字符串与内存函数
文章目录
- 前言
- 字符串长度函数[`strlen`](http://www.cplusplus.com/reference/cstring/strlen/)
-
- 1.`strlen`的使用(接收地址)
- 2.使用`strlen`的小坑
- `strlen`的模拟(计数法 递归 指针相减)
-
- 01 计数法
- 02 递归法
- 03 指针相减法
- 长度不受限制的字符串函数
-
- `strcpy`
-
- 模拟实现`strcpy`
- `strcat`
-
-
- 提醒: 追加原理是首先找到destination的\0,然后在\0上追加source
-
- 提醒:如果自己给自己追加会崩溃.因为\0被覆盖了
- `strcat`的模拟实现
-
- `strcmp`
-
- `strcmp`模拟实现
- 长度受限制的函数
-
- `strncpy`
-
- 模拟实现`strncpy`
- `strncat`
-
- 模拟实现`strncat`
- `strncmp`
-
- `strncmp`的模拟实现
- 字符串的查找
-
- `strstr`功能是查找一个字符串是否是另一个字符串的子串.
-
- 模拟实现`strstr`
- `strtok`
-
- 示例1:
- 巧妙用法示例2:
- 错误信息报告
-
- `strerror`
-
- 示例1:
- 示例2:
- 字符分类函数(需要引入`
前言
C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有字符串类型的,字符串通常放在 常量字符串 中
或者 字符数组 中。 字符串常量 适用于那些对它不做修改的字符串函数.
因此此篇文章便是介绍字符和字符串函数的使用与注意事项.
字符串长度函数strlen
1.strlen的使用(接收地址)
#include 上面的结果是:
7
随机值 (因为
strlen接收首元素地址然后向后查找到\0停止,但是arr2并没有\0结尾,随意是随机值)
2.使用strlen的小坑
下面一段代码,你觉得答案是多少??
#include#include int main() { const char*str1 = "abcdef"; const char*str2 = "bbb"; if(strlen(str2)-strlen(str1)>0) { printf("str2>str1\n"); } else { printf("srt1>str2\n"); } return 0; } 结果是什么呢???
答案是:
str2>str1因为
strlen的返回值是无符号整型,所以无符号减去无符号一定是大于等于0的
strlen的模拟(计数法 递归 指针相减)
01 计数法
size_t my_strlen(char* str)
{
unsigned int count = 0;
while(*str)
{
count++;
str++;
}
return count;
}
02 递归法
size_t my_strlen(char* str)
{
if (*str != 0)
{
return 1 + my_strlen(++str);
}
return 0;
}
03 指针相减法
size_t my_strlen(char* str)
{
char* ret = str;
while(*str) str++;
return str-ret;
}
长度不受限制的字符串函数
strcpy
官方写法
char* strcpy(char* strDestination, const char* strSource);即第一个参数是目的地地址,第二个参数源地址,
例子:
#include#include int main() { char arr1[] = "abcdef"; char arr2[] = "FF"; strcpy(arr1,arr2); printf("%s",arr1); return 0; } 结果:
FF注意点: 这里的复制其实并不是真正的复制,准确的说是覆盖,即把arr2的所有内容(包括
\0)都覆盖到arr1对应位置,也就是说虽然打印出来
arr1是FF,但是实质上arr1等于FF\0def不信看下面的图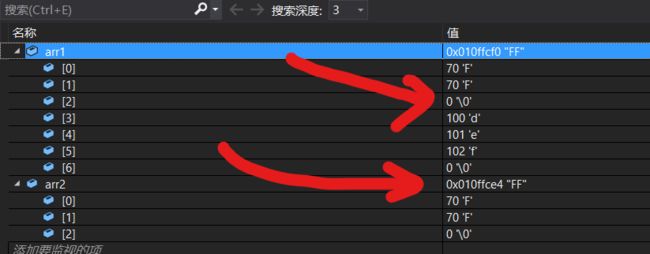
注意事项:
源字符串必须以 ‘\0’ 结束。,如果原字符串没有\0,就会一直拷贝原字符串地址后面的所有内容,直到找到值为0
会将源字符串中的也 ‘\0’ 拷贝到目标空间。
**目标空间必须足够大,以确保能存放源字符串。**如果目标空间不够大,则会导致源字符串拷贝不进去;
目标空间必须可变,即目标空间没有
const修饰
模拟实现strcpy
char* my_strcpy(const char* destination,const char* source)
{
assert(destination && source);
while(*(char*)destination++ = *(char*)source++) ;
return destination;
}
strcat
官方写法
char* strcat( char* strDestination, const char *strSource);即第一个参数是目的空间 第二个参数是源码空间
使用例子:
#include#include int main() { char arr1[10] = "abcd"; char arr3[] = "ABCD"; my_strcpy(arr1, arr3); printf("%s", arr1); return 0; } 答案:
abcdABCD但是如果这样呢
#include#include int main() { char arr1[] = "abcd"; char arr3[] = "ABCD"; my_strcpy(arr1, arr3); printf("%s", arr1); return 0; } 答案:
报错!!! 因为目标空间
arr1大小不够装下再追加,所以我么在使用strcat时候一定要注意目标空间的大小,同时源字符串一定要\0结尾提醒: 追加原理是首先找到destination的\0,然后在\0上追加source
比如下面
#include#include int main() { char arr1[11] = "ab\0dxxxxxx"; char arr3[] = "ABCD"; strcat(arr1,arr3); printf("%s", arr1); return 0; }
我们可以看到
arr1从ab\0dxxxxxx变成了abABCD\0xxx因为他是找到第一个\0,然后在\0上追加.
提醒:如果自己给自己追加会崩溃.因为\0被覆盖了

总结:
-
源字符串必须以 ‘\0’ 结束。
-
目标空间必须有足够的大,能容纳下源字符串的内容。
-
目标空间必须可修改。
strcat的模拟实现
char* ,my_strcat(char* strDestination, const char* strSource)
{
char* ret = strDestination;
/*先找到目标空间的\0*/
while(*strDestination) strDestination++;
/*开始追加*/
while(*strDestination++= *(char*)strSource++);
return ret;
}
strcmp
如果有下面的题:
#include 答案: 0
你会发现,
p1与p2并没有真正的再比较全部字符,而是比较了第一个字符部分.因此我们想要真正的比较字符串就需要一个函数: ----->
strcmp
int strcmp ( const char * str1, const char * str2 );
- 如果第一个字符串大于第二个字符串,则返回大于0数字
- 如果第一个字符串等于第二个字符串,则返回0
- 如果第一个字符串小于第二个字符串,则返回小于0数字
例如:
#includeint main() { char* p1 = "abcdef"; char* p2 = "aqwer"; char* p3 = "aavd"; char* p4 = "abcdef"; printf("%d\n", strcmp(p1, p2)); printf("%d\n", strcmp(p1, p3)); printf("%d\n", strcmp(p1, p4)); return 0; }

strcmp模拟实现
int my_strcmp(const char* arr1, const char* arr2)
{
while (*(char*)arr1 && (*(char*)arr1 == *(char*)arr2))
{
(char*)arr1++;
(char*)arr2++;
}
if (!*(char*)arr1) return 0;
/*当跳出循环就表示碰到不一样的了,所以返回差值*/
return *(char*)arr1 - *(char*)arr2;
}
长度受限制的函数
前面的三个不受长度限制的函数有局限性:
比如strcpy:------->源字符串需要末尾有\0,且必须拷贝到\0结束,不关心是否目的地装得下源字符串,撑爆就报错
strcat:------->源字符串需要末尾有\0,且必须追加到\0结束,不关心是否目的地装得下源字符串,撑爆就报错
strcmp:------->源字符串需要末尾有\0,且必须比较到\0结束,不关心是否目的地装得下源字符串,撑爆就报错
因此,变有了下面的与前三者功能相似,但是可以控制数量的长度受限函数
strncpy
用法与strcpy一样,但是多了个参数 size_t count,即需要拷贝的字符数量
char * strncpy ( char * destination, const char * source, size_t count );
用法:
#include 答案:
XXXdefg你会看到,并没有再把
arr2的\0给放进arr1
**注意点:**当count的数量大于arr2的长度时候,会自动用\0补数,比如:
#include 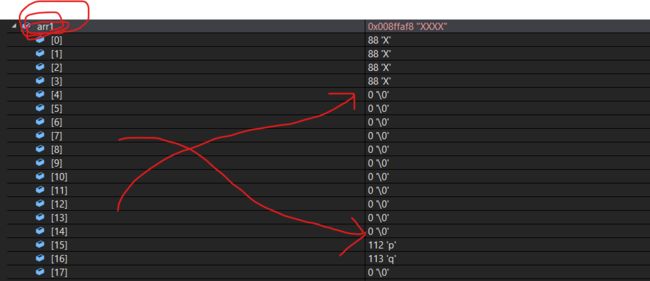
可以清楚的看到arr1里面的内容:自动补充了很多\0
模拟实现strncpy
char* my_strncpy(char* str1, const char* str2, size_t count)
{
char* ret = str1;
while (count&& (*str1++ = *(char*)str2++)) count--;
if (count)
/*--count 是因为str1已经为\0,不再需要继续赋值\0,所以先减一下*/
while (--count) *str1++ = '\0';
return ret;
}
strncat
用法与
strcat一样,但是多了个参数size_t count,即需要追加的字符数量
char * strncat ( char * destination, const char * source, size_t count );
用法示例:
#include 答案:
abcdefXXXX而当
count>arr2时,就不再管
模拟实现strncat
char* my_strncat(char* str1, const char* str2, size_t count)
{
char* ret = str1;
while (*str1) str1++;
while (count-- && (*str1++ = *(char*)str2++));
return ret;
}
strncmp
int strncmp ( const char * str1, const char * str2, size_t num );用法与前面一样,我就不再赘述怎么用,直接开始模拟
strncmp的模拟实现
int my_strncmp(const char* str1, const char* str2, size_t num)
{
while (num-- && *str1 && (*str1 == *str2))
{
str1++;
str2++;
}
return *(char*)str1 - *(char*)str2;
}
字符串的查找
strstr功能是查找一个字符串是否是另一个字符串的子串.
- 并且如果找到就返回在目的地中源字符串的第一个地址,找不到就返回空指针(NULL)
例如 :
#include#include int main () { char str[] ="This is a simple string"; char * pch; pch = strstr (str,"simple"); if (pch != NULL) strncpy (pch,"sample",6); puts (str); return 0; } 结果:
This is a simple string,可以看见,虽然前面调用了strncpy但是对str好像并没有影响,因为pch是将接收的是str中的simple的首地址.即S
模拟实现strstr
char* my_strstr(const char* dest,const char* src)
{
/*第一步,一一比较.当src都比较完了(*src等于\0),则说明是子串*/
while(*dest) //确保dest每个字符后面的字符串与src匹配
{
char* ret = dest;
//一一比对,当src等于\0,说明全部比对完成.
while((*ret == *src) && (*src!='\0'))
{
ret++;
src++;
}
if(!*src) return dest;
(char*)dest++;
}
return NULL;
}
像上面这样真的完毕了吗??? 我们似乎只处理了 像下面一样的例子:
目标:
"abcdefg"源串:
"cdef"
那么,还有什么不一样的例子我们没有考虑到呢???哦??好像是这个
目标:
"abcdefg"源串:
"defghi"
而且好像还有这个
目标:
"ABCDDDEFGH"源串:
"DDEFG"这种情况如果只用最开始模拟的情况,则会返回空指针.
所以针对第二种与第三种情况,内层循环还应该有另外一个条件,即*dest ! = '\0' .
并且,每个字符后面的字符串比较完毕,指针又返回到所比较字符串开头.因此,添加以下代码
char* my_strstr(const char* dest, const char* src)
{
char* s1;
char* s2;
char* cur = (char*)dest;
/*第一步,一一比较.当src都比较完了(*src等于\0),则说明是子串*/
while (*cur) //确保dest每个字符后面的字符串与src匹配
{
s1 = (char*)cur;
s2 = (char*)src;
//一一比对,当src等于\0,说明全部比对完成
while ((*s1 != '\0') && (*s2 != '\0')&&(*s1 == *s2))
{
s1++;
s2++;
}
if (!*s2) return cur;
cur++;
}
return NULL;
}
另外,对于求子字符串的算法还有KMP,可以参考一位大佬的文章KMP
strtok
字符串分割函数,即目标字符串通过设置的分割符进行分割出来
官方写法:
char * strtok ( char * str, const char * delimiters );第一个参数是目标**
被分割字符串,第二个参数是分隔符集合**用法:
- 传入一份临时拷贝的字符串给
str,因为不想要源字符串被真正的分割.- 对于同一个字符串,第一次调用,必须传入地址,第二次以及多次传入
NULL- 对于
strtok的妙用一般是使用for循环.- 未分割完时,返回值是被分割的小段字符串的首地址,分割完时,返回NULL
示例1:
#include 结果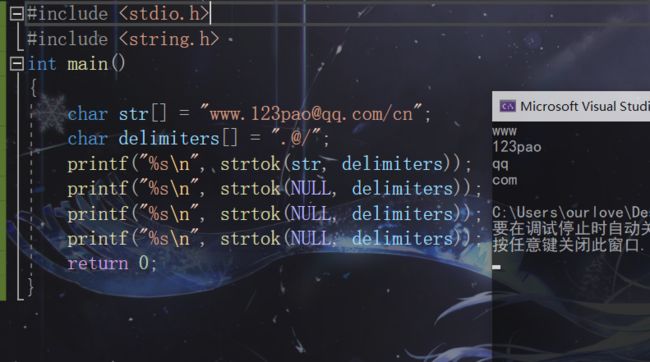
巧妙用法示例2:
#include 结果:
错误信息报告
strerror
官方写法: char * strerror ( int errnum ) 即输入一个代表错误码的整数,然后会返回错误信息
示例1:
#include 结果: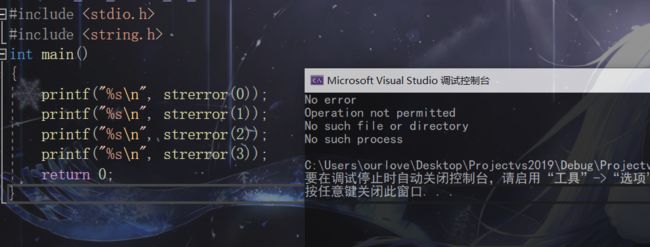
但是这个函数我们经常用在哪里呢???,答案是配合errno使用
errno是一个全局的错误码变量- 当C语言库函数在执行过程中,发生错误,就会把对应错误码,赋值到
errno中.
示例2:
#include 结果:
字符分类函数(需要引入
iscntrl 任何可控字符
isspace 空白字符:空格, \f(换页), \n(换行),\t(水平制表符),\r(回车),\v(锤子制表符)
isdigit 检验十进制数字 0 ~ 9
isxdigit 检验16进制数字 0 ~ F
islower 检验是否是小写字母 a ~ z
isupper 检验是否是大写字母 A ~ Z
isalpha 检验是都是字母 a ~ z 和 A ~ Z
isalnum 检验是否是数字和字符 0~9 a~z A~Z
验证:随机用几个函数示范
#include 结果:
2 1 4
但是不同电脑可能不同结果.因为只要符合就返回的是 非零数
字符转换函数(tolower和toupper)
#include 
内存函数
上面我已经叙述了很多的关于字符串的处理函数
包括以下:
strlenstrcpystrcatstrcmpstrncpystrncatstrncmpstrstrstrtok字符分类函数 字符转换 函数
但是我们能够明显的发现,我们都是局限在处理 字符串 上面,并不能处理其他的类型.
比如我需要复制一份数组,如果我们用strcpy试试.
#include 结果:
1
0
0
0
0
原因: strcpy 是一个字节一个字节进行复制的,而我们的计算机大部分都是小端存储.
即数组num1的存放结构如图;

所以当strcpy复制了01 之后,后面就是0,便停止了复制.而目的数组num2本就是全部为0,所以当第一个字节被复制一份01以后,num2[0]的值就是1,而后面都没有复制,所以全是0
因此,我们引入了内存处理函数,主要是下面几个 :
memcpymemmovememcmpmemset
memcpy的使用与模拟
官方文档:
void * memcpy ( void * destination, const void * source, size_t num );第一个参数: 目的地地址
第二个参数: 源字符串地址
第三个参数: 字节数量
memcpy使用例子;
#include 结果: ****
****
成功复制!!!
memcpy的模拟实现
其实这个模拟还是比较简单的(相比于
qsort的模拟),因为都用到了 万能指针void*,接收一切
在我么实现这个函数之前,我们需要首先确定他是怎么复制的…前面已经说过,是一个字节一个字节复制的.那么我们肯定需要一个循环,且循环20次,但是接收的参数都是指针,而且 目的地还是 void*指针,那么怎么连接上 第三个参数与 第一个参数呢?,答案是 字符指针
因为一个字符指针的跳跃性就是 一个字节,刚好符合 size_t num
void* my_memcpy(void* dest, const void* src, size_t num)
{
char* ret = dest;
while (num--)
{
*(char*)dest = *(char*)src;
++(char*)dest;
//之所以前置++,是因为结合性++高于(类型转化),而dest与src都是void*
//不能加减,所以就会报错,所以变成前置++
++(char*)src;
}
return ret;
}
memmove的使用与模拟
官方文档:
void * memcpy ( void * destination, const void * source, size_t num );用法与
memcpy一模一样.这里就不再赘述.那么他的功能是什么呢?? 他的功能也与
memcpy一模一样,那我们还学习什么呢??那么,如果我们用自己写的函数
my_memcpy实现把自己的一部分复制到另一部分去呢???比如下面例子:
int arr[] = { 1,2,3,4,5,6,7,8,9,10};如果我想把 1 2 3 4 5 放到 4 5 6 7 8的位置呢??如果使用自己实现的
my_memcpy答案是这样的1 2 3 1 2 3 1 2 9 10
为什么呢??因为当空间重叠时候,自己去复制自己时候,有一部分就会被覆盖,如图

而memmove的作用就是来实现重叠空间的复制
算法描述:
那么重叠空间我们怎么来实现进行复制呢???
很简单,我们倒着来放.比如刚才的1 2 3 4 5 放到 4 5 6 7 8,
我们从后开始,先把5 放到 8位置-------> 4放到 7位置----->3放到6位置------>2放到5位置------->1放到4位置
问题1 :
所有的都可以这样吗?? 那我如果想要把4 5 6 7 8 放到1 2 3 4 5位置呢???如果倒着放,就会又混乱.因此我们是需要分情况进行设计的.
情况1:
目的位置在源位置之后,比如1 2 3 4 5是源位置,1就是源首地址. 而4 5 6 7 8是目的地址,而4就是目的首地址.这符合目的位置在原位置之后,就采用 从后向前复制
而这种情况的难点就是怎么找最后一个元素的最后一个字节位置
答案是
dest+num-1和src + num -1,为何??见图:
情况2:
除去
情况1的情况,就都采用 挨着顺序复制
模拟:
void* my_memmove(void* dest,const void* src,size_t num)
{
char* ret = dest;
if(dest > src)
{
while(num--)
{
//因为这里已经减了一次,所以不再需要num-1;
*((char*)dest + num) = *((char*)src + num);
}
}
else
{
while(num--)
{
*(char*)dest = *(char*)src;
++(char*)dest;
++(char*)src;
}
}
return ret;
}
有人会问:那么我偏要用memcpy进行重叠空间试试,行嘛??行!!!
在最底层,
memcpy实际上是与memmove一模一样的.都可以复制 重叠行与非重叠性的空间,但是为什么我们要弄两个呢>解释:
在c语言标准里面:
memcpy只需要实现不重叠空间复制
memmove只需要实现重叠空间复制懂了吗???也就是说,他们都是超额完成了自己任务,我们去模拟,只是为了掌握算法与思想
所以才分开了memcpy与memmove进行模拟
memcmp`的使用与模拟
官方文档:
int memcmp ( const void * ptr1, const void * ptr2, size_t num );第一个参数: 目的地地址
第二个参数: 源目标地址
第三个参数: 直接数量
使用: 与前面所讲的大致一样.不再一 一赘述,此处只讲模拟.在模拟之前建议再看看此文上面的
strcmp,有异曲同工之妙
memcmp模拟
int my_memcmp(const void * ptr1, const void * ptr2, size_t num)
{
while(num-- && (*(char*)ptr1 == *(char*)ptr2))
{
++(char*)ptr1;
++(char*)ptr2; //为什么前置++,之前strcmp讲解过
}
return *(char*)ptr1 - *(char*)ptr2;
}
memset的使用及注意事项
官方文档:
void * memset ( void * ptr, int value, size_t num );第一个参数: 目标地址
第二个参数: 某个确定的字符
第三个参数: 字节数量.
使用:
#include 结果: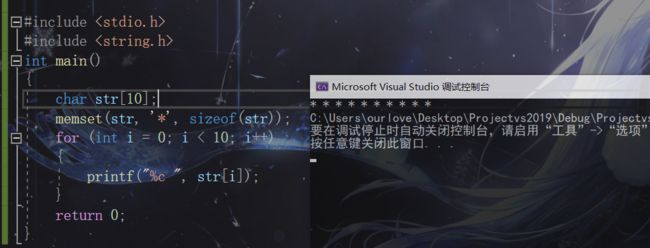
错误使用注意事项:
#include 结果:
会发现整型数组与我们想象的不一样,因为一个整型数组是4个字节.
而memset是针对字节操作的.所以注意,一般我们只是用于整型数组初始化为0,或者-1,这才是准确的