spark mllib 入门学习(二)--LDA文档主题模型
http://www.aboutyun.com/thread-22359-1-1.html
问题导读:
2.LDA 建模算法是什么样的?
3.spark MLlib中的LDA模型如何调优?
4.运行LDA有哪些小技巧?

上次我们简单介绍了聚类算法中的 KMeans算法 ,并且介绍了一个简单的KMeans的例子,本次按照我的计划,我想分享的是聚类算法中的LDA文档主题模型,计划从下次开始分享回归算法。
什么是LDA主题建模?
隐含狄利克雷分配(LDA,Latent Dirichlet Allocation)是一种主题模型(Topic Model,即从所收集的文档中推测主题)。 甚至可以说LDA模型现在已经成为了主题建模中的一个标准,是实践中最成功的主题模型之一。那么何谓“主题”呢?,就是诸如一篇文章、一段话、一个句子所表达的中心思想。不过从统计模型的角度来说, 我们是用一个特定的词频分布来刻画主题的,并认为一篇文章、一段话、一个句子是从一个概率模型中生成的。也就是说 在主题模型中,主题表现为一系列相关的单词,是这些单词的条件概率。形象来说,主题就是一个桶,里面装了出现概率较高的单词(参见下面的图),这些单词与这个主题有很强的相关性。
LDA可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
LDA可以被认为是如下的一个聚类过程:
(1)各个主题(Topics)对应于各类的“质心”,每一篇文档被视为数据集中的一个样本。
(2)主题和文档都被认为存在一个向量空间中,这个向量空间中的每个特征向量都是词频(词袋模型)
(3)与采用传统聚类方法中采用距离公式来衡量不同的是,LDA使用一个基于统计模型的方程,而这个统计模型揭示出这些文档都是怎么产生的。
下面的几段文字来源于: http://www.tuicool.com/articles/reaIra6
它基于一个常识性假设:文档集合中的所有文本均共享一定数量的隐含主题。基于该假设,它将整个文档集特征化为隐含主题的集合,而每篇文本被表示为这些隐含主题的特定比例的混合。
LDA的这三位作者在原始论文中给了一个简单的例子。比如给定这几个主题:Arts、Budgets、Children、Education,在这几个主题下,可以构造生成跟主题相关的词语,如下图所示:
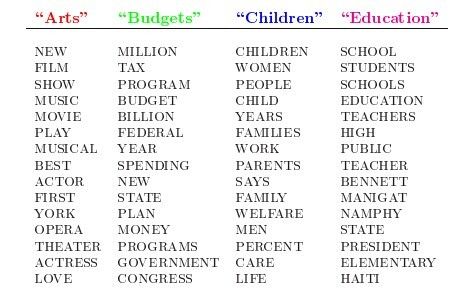
然后可以根据这些词语生成如下图所示的一篇文章(其中不同颜色的词语分别对应上图中不同主题下的词)

表面上理解LDA比较简单,无非就是:当看到一篇文章后,我们往往喜欢推测这篇文章是如何生成的,我们可能会认为某个作者先确定这篇文章的几个主题,然后围绕这几个主题遣词造句,表达成文。
LDA建模算法
至此为之,我们要去考虑,怎么去计算这两个矩阵,怎么去优化的问题了。Spark采用的两种优化算法:
(1)EMLDAOptimizer 通过在likelihood函数上计算最大期望EM,提供较全面的结果。
(2)OnlineLDAOptimizer 通过在小批量数据上迭代采样实现online变分推断,比较节省内存。在线变分预测是一种训练LDA模型的技术,它以小批次增量式地处理数据。由于每次处理一小批数据,我们可以轻易地将其扩展应用到大数据集上。MLlib按照 Hoffman论文里最初提出的算法实现了一种在线变分学习算法。
Spark 代码分析、参数设置及结果评价
SPARK中可选参数
(1)K:主题数量(或者说聚簇中心数量)
(2)optimizer:优化器:优化器用来学习LDA模型,一般是EMLDAOptimizer或OnlineLDAOptimizer
(3)docConcentration(Dirichlet分布的参数α):文档在主题上分布的先验参数(超参数α)。当前必须大于1,值越大,推断出的分布越平滑。默认为-1,自动设置。
(4)topicConcentration(Dirichlet分布的参数β):主题在单词上的先验分布参数。当前必须大于1,值越大,推断出的分布越平滑。默认为-1,自动设置。
(5)maxIterations:EM算法的最大迭代次数,设置足够大的迭代次数非常重要,前期的迭代返回一些无用的(极其相似的)话题,但是继续迭代多次后结果明显改善。我们注意到这对EM算法尤其有效。,至少需要设置20次的迭代,50-100次是更合理的设置,取决于你的数据集。
(6)checkpointInterval:检查点间隔。maxIterations很大的时候,检查点可以帮助减少shuffle文件大小并且可以帮助故障恢复。
SPARK中模型的评估
详细代码注释
[Scala]
纯文本查看
复制代码
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
package
com.blogchong.spark.mllib.base
import
org.apache.log
4
j.{Level, Logger}
import
org.apache.spark.{SparkConf, SparkContext}
import
org.apache.spark.mllib.clustering.{LDA, DistributedLDAModel}
import
org.apache.spark.mllib.linalg.Vectors
/**
* Describe:LDA主题模型基础实例
*/
object
LdaArithmetic {
def
main(args
:
Array[String]) {
// 屏蔽不必要的日志显示在终端上
Logger.getLogger(
"org.apache.spark"
).setLevel(Level.WARN)
Logger.getLogger(
"org.eclipse.jetty.server"
).setLevel(Level.OFF)
// 设置运行环境
val
conf
=
new
SparkConf().setAppName(
"LDA"
).setMaster(
"local"
)
val
sc
=
new
SparkContext(conf)
val
modelPath
=
"file:///export/software/github/spark-2.1.0-bin-hadoop2.6/data/mllib/result/lda/model"
//doc-topic
val
modelPath
2
=
"file:///export/software/github/spark-2.1.0-bin-hadoop2.6/data/mllib/result/lda/model2"
//1 加载数据,返回的数据格式为:documents: RDD[(Long, Vector)]
// 其中:Long为文章ID,Vector为文章分词后的词向量
// 可以读取指定目录下的数据,通过分词以及数据格式的转换,转换成RDD[(Long, Vector)]即可
val
data
=
sc.textFile(
"file:///export/software/github/spark-2.1.0-bin-hadoop2.6/data/mllib/sample_lda_data.txt"
,
1
)
val
parsedData
=
data.map(s
=
> Vectors.dense(s.split(
' '
).map(
_
.toDouble)))
//通过唯一id为文档构建index
val
corpus
=
parsedData.zipWithIndex.map(
_
.swap).cache()
//2 建立模型,设置训练参数,训练模型
/**
* k: 主题数,或者聚类中心数
* DocConcentration:文章分布的超参数(Dirichlet分布的参数),必需>1.0
* TopicConcentration:主题分布的超参数(Dirichlet分布的参数),必需>1.0
* MaxIterations:迭代次数
* setSeed:随机种子
* CheckpointInterval:迭代计算时检查点的间隔
* Optimizer:优化计算方法,目前支持"em", "online"
*/
val
ldaModel
=
new
LDA().
setK(
3
).
setDocConcentration(
5
).
setTopicConcentration(
5
).
setMaxIterations(
20
).
setSeed(
0
L).
setCheckpointInterval(
10
).
setOptimizer(
"em"
).
run(corpus)
//3 模型输出,模型参数输出,结果输出,输出的结果是是针对于每一个分类,对应的特征打分
// Output topics. Each is a distribution over words (matching word count vectors)
println(
"Learned topics (as distributions over vocab of "
+ ldaModel.vocabSize +
" words):"
)
val
topics
=
ldaModel.topicsMatrix
for
(topic <- Range(
0
,
3
)) {
//print(topic + ":")
val
words
=
for
(word <- Range(
0
, ldaModel.vocabSize)) {
" "
+ topics(word, topic); }
topic +
":"
+ words
// println()
}
val
dldaModel
=
ldaModel.asInstanceOf[DistributedLDAModel]
val
tmpLda
=
dldaModel.topTopicsPerDocument(
3
).map {
f
=
>
(f.
_
1
, f.
_
2
zip f.
_
3
)
}.map(f
=
> s
"${f._1} ${f._2.map(k => k._1 + "
:
" + k._2).mkString("
")}"
).repartition(
1
).saveAsTextFile(modelPath
2
)
//保存模型文件
ldaModel.save(sc, modelPath)
//再次使用
//val sameModel = DistributedLDAModel.load(sc, modelPath)
sc.stop()
}
}
|
跑出的结果是:
[Plain Text]
纯文本查看
复制代码
|
01
02
03
04
05
06
07
08
09
10
11
12
|
10 0:0.4314975441651938 1:0.23556758034173494 2:0.3329348754930712
4 0:0.4102948931589844 1:0.24776090803928308 2:0.34194419880173255
11 0:0.2097946758876284 1:0.45373753641180287 2:0.3364677877005687
0 0:0.2979553770395886 1:0.3739169154377782 2:0.3281277075226332
1 0:0.27280146347774675 1:0.3908486412393842 2:0.336349895282869
6 0:0.5316139195059199 1:0.20597059190339642 2:0.2624154885906837
7 0:0.424646102395855 1:0.23807706795712158 2:0.3372768296470235
8 0:0.23953838371693498 1:0.4115439191094815 2:0.3489176971735836
9 0:0.2748266604374283 1:0.41148754032514906 2:0.31368579923742274
3 0:0.5277762550221995 1:0.20882605277709107 2:0.2633976922007094
5 0:0.24464389209216816 1:0.4074778880433907 2:0.34787821986444123
2 0:0.2973287069168621 1:0.3780115877202354 2:0.3246597053629025
|
虽然推断出K个主题,进行聚类是LDA的首要任务,但是从代码第4部分输出的结果(每篇文章的topicDistribution,即每篇文章在主题上的分布)我们还是可以看出,LDA还可以有更多的用途:
- 特征生成:LDA可以生成特征(即topicDistribution向量)供其他机器学习算法使用。如前所述,LDA为每一篇文章推断一个主题分布;K个主题即是K个数值特征。这些特征可以被用在像逻辑回归或者决策树这样的算法中用于预测任务。
- 降维:每篇文章在主题上的分布提供了一个文章的简洁总结。在这个降维了的特征空间中进行文章比较,比在原始的词汇的特征空间中更有意义。所以呢,我们需要记得LDA的多用途,(1)聚类,(2)降维,(3)特征生成,一举多得,典型的多面手。
对参数进行调试
online 方法setMaxIter
[Scala]
纯文本查看
复制代码
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
//对迭代次数进行循环
for
(i<-Array(
5
,
10
,
20
,
40
,
60
,
120
,
200
,
500
)){
val
lda
=
new
LDA()
.setK(
3
)
.setTopicConcentration(
3
)
.setDocConcentration(
3
)
.setOptimizer(
"online"
)
.setCheckpointInterval(
10
)
.setMaxIter(i)
val
model
=
lda.fit(dataset
_
lpa)
val
ll
=
model.logLikelihood(dataset
_
lpa)
val
lp
=
model.logPerplexity(dataset
_
lpa)
println(s
"$i $ll"
)
println(s
"$i $lp"
)
}
|
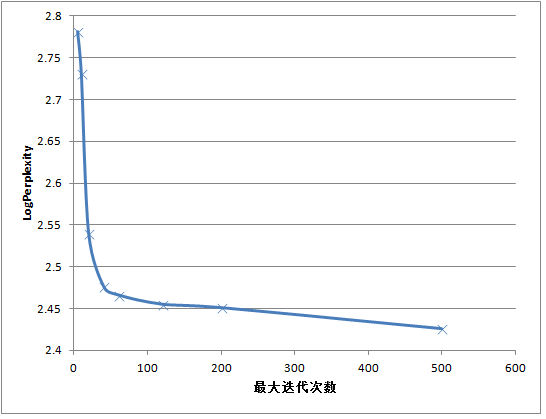
可以得到如下的结果:logPerplexity在减小,LogLikelihood在增加,最大迭代次数需要设置50次以上,才能收敛:

Dirichlet分布的参数α、β
docConcentration(Dirichlet分布的参数α)
topicConcentration(Dirichlet分布的参数β)
首先要强调的是EM和Online两种算法,上述两个参数的设置是完全不同的。
EM方法:
- docConcentration: 只支持对称先验,K维向量的值都相同,必须>1.0。向量-1表示默认,k维向量值为(50/k)+1。
- topicConcentration: 只支持对称先验,值必须>1.0。向量-1表示默认。
由于这些参数都有明确的设置规则,因此也就不存在调优的问题了,计算出一个固定的值就可以了。但是我们还是实验下:
[Scala]
纯文本查看
复制代码
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
//EM 方法,分析setDocConcentration的影响,计算(50/k)+1=50/5+1=11
for
(i<-Array(
1.2
,
3
,
5
,
7
,
9
,
11
,
12
,
13
,
14
,
15
,
16
,
17
,
18
,
19
,
20
)){
val
lda
=
new
LDA()
.setK(
5
)
.setTopicConcentration(
1.1
)
.setDocConcentration(i)
.setOptimizer(
"em"
)
.setMaxIter(
30
)
val
model
=
lda.fit(dataset
_
lpa)
val
lp
=
model.logPerplexity(dataset
_
lpa)
println(s
"$i $lp"
)
}
|
可以看出果然DocConcentration>=11后,logPerplexity就不再下降了。
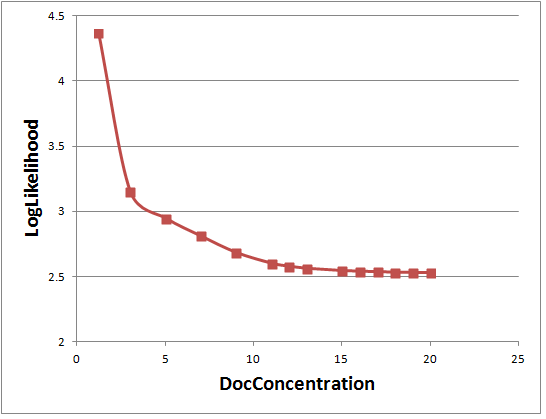
在确定DocConcentration=11后,继续对topicConcentration分析,发现logPerplexity对topicConcentration不敏感。
[Plain Text]
纯文本查看
复制代码
|
1
2
3
4
5
|
1.1 2.602768469
1.2 2.551084142
1.5 2.523405179
2.0 2.524881353
5 2.575868552
|
Online Variational Bayes
(1)docConcentration: 可以通过传递一个k维等价于Dirichlet参数的向量作为非对称先验。值应该>=0。向量-1表示默认,k维向量值取(1.0/k)。
(2)topicConcentration: 只支持对称先验。值必须>=0。-1表示默认,取值为(1.0/k)。
运行LDA的小技巧
(1)确保迭代次数足够多。这个前面已经讲过了。前期的迭代返回一些无用的(极其相似的)话题,但是继续迭代多次后结果明显改善。我们注意到这对EM算法尤其有效。
(2)对于数据中特殊停用词的处理方法,通常的做法是运行一遍LDA,观察各个话题,挑出各个话题中的停用词,把他们滤除,再运行一遍LDA。
(3)确定话题的个数是一门艺术。有些算法可以自动选择话题个数,但是领域知识对得到好的结果至关重要。
(4)特征变换类的Pipeline API对于LDA的文字预处理工作极其有用;重点查看Tokenizer,StopwordsRemover和CountVectorizer接口.
参考:
(1) http://blog.csdn.net/qq_34531825/article/details/52608003