使用Spark MLlib训练和提供自然语言处理模型
Idibon位于旧金山的一家专注于自然语言处理(NLP)的创业公司。从海量非结构化数据中识别关键信息或是定制化实时交互是一些可以说明客户如何利用我们Idibon的技术的例子。Spark ML和MLlib中的机器学习库使得我们可以创建一个自适应的机器智能环境,可以分析任何语言的文本,而且是远超过Twitter每秒产生的单词数量规模的文本量。
我们的团队建立了一个平台,它在分布式环境下训练并提供成千上万个NLP模型。这使得我们可以快速扩展并同时为多个用户提供成千上万个预测每秒。在这篇文章中,我们将会探索我们正在解决的问题的类别、我们遵循的过程、以及我们所使用的技术栈。这应该会对任何想要建立或者改进他们自己的NLP产品线的人有所帮助。
用Spark建立预测模型
我们的客户需要自动将文档分类或者从中抽取信息。这个需求可以是多种形式的,比如社交网络分析、信息分类以及客户通信路由、新闻舆论监控、风险评分以及对低效的数据录入过程进行自动化。所有这些任务有一个共性:建立预测模型,基于从原始文本抽取的特征进行训练。这个创建NLP模型的过程代表了由Spark提供的工具的一个独特且有挑战性的用例。
图一:Idibon提供
建立一个机器学习产品的过程
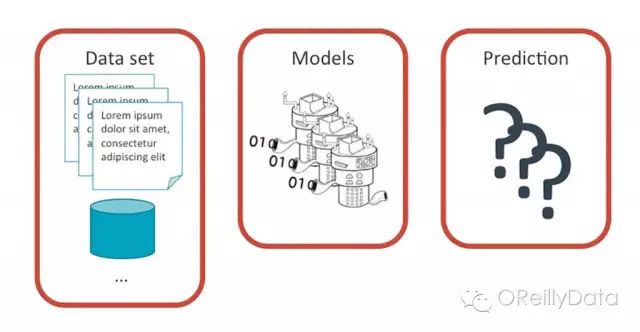
一个机器学习产品可以分为三个概念化部分:预测本身、提供预测的模型、以及用来训练该模型的数据集。
图二:Michelle Casbon提供
预测
在我们的经验中,最好是从商业问题开始并用它们来驱动数据集的选择,而不是用数据集本身驱动项目的目标。如果你的确从一个数据集开始了,那么尽快将数据与核心的商业需求联系起来是十分重要的。有了正确的问题之后,选择有用的分类方法就变得很明确,这也是最终一个预测会提供的。
数据集
一单预测被定义好了,那么哪些数据集是最有用的是显而易见的,验证你可以获得的数据能够支持你试图解决的问题是十分重要的。
模型训练
建立好任务和准备好要使用的数据之后,是时候来考虑模型了。为了生成准确的模型,我们需要训练数据,这经常是人为生成的。这些人可能是公司内部或者咨询公司的专家,或者很多情况下,他们是一组分析师中的一部分。
此外,许多任务可以高效低成本的由像CrowdFlower这样的众包平台来完成。我们喜欢他们的平台,因为它将工作者基于其专长的领域进行分类,这在处理非英语的工作中尤其有用。
所有这些类型的工人为特定部分的数据集提交注解用来生成训练数据。你需要用训练数据来在新的或者余下的数据集上做预测。基于这些预测,你可以决定下一组发送给标注者的数据。这里的重点是通过最少的人工判定来做出最好的模型。你持续在模型训练、评估以及标注中迭代,在每次迭代中获得更高的准确度。我们将这一过程称作自适应学习,这是一种快速且高性价比的产生准确预测的方法。
操作化
为了支持自适应学习过程,我们建立了一个尽可能自动化的平台。在没有人工干预的情况下可以自动扩展的组件是支持动态波动的用户请求API的关键所在。其中我们解决的一些非常困难的扩展性问题包括:
文档存储
每秒提供对数千个独立要求的预测
支持持续训练,无论训练集或者模型参数是否变化都能自动化生成更新模型
通过超参数调优来生成性能最好的模型
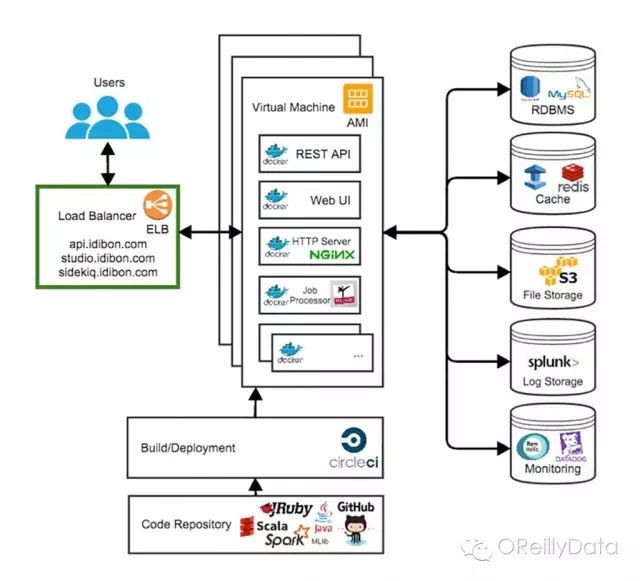
我们通过将AWS栈中的组件整合来解决问题,比如用Elastic负载均衡、自动扩展组、RDS以及Elastic缓存。我们也通过New Relic以及Datadog来监控一系列指标,从而可以在一切变得离谱前警告我们。
下面是我们的基础架构中的主要工具的高层架构解。
图三:由Michelle Casbon提供
Spark的角色
我们的机器学习能力的一个核心的组件是Spark ML和MLlib中的优化功能。在NLP中利用这些会涉及到额外的持久化层,我们称之为idiML。这使得我们可以在单个预测时利用Spark,而不是它最常见的被作为一次性处理大量数据的平台的作用。
我们用Spark做什么?
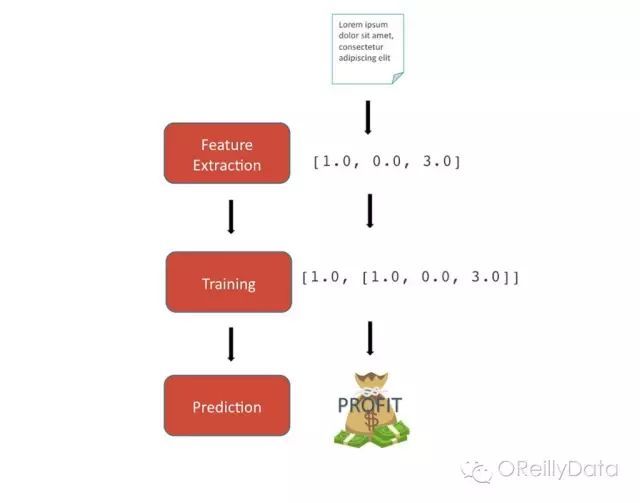
从更细节的层次上讲,一个NLP产品有三个主要组件:
1.特征抽取,文本被转化为一个数值格式用以支持统计模型
2.训练,基于每个特征向量提供的分类生成模型
3.预测,训练模型被用来为新的未预测的文本进行分类
每个组件的简单例子如下所示:
图四:由Michelle Casbon提供
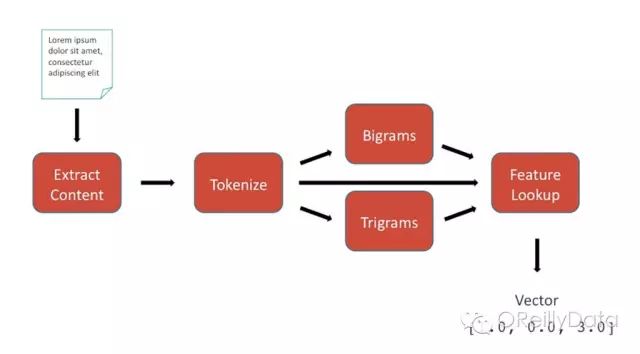
特征抽取
在特征抽取阶段,基于文本的数据被转化为特征向量的形式。这个向量代表了该文本的独特特性且能够通过任意的数学变换的顺序生成。我们的系统被设计为可以很容易地适应于额外的特征类型,例如从深度学习中获取的特征。但是为了简洁,我们这里只考虑基本特征作为例子:
1.输入:一个文档,由内容和可能有的元数据组成
2.内容抽取:将我们感兴趣的输入部分分离出来,通常就是内容本身
3.标记化:文本分隔成单独的单词。在英语中,一个标记基本是一个被空格或标点符号围绕的字符串,但是在其他语言(比如说中文和日语)中,你可能需要定义什么是一个单词。
4.N元组:生成长度为n的单词序列的集合,二元组和三元组是最常见的。
5.特征查找:为每一个独特的特征分配一个专门的数值索引,形成一个整数向量。这一特征索引被存储起来供之后的预测使用。
6.输出:一个Spark MLlib的向量数据类型(org.apache.spark.mllib.linalg.Vector)的数值特征向量
图五:由Michelle Casbon提供
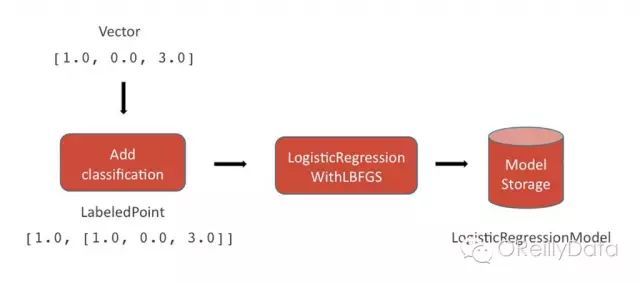
训练
在训练的阶段,一个分类被接在一个特征向量之后。在Spark中,这通过LabeledPoint数据类型来表示。在二元分类器中,这一分类是真或假(1.0或0.0)。
1.输入:数值特征向量
2.一个LabeledPoint被创建出来,由特征向量和其对应的分类组成。这一分类是在之前的项目生命周期中人工生成的。
3.LabeledPoints的集合代表了被输入到MLlib的LogisticRegressionWithLBFGS 方法的训练数据的全集,该方法将基于给定的特征向量和关联的分类找到合适的模型
4.输出:一个逻辑回归模型
图六:由Michelle Casbon提供
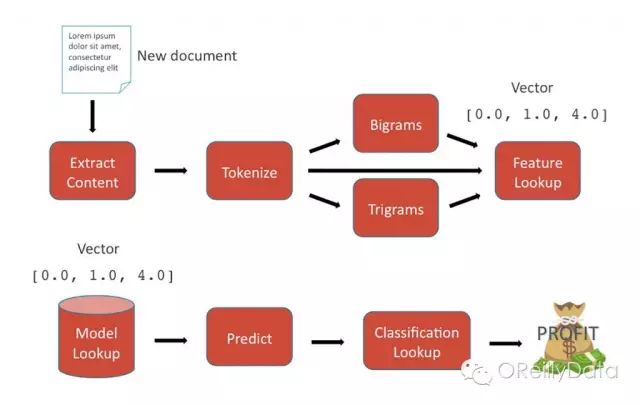
预测
在预测的时候,在训练时生成的模型被用来为新的文本提供分类。一个0-1之间的置信值表示了模型对预测结果的肯定程度。置信度越高,模型越是肯定。下面这些组件完成了整个预测过程:
1.输入:与训练数据同一领域的未预测数据
2.在未预测的文本上应用相同的特征管道。在训练过程中生成的特征索引在这里被用作查找表。这使得一个特征向量和训练数据在同一个特征空间内。
3.获得已训练的模型。
4.特征向量被发送至模型,分类作为预测结果被返回。
5.分类在使用的特定模型的上下文中被解释,然后返回给用户
6.输出:对一个未预测数据的一个预测分类以及对应的置信度
图七:由Michelle Casbon提供
预测数据类型
在传统的Spark ML应用里,预测通常是通过RDD和DataFrames来生成的,应用将文档数据加载到一列中,MLlib将预测的结果放置到另一列中。像所有的Spark应用一样,这些预测任务可以分布到一个集群上来高效地处理拍字节级别的数据量。然而,我们最需要的场景却是与大数据相反的:我们经常需要分析一个单独、短小的文本碎片并且尽快返回结果。理想情况下,最好是在一毫秒之内。
不出所料,DataFrame对这一用例并没有优化,并且我们最初的基于DataFrame的原型缺乏对这个需求的支持。
对我们来说幸运的是,MLlib是通过一个高效的线性代数库来实现的,所有我们计划使用的算法都包括了使用单一向量对象生成预测的无额外开销的内部方法。这些方法看上去对我们的用例来说是完美的,所以我们设计了ldiML来极高效地将单独文档转化为单独向量,哪样的话我们可以使用Spark MLlib内部基于向量的预测方法。
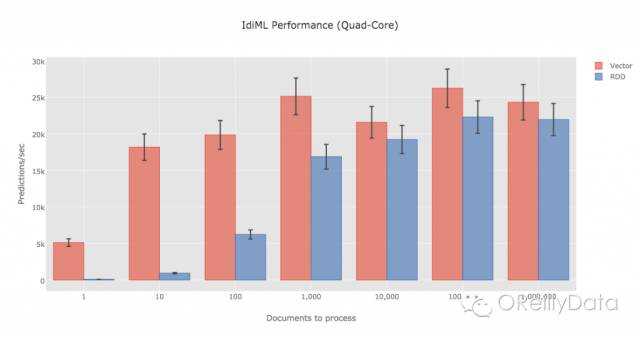
图8:2014在MacBook Pro Retina上进行的性能测试。单一文档性能的较大差距是因为测试中现在没有办法利用多核能力。由Michelle Casbon提供
对于单个预测来说,我们观察到使用Spark MLlib的向量类型比RDD类型在速度的改进最多可以达到两个数量级。两种数据类型的速度差异在较小的批数量下最为明显。考虑到RDD是为处理大量数据而设计的,这种差异就比较合理了。在实时的互联网环境中(比如说我们的场景),小批量目前来看是最为常见的应用场景。由于分布式处理已经构建在我们的服务器和负载均衡上,Spark核心库中的分布式组件对于在小数据环境中的独立预测不是必要的。正如我们在开发ldiML所获得经验,Saprk MLlib对低延迟和实时应用来说是一个相当有用的高性能的机器学习库。在最坏的情况下,ldiML的性能足以在中端笔记本电脑上为每一条Tweet实时做出情感分析。
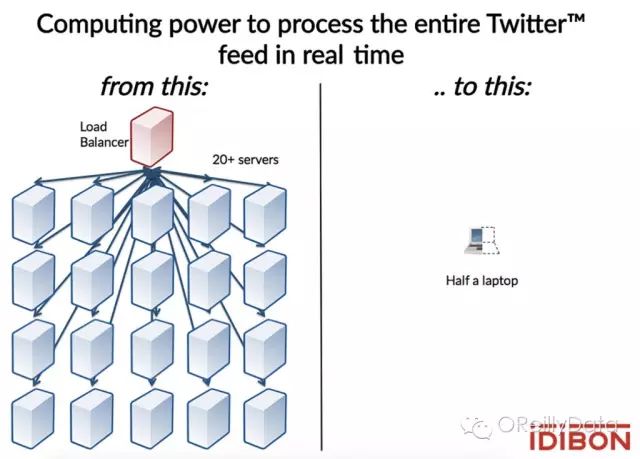
图九:由罗伯·曼罗提供,经允许使用
将其融入到我们含有ldiML的已有平台中
为了提供尽可能准确的模型,我们想要能够支持不同类型的机器学习库。Spark有独特的做法,我们想要让我们的主要代码与特质隔离开。这指的是作为一个持久层(ldiML),可以使得我们将Spark的功能和我们自己写的自然语言处理的代码结合起来。举例来说,在进行超参数调优的时候,我们可以通过将来自我们自己库的和Spark的组件整合起来训练模型。这使得我们可以自动地选择每一个模型上性能最佳的实现,而不是为所有的模型只选一种配置。

图10, 由Michelle Casbon提供
为什么是一个持久层?
使用持久层使得我们可以实施数千个模型的训练和提供服务。这里列出了ldiML给我们所提供的:
一种可以在训练中保存参数的方法。为了返回对应的预测,这是必要的。
对产品中每一部分进行版本控制的能力。这使得我们可以在进行代码更新后支持向后兼容。版本控制也指可以回滚和支持项目周期中之前迭代的模型。
为每个模型自动选择最佳算法的能力。在超参数调优的时候,不同机器学习库的实现被用来组合并评估结果。
通过标准化面向开发人员的组件快速吸收新的NLP特征的能力。这里提供了一个隔离层使得我们的特征工程师和数据科学家不需要学习如何与新的工具进行交互。
在任何环境中部署的能力。我们目前在EC2实例上使用Docker容器,但是我们的架构意味着我们也可以利用例如亚马逊Lambda服务提供的快速实施部署能力。
单独的基于通用InputStreams和OutputStreams的存储和加载框架,将我们从磁盘读写的需求上解放。
一个slf4j形式的日志抽象,避免我们与任何特定框架之间的紧密绑定。
更快、更灵活的高性能系统
NLP与其他形式的机器学习不同,因为它直接操作人类产生的数据。这通常要比机器生成的数据要混乱随意的多,由于语言本身就是模糊的,由此甚至在人类之间都会有不一致的解释性。我们的目标是尽可能自动化NLP产品线,使得资源可以更高效地被利用起来:机器与人互相协作最终更好的帮助人。为了到达这一步并跨越语言的障碍,我们正在用诸如Spark的工具来建立高性能的系统,它们将是前所未有的快和灵活。

Michelle Casbon
Michelle Casbon是ldibon的资深数据科学工程师,她致力于将语言技术带给世界上所有的语言。她具有十多年的开发经验并涉及不同的行业,包括多媒体、投资银行、医疗保健、零售业以及地理信息服务。Michelle在剑桥大学完成了硕士学位,专注于NLP、语音识别、语音合成以及机器翻译。她热爱开源技术,并在Apache Spark项目里做出了可观的贡献。
欢迎关注OReillyData公众号,阅读更多强文。
