECOC的性能与SOAT偏标记学习方法相比具有很高的竞争力。
4. 实验
4.1 实验计划
-
为了全面评估 PL-ECOC 的性能,分别对Controlled UCI数据集 [4] 和实际PL数据集进行了两个系列实验。 表2总结了实验数据集的特征
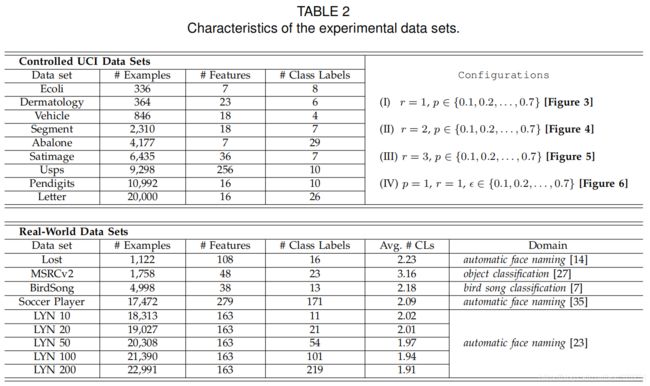
-
遵循在偏标记研究中广泛使用的控制协议 [10] [14] [27] [34] [37],可以从多类UCI数据集中生成人工PL数据集,具有三个控制参数 p , r , ϵ p,r,\epsilon p,r,ϵ,其中 p p p 控制偏标记样本的比例(即 ∣ S i ∣ > 1 |S_i|> 1 ∣Si∣>1), r r r 控制每个偏标记样本候选标签中伪标签的数量(即 ∣ S i ∣ = r + 1 |S_i|=r+1 ∣Si∣=r+1), ϵ \epsilon ϵ 控制一个耦合候选标签和真实标签之间的同时出现概率。如表2所示,对于九个多类UCI数据集的每一个,已经考虑了总共 28(4×7)个控制参数配置用于人工PL数据集的生成。
-
此外,从几个任务域被收集到一些真实世界的 PL 数据集,包括Lost [14], Soccer Player [35], LYN (Labeled Yahoo! News) [23] from automatic face naming, MSRCv2 [27] from object classification, and BirdSong [7] from bird song classification 。对于自动人脸命名的任务,从图像或视频中裁剪出来的人脸被表示为样本,从相关的标题或字幕中提取出来的名称被视为候选标签。具体来说,通过保留 “ Yahoo!” 新闻数据集[23] 标签中的出现次数最多的名字 ,生成了五个版本的LYN数据集(称为 L Y N N u m ; N u m ∈ { 10 、 20 、 50 、 100 、 200 } LYN\space\space Num;Num \in \{10、20、50、100、200\} LYN Num;Num∈{ 10、20、50、100、200})。对于对象分类任务,分割的图像表示为样本,而出现在同一图像中的对象视为候选标签。在鸟类歌曲分类的任务中,鸟类的歌唱音节作为样本,而鸟类在10秒的时间内共同歌唱则被视为候选标签。每个真实世界的PL数据集候选标签的平均数量 (Avg. #CLs) 也记录在表2中。
-
比较研究采用了四种SOAT偏标记学习算法,每种算法在实现时都采用了各自文献中建议的参数设置:
- PL-KNN [24]: 一种基于k最近邻的局部标签学习方法,是基于平均的消岐方法 [suggested setup: k = 10]
- CLPL [14]:一种用于偏标记学习的判别方法,是基于平均的消岐方法 [suggested setup: SVM with squared hinge loss(使用平均合页损失的SVM)];
- PL-SVM [29]:用于偏标记学习的最大余量方法,是基于辨识的消岐方法 [suggested setup: regularization parameter pool with { 1 0 − 3 , . . . , 1 0 3 } \{10^{-3},...,10^3\} { 10−3,...,103}];
- LSB-CMM [27]:一种偏标记学习的最大似然方法,是基于辨识的消岐方法 [suggested setup: #mixture components = q].
-
对于PL-ECOC,二分类学习方法 L \mathcal{L} L 选用 Libsvm [8],而资格参数 τ \tau τ 设置为PL训练样本数量的十分之一(即 1 10 ∣ D ∣ \frac{1}{10} |\mathcal{D}| 101∣D∣)。此外,PL-ECOC的码字长度 L L L 设置为 ⌈ 10 ⋅ l o g 2 ( q ) ⌉ \lceil 10·log_2(q)\rceil ⌈10⋅log2(q)⌉ ,这和ECOC的通常设定一致 [2] [30] [40]。在本文中,对每个人工和真实PL数据集进行10折交叉验证。相应地记录所有用作比较的算法的平均预测精度(以及标准差)。
4.2 实验结果
4.2.1 Controlled UCI数据集
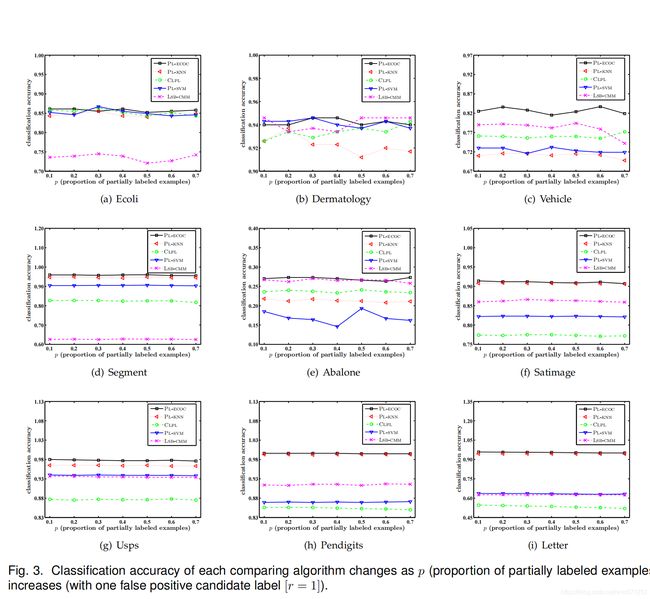
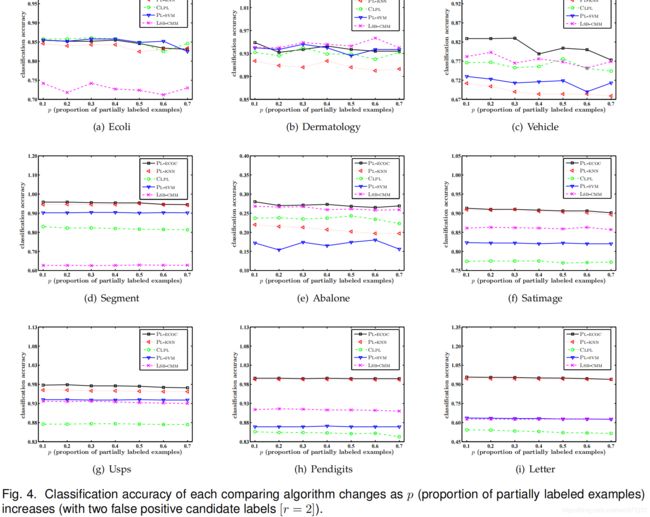
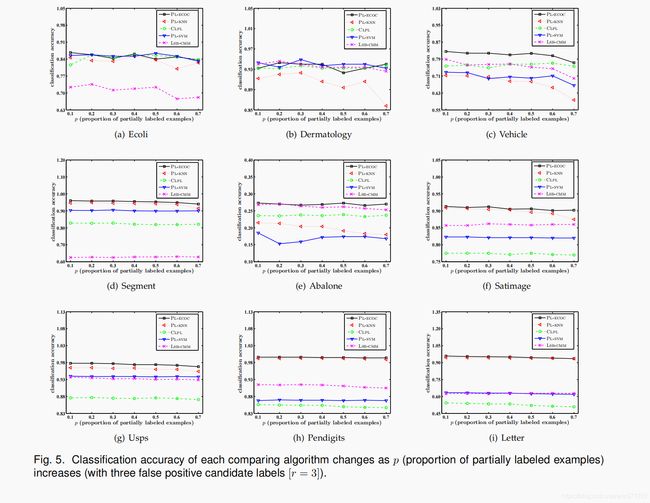
- 图3到5说明了每个比较算法的平均预测精度,参数 p p p 取值为 0.1 至 0.7,步进 0.1( r = 1 , 2 , 3 r = 1,2,3 r=1,2,3)。除了真实标签之外,将随机选择 Y \mathcal{Y} Y 中的 r r r 个附加类标签,以实例化每个偏标记样本的候选标签集。图6说明了每个用作比较的算法的平均预测精度,参数 ϵ \epsilon ϵ 取值为 0.1 至 0.7,步进 0.1( p = 1 , r = 1 p = 1,r=1 p=1,r=1)。对于任何真实标签 y ∈ Y y \in \mathcal{Y} y∈Y ,一个伪标签 y ′ ≠ y y' \neq y y′=y 以 ϵ \epsilon ϵ 概率被指定为候选标签集中与 y y y 同时出现的耦合标签。除此以外,将随机选择任何其他类标签来与 y y y 共存。
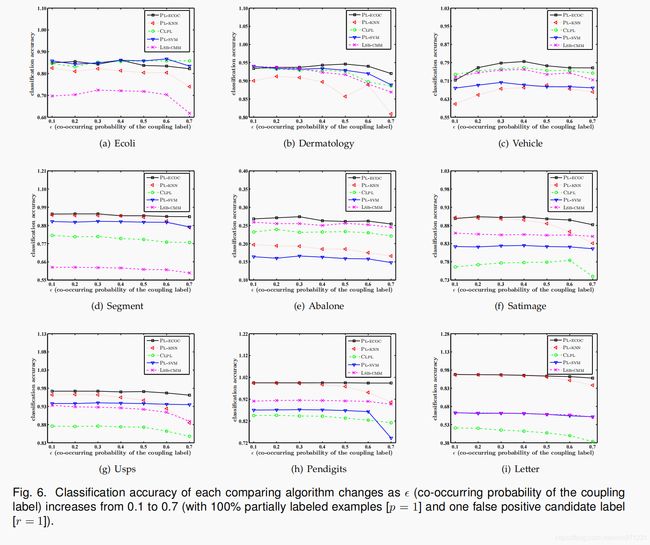
-
如图3至6所示,PL-ECOC 的性能与比较算法具有具竞争力。基于在显著性水平为0.05的 Wilcoxon signed ranks test [16] [33],表3总结了 PL-ECOC 和每个比较算法之间的输赢结果。
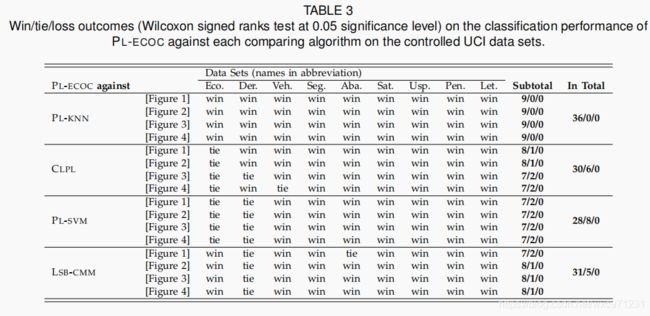
在这里,每个统计测试都是依据每个图中的7个配置执行的。根据36项统计测试的结果 (4 figures × 9 UCI data sets),可进行以下观察:
- 在所有控制参数配置和人工PL数据集中,没有一个比较算法能够明显优于PL-ECOC
- 与基于平均的消岐方法相比,PL-ECOC在100%的案例(36个案例中的36个)和83.3%的案例(36个案例中的30个)中均达到了相对优于 PL-KNN 和 CLPL 的性能
- 与基于辨识的消岐方法相比,PL-ECOC 在77.8%(36个案例中的28个)和 86.1%案例(36个案例中的31个)中均达到了相对优于 PL-SVM 和 LSB-CMM 的性能
4.2.2 真实世界数据集
- 表4报告了每个比较算法在真实PL数据集上的性能,其中还记录了在0.05显着性水平下成对 t 检验的结果。

令人印象深刻的是:- 在 BirdSong,LYN 50 和 LYN 200 数据集上,PL-ECOC的性能优于所有比较算法。
- 在足球运动员,LYN 20和LYN 100数据集上,PL-ECOC的表现可与LSB-CMM媲美,并且优于其他比较算法。 在MSRCv2数据集上,PL-ECOC的性能可与PL-SVM媲美,并且优于其他比较算法;
- 在 Loat 数据集上,PL-ECOC的性能不如CLPL,与PL-SVM和LSB CMM相当,并且优于PL-KNN。 在LYN 10数据集上,PL-ECOC的性能低于LSB CMM,可与PL-SVM媲美,并且优于PL-KNN和CLPL
4.3 进一步分析
4.3.1 参数敏感度
-
本小节对提出的 PL-ECOC 方法的性能关于参数的敏感性进行进一步的分析。
-
如表1所示,码字长度 L L L 是基于ECOC的学习方法的一个关键参数。图7(a)说明了PL-ECOC在不同码字长度下的性能如何变化 ( L = ⌈ k ⋅ l o g 2 ( q ) ⌉ , k ∈ { 1 , 2 , . . . , 15 } L = \lceil k·log_2(q)\rceil,k\in\{1,2,...,15\} L=⌈k⋅log2(q)⌉,k∈{ 1,2,...,15})。为了简单起见,这里使用了 MSRCv2、BirdSong 和 LYN100 数据集来进行说明,也可以在其他数据集上进行类似的观察。如图7(a)所示,PL-ECOC的性能随着码字长度 L L L 的提高而增大,并且在 L L L 接近 ⌈ 10 ⋅ l o g 2 ( q ) ⌉ \lceil 10·log_2(q)\rceil ⌈10⋅log2(q)⌉ 区域稳定。因此,4.1小节中为 PL-ECOC 指定的参数为 L = ⌈ 10 ⋅ l o g 2 ( q ) ⌉ L= \lceil 10·log_2(q)\rceil L=⌈10⋅log2(q)⌉
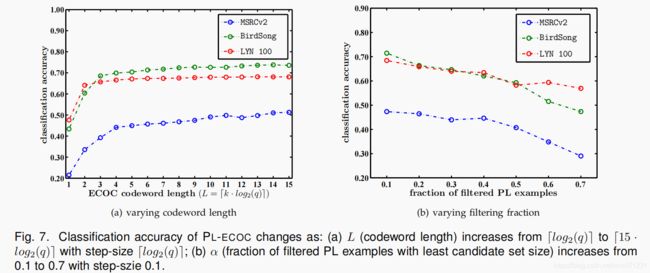
-
此外,根据等式(3)所述,如果某PL训练样本的候选标记集不能完全落入某列编码划分的正类空间或负类空间,此样本将被排除在根据该列编码生成的二分类训练集之外。设 S a ⊆ Y S^a \subseteq \mathcal{Y} Sa⊆Y 表示由 a a a 个候选标签组成的候选标签集,而 Y v + ( Y v − ) \mathcal{Y}_v^+ (\mathcal{Y}_v^-) Yv+(Yv−) 表示一个 q q q 位列编码 v ∈ { + 1 , − 1 } q v \in \{+1,-1\}^q v∈{ +1,−1}q 在 Y \mathcal{Y} Y 上划分的正(负)类空间。假设 S a S^a Sa 和 v v v 都来自均匀分布,那么 S a S^a Sa 完全落入正(负)类空间的概率对应于:
P ( ( S a ⊆ Y v + ) ∨ ( S a ⊆ Y v − ) ) = 1 − P ( ( S a ∩ Y v + ≠ ϕ ) ∧ ( S a ∩ Y v − ≠ ϕ ) ) = 1 − 1 2 q ⋅ ( q a ) ∑ t = 0 q ( q t ) ∑ u = m a x ( 1 , a − ( q − t ) ) m i n ( a − 1 , t ) ( t u ) ( q − t a − u ) (7) \begin{aligned} &\mathbb{P}((S^a \subseteq\mathcal{Y}_v^+) \lor (S^a \subseteq\mathcal{Y}_v^-)) \\ &= 1 - \mathbb{P}((S^a \cap \mathcal{Y}_v^+ \neq \phi) \land (S^a \cap \mathcal{Y}_v^- \neq \phi)) \\ &= 1-\frac{1}{2^q·{q\choose a}} \sum_{t=0}^q {q \choose t} \sum_{u = max(1,a-(q-t))}^{min(a-1,t)} {t \choose u} {q-t \choose a-u} \end{aligned} \tag 7 P((Sa⊆Yv+)∨(Sa⊆Yv−))=1−P((Sa∩Yv+=ϕ)∧(Sa∩Yv−=ϕ))=1−2q⋅(aq)1t=0∑q(tq)u=max(1,a−(q−t))∑min(a−1,t)(ut)(a−uq−t)(7)
这里 2 q ⋅ ( q a ) 2^q·{q\choose a} 2q⋅(aq) 代表 S a S^a Sa 和 v v v 联合取值的总数,求和项计算同时和 Y v + , Y v − \mathcal{Y}_v^+ ,\mathcal{Y}_v^- Yv+,Yv− 相交的 S a S^a Sa 数量,基于组合数计算公式 ( n k ) = n ! k ! ( n − k ) ! {n \choose k} = \frac{n!}{k!(n-k)!} (kn)=k!(n−k)!n!,(7)式可化简为
P ( ( S a ⊆ Y v + ) ∨ ( S a ⊆ Y v − ) ) = 1 − 1 2 q ∑ t = 0 q ∑ u = m a x ( 1 , a − ( q − t ) ) m i n ( a − 1 , t ) ( a u ) ( q − a t − u ) (8) \begin{aligned} &\mathbb{P}((S^a \subseteq\mathcal{Y}_v^+) \lor(S^a \subseteq\mathcal{Y}_v^-)) \\ &= 1-\frac{1}{2^q} \sum_{t=0}^q\sum_{u=max(1,a-(q-t))}^{min(a-1,t)} {a \choose u} {q-a \choose t-u} \end{aligned} \tag 8 P((Sa⊆Yv+)∨(Sa⊆Yv−))=1−2q1t=0∑qu=max(1,a−(q−t))∑min(a−1,t)(ua)(t−uq−a)(8)
具体而言,概率 P ( ( S a ⊆ Y v + ) ∨ ( S a ⊆ Y v − ) ) \mathbb{P}((S^a \subseteq\mathcal{Y}_v^+) \lor(S^a \subseteq\mathcal{Y}_v^-)) P((Sa⊆Yv+)∨(Sa⊆Yv−)) 在 a = 1 a = 1 a=1时取最大值1,在 a = q a = q a=q 时取最小值 2 1 − q 2^{1-q} 21−q -
如表1(PL_ECOC伪代码)所示,考虑到候选标签集不完全落入某一类的可能性,PL-ECOC使用了一个资格参数 τ \tau τ 来避免用少数例子生成信息不足的(non-informative)二分类训练集。表5报告了 PL-ECOC 在 MSRCv2、BirdSong 和 LYN100 数据集上的性能,其中 τ \tau τ 和训练集的大小成比例,即 τ = η ⋅ ∣ D ∣ , ( η ∈ { 0.1 , 0.2 , 0.3 , 0.4 } ) \tau=η·|\mathcal{D}|,(η \in \{0.1,0.2,0.3,0.4\}) τ=η⋅∣D∣,(η∈{ 0.1,0.2,0.3,0.4})。如表5所示,PL-ECOC 的性能通常对 τ \tau τ 值的变化并不敏感。因此,第4.1小节中为 PL-ECOC 指定的其他参数配置对应于 τ = 0.1 ⋅ ∣ D ∣ \tau=0.1·|\mathcal{D}| τ=0.1⋅∣D∣
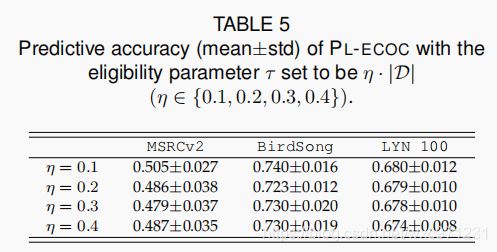
-
一旦满足资格条件 ∣ B v ∣ ≥ τ |\mathcal{B}_v| \geq \tau ∣Bv∣≥τ,二分类训练集的大小将与原始偏标记训练集的大小成正比。为了展示 PL-ECOC在不同训练集大小下的表现,表6报告了每个比较算法在MSRCv2、BirdSong 和 LYN100采样子集上,采样率 r ( r ∈ { 30 % , 45 % , 60 % , 75 % , 90 % } ) r(r\in\{30\%,45\%,60\%,75\%,90\%\}) r(r∈{ 30%,45%,60%,75%,90%}) 的性能。
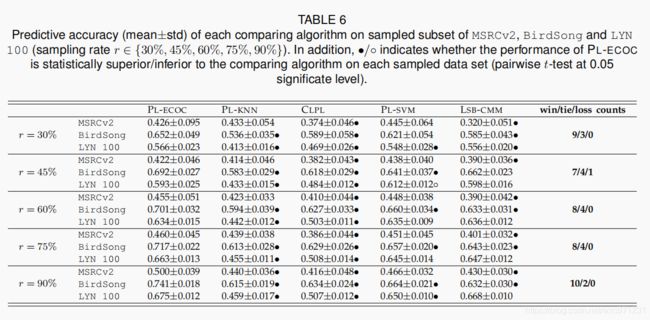
如表6所示,在不同的采样率下,PL-ECOC 保持了其相对比较算法的性能优势。具体地说,一般的趋势是,随着采样率的增加,该优势变得更加明显(从=45%开始)。
4.3.2 算法特性
-
在本小节中,将进一步分析所提出的PL-ECOC 方法的几种算法特性。
-
如图3到5所示,在某些情况下,当 p p p(偏标记样本的比例)增加时,在Controlled UCI数据集上比较算法的性能未达到预期的降低,相关文献也报道了类似的观察结果[27] [34],这有些令人惊讶。造成这种违反直觉的趋势的原因之一可能在于用于UCI数据集的控制协议(controlling protocol),其中具有唯一标记的 ( 1 − p ) × 100 % (1-p)\times 100\% (1−p)×100% 训练样本对构造的预测模型的泛化能力起重要作用。此外,值得注意的是,Controlled UCI数据集是人为生成的,其特征不会像现实世界中的PL数据集那样具有代表性。
-
图7(b)说明了当从数据集中去除 α × 100 % \alpha \times 100\% α×100% 的具有最小的候选标签集大小的偏标记样本时,PL-ECOC的性能如何变化 ( α ∈ { 0.1 , 0.2 , . . . , 0.7 } ) (\alpha \in \{0.1,0.2,...,0.7\} ) (α∈{ 0.1,0.2,...,0.7})。很明显,随着过滤后的数据集的平均候选标签(average candidate labels)越来越多,导致PL学习任务的难度的增加。在MSRCv2、BirdSong 和 LYN100 数据集上,PL-ECOC 的性能如预期一样下降。
-
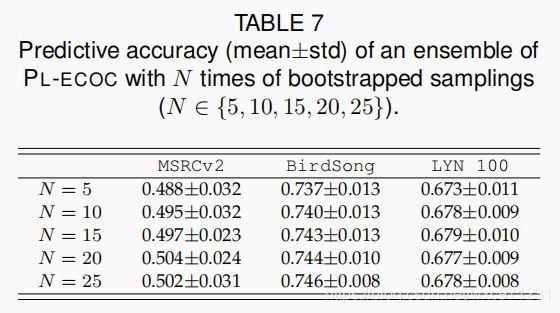
PL-ECOC 可以被视为一种集成学习方法,它利用了一些关于列编码的基础二分类器产生预测模型。有趣的是,也可以通过把提出的方法视为基础学习器,将集成学习技术应用于PL-ECOC。 具体来说,表7报告了基于流行的 bagging 技术[5] [40] 的 PL-ECOC 集成学习的性能,其中,预测模型是通过组合N个 PL-ECOC 分类器而建立的,每个分类器都是从原始训练集的一个自举采样(bootstrapped sampling)中得出的 ( N ∈ { 5 , 10 , 15 , 20 , 25 } ) ( N\in\{5,10,15,20,25\}) (N∈{ 5,10,15,20,25}) 。 如表7所示,在MSRCv2,BirdSong 和 LYN 100 数据集上,PL-ECOC集合的性能随集合大小的变化而没有显着变化,这与表4所示的普通PL-ECOC类似。 这些结果表明,PL-ECOC是稳定的学习器[6] [40],其学习过程对训练集上的扰动不太敏感。
-
表8还报告了PL-ECOC的运行时间(单位为秒),以及在配备 Inteli7-6700CPU 的 Matlab 环境中测量的比较算法运行时间。如表8所示,在 MSRCv2 和 BirdSong 这种中型数据集上,PL-ECOC 的计算复杂度接近或低于大多数比较算法 (CLPL、PL-SVM、LSB-CMM),但在 LYN100 这种大型数据集上,由于码字长度增长和较大的二分类训练集大小,PL-ECOC 的计算复杂度相比比较算显著增大。

4.3.3 二分类学习方法
-
在第4.1小节中给出的四种比较算法中,其中三种是针对具体的学习技术而定制的。具体来说,PL-KNN,PL-SVM 和 LSB-CMM 分别采用 k-最近邻[1]、支持向量机[15] 和非参数贝叶斯[20] 来拟合偏标记训练样本。另一方面,CLPL 的工作方式与 PL-ECOC 类似,它将原始的偏标记学习问题转化为二元学习问题,这样任何二元学习方法都可以被使用。具体地说,CLPL通过聚合所有候选标签,将每个PL训练样本 ( x i , S i ) ∈ D (x_i,S_i)\in \mathcal{D} (xi,Si)∈D 转换为一个正样本以及 q − ∣ S i ∣ q-|S_i| q−∣Si∣ 个负样本(每个非候选标签对应一个)
-
考虑到 PL-ECOC 和 CLPL 都依赖于二分类学习方法 L \mathcal{L} L 的选择来实例化学习算法,表9报告了选择不同的基础学习方法实例化的 PL-ECOC 和 CLPL 在 MSRCv2、BirdSong 及 LYN100 数据集上的性能,基础的二元学习算法包括 L ∈ { S V M , L o g i s t i c R e g r e s s i o n ( L R ) , P e r c e p t r o n ( P T ) } \mathcal{L} \in \{SVM,Logistic Regression(LR),Perceptron (PT)\} L∈{ SVM,LogisticRegression(LR),Perceptron(PT)}。如表9所示,基础学习方法的选择对这两种算法的性能都有显著的影响。此外,PL-ECOC 在使用SVM和感知器作为基础学习方法时的表现明显优于CLPL,而在在使用逻辑回归作为基础学习方法时次于 CLPL。

-
总结:基于4.3.1至4.3.3节所做的分析,可以对 PL-ECOC 的有效性进行以下观察:
- PL-ECOC对于码字长度参数 L L L(图7(a))和资格参数 τ \tau τ(表5)不敏感
- PL-ECOC与比较算法的性能优势(表6)
- PL-ECOC是稳定的学习方法,对训练集的干扰有鲁棒性(表7)
- 基础学习者的选择对PL-ECOC的性能有显著影响(表9)
5. 结论
- 现有的偏标记学习方法旨在通过消除PL候选标签集的歧义,从PL训练样本中学习。在本文中,我们提出了一个初步研究 [36] 的扩展,可以非消岐地从PL训练样例中学习。具体来说,通过调整流行的ECOC技术,把候选标签集作为一个整体来使用,我们提出了一种新的偏标记学习方法 PL-ECOC。全面的实验研究表明,非消岐策略是从偏标记数据中学习的一个有前途的方向
- 对于每个列编码,都有一些PL训练样本不能用于生成相应的二分类训练集(等式(3))。因此,研究充分利用那些被排除的PL训练样本的有效方法是很有趣的。此外,当PL训练示例的部分标签集表现出某些结构时(例如在类标签上的序数结构(ordinal structure),则需要研究随机策略以外的编码策略 [34])。 将来,探索其他实现非消岐的部分标签学习技术也很重要。
句子摘抄
- Nonetheless, the disambiguation strategy is prone to be misled by the false positive labels co-occurring with ground-truth label
但是,基于消岐的策略很容易被与真相标签同时出现的伪标签误导 - In this paper, a new partial label learning strategy is studied which refrains from conducting disambiguation
本文研究了一种新的偏标记学习策略,该策略不进行消岐 - Specifically, by adapting error-correcting output codes (ECOC), a simple yet effective approach named PL-ECOC is proposed by utilizing candidate label set as an entirety.
具体而言,通过采用纠错输出码(ECOC),将候选标签集作为整体来考虑,我们提出一种简单而有效的方法,称为PL-ECOC - Extensive experiments show that PL-ECOC performs favorably against state-of-the-art partial label learning approaches.
大量的实验表明,PL-ECOC相对于最新的部分标签学习方法表现出色 - Furthermore, for either of the two disambiguation ways, the negative influence introduced by false positive labels would be more pronounced as the size of candidate label set increases.
此外,对于这两种消岐方法来说,随着候选标签集的大小增加,由伪标签引入的负面影响将更加明显。 - During testing phase, class label of the unseen instance is determined via loss-based decoding which takes into account binary classifiers’ empirical performance and predictive margin.
在测试阶段,通过基于损失的解码来确定未见实例的类别标签,该解码考虑了二进制分类器的经验性能和预测余量。 - In the next section, to circumvent potential issues encountered during disambiguation, a simple yet effective disambiguation-free partial label learning approach is proposed.
在下一节中,为了规避消歧过程中遇到的潜在问题,我们提出一种简单而有效的非消歧偏标记学习方法。 - As a well-established mechanism towards multi-class classifier induction, ECOC conducts binary decomposition based on a coding-decoding procedure
ECOC 基于编码-解码过程进行二类分解,是针对多分类器归纳的一种广为认可的机制 - To avoid non-informative binary training set with few examples, PL-ECOC enforces an eligibility condition on the column coding v by controlling the minimum admissible size of Bv.
为了避免二分类训练集含有样本太少以至于不具有信息性,PL-ECOC 通过控制二分类器训练集 Bv 的最小允许尺寸,对列编码 v v v 施加了一个合格条件。 - Therefore, H(j,l) records the fraction of examples in Dj whose binary predictions yielded by hl coincide with the binary coding M(j,l)
因此 H ( j , l ) \mathrm{H}(j,l) H(j,l) 记录 D j D_j Dj 包含的样本中由二分类器 h l h_l hl 产生的预测类别与二进制编码 M ( j , l ) \mathrm{M}(j,l) M(j,l) 一致的样本的比例 - To account for the relative performance of each binary classifier, a weight matrix H ^ \hat{\mathrm{H}} H^ can be generated by normalizing each row of H \mathrm{H} H
为了考虑每个二分类器的相对性能,可以通过将 H \mathrm{H} H 的每一行归一化来生成权重矩阵 H ^ \hat{\mathrm{H}} H^ - As shown in Table 1, PL-ECOC is free of any disambiguation operation towards the candidate label set which instead is treated in an integrative manner.
如表1所示,PL-ECOC对候选标签集没有任何消歧的操作,而是以综合的方式进行处理。 - As reported in the next section, the performance of PL-ECOC is highly competitive against state-of-the-art partial label learning approaches.
如下一节所述,PL-ECOC的性能与最先进的偏标记学习方法具有很高的竞争力。 - in this paper, ten-fold cross validation is performed over each artificial as well as real-world PL data set.
在本文中,对每个人工和真实PL数据集进行10折的交叉验证 - In this subsection, performance sensitivity of the proposed PL-ECOC approach w.r.t. its parameters will be further analysed.
本小节对提出的 PL-ECOC 方法的性能关于参数的敏感性进行进一步的分析 - For the sake of simplicity, MSRCv2, BirdSong and LYN 100 are employed here for illustrative purpose while similar observations can be made on other data sets.
为了简单起见,这里使用了MSRCv2、BirdSong和LYN100数据集来进行说明,也可以在其他数据集上进行类似的观察 - Interestingly, one can also apply ensemble learning techniques to PL-ECOC by treating the proposed approach as the base learner
有趣的是,也可以通过把提出的方法视为基础学习器,将集成学习技术应用于PL-ECOC - Comprehensive experimental studies show that disambiguation-free strategy is a promising direction for learning from partial label data
全面的实验研究表明,非消岐策略是从偏标记数据中学习的一个有前途的方向