Kafka的灵魂伴侣Logi-KafkaManger(4)之运维管控–集群运维(数据迁移和集群在线升级)
文章目录
- 运维管控
-
- 集群列表
- 集群运维
-
- 迁移任务
-
- 手动迁移过程实现
- 数据迁移的几个注意点
- KM实现数据迁移
- 集群任务
- 版本管理
- 平台管理
-
- 应用管理
-
- 应用申请
-
- 应用详情
- 申请下线
- 用户管理
-
- 用户角色
- 平台配置
- 网关配置
- 专栏文章列表
项目地址: didi/Logi-KafkaManager: 一站式Apache Kafka集群指标监控与运维管控平台
运维管控
运维管控这个菜单栏目下面主要是供
运维人员来管理所有集群的;
集群列表
Kafka的灵魂伴侣Logi-KafkaManger三之运维管控–集群列表
集群运维
迁移任务
kafka的迁移场景, 一般有同集群数据迁移、跨集群数据迁移; 我们这里主要讲 同集群数据迁移;
同集群之间数据迁移,比如在已有的集群中新增了一个Broker节点,此时需要将原来集群中已有的Topic的数据迁移部分到新的集群中,缓解集群压力。
在了解KM的迁移功能之前,我们先了解一下正常情况下是怎么做迁移的;
手动迁移过程实现
分区重新分配工具可用于将一些Topic从当前的Broker节点中迁移到新添加的Broker中。这在扩展现有集群时通常很有用,因为将整个Topic移动到新的Broker变得更容易,而不是一次移动一个分区。当执行此操作时,用户需要提供已有的Broker节点的Topic列表,以及到新节点的Broker列表(源Broker到新Broker的映射关系)。然后,该工具在新的Broker中均匀分配给指定Topic列表的所有分区。在迁移过程中,Topic的复制因子保持不变。
现有如下实例,将Topic为ke01,ke02的所有分区从Broker1中移动到新增的Broker2和Broker3中。由于该工具接受Topic的输入列表作为JSON文件,因此需要明确迁移的Topic并创建json文件,如下所示:
> cat topic-to-move.json
{
"topics": [{
"topic": "ke01"},
{
"topic": "ke02"}],
"version":1
}
1 . 准备好JSON文件,然后使用分区重新分配工具生成候选分配,命令如下:
> bin/kafka-reassign-partitions.sh --zookeeper dn1:2181 --topics-to-move-json-file topics-to-move.json --broker-list "1,2" --generate
执行完成命令之后,控制台出现如下信息:

该工具生成一个候选分配,将所有分区从Topic ke01,ke02移动到Broker1和Broker2。需求注意的是,此时分区移动尚未开始,它只是告诉你当前的分配和建议。保存当前分配,以防你想要回滚它。新的赋值应保存在JSON文件(例如expand-cluster-reassignment.json)中,以使用–execute选项执行。JSON文件如下:
{"version":1,"partitions":[{"topic":"ke02","partition":0,"replicas":[2]},{"topic":"ke02","partition":1,"replicas":[1]},{"topic":"ke02","partition":2,"replicas":[2]},{"topic":"ke01","partition":0,"replicas":[2]},{"topic":"ke01","partition":1,"replicas":[1]},{"topic":"ke01","partition":2,"replicas":[2]}]}
2. 执行命令如下所示:
> ./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
3. 最后,–verify选项可与该工具一起使用,以检查分区重新分配的状态。需要注意的是,相同的expand-cluster-reassignment.json(与–execute选项一起使用)应与–verify选项一起使用,执行命令如下:
> ./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
执行结果如下图所示:

Kafka数据迁移 - 哥不是小萝莉
数据迁移的几个注意点
减少迁移的数据量: 如果要迁移的Topic 有大量数据(Topic 默认保留7天的数据),可以在迁移之前临时动态地调整retention.ms 来减少数据量,比如下面命令改成1小时; Kafka 会主动purge 掉1小时之前的数据;
> bin/kafka-topics --zookeeper localhost:2181 --alter --topic sdk_counters --config retention.ms=3600000
不要要注意迁移完成后,恢复原先的设置
迁移过程注意流量陡增对集群的影响
Kafka提供一个broker之间复制传输的流量限制,限制了副本从机器到另一台机器的带宽上限,当重新平衡集群,引导新broker,添加或移除broker时候,这是很有用的。因为它限制了这些密集型的数据操作从而保障了对用户的影响、
例如我们上面的迁移操作
> ./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
在后面加上一个—throttle 50000000 参数, 那么执行移动分区的时候,会被限制流量在50000000 B/s
加上参数后你可以看到
The throttle limit was set to 50000000 B/s
Successfully started reassignment of partitions.
迁移过程限流不能过小,导致迁移失败
-throttle 是broker之间复制传输的流量限制,限制了副本从机器到另一台机器的带宽上限; 但是你应该了解到正常情况下,副本直接也是有副本同步的流量的; 如果限制的低于正常副本同步的流量值,那么会导致副本同步异常,跟不上Leader的速率很快就被踢出ISR了;
迁移完成,注意要移除流量的限制:
如果我们加上了迁移这个操作, 需要使用参数--verify 来验证执行状态,同时流量限制也会被移除掉; 否则可能会导致定期复制操作的流量也受到限制。
> ./kafka-reassign-partitions.sh --zookeeper dn1:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
详情请参考
kafka在数据迁移期间限制带宽的使用 - OrcHome
KM实现数据迁移
了解完了手动迁移的流程后,那我们再来了解一下KM的迁移动作,那么你会爱上这个操作;因为极大的简化了迁移操作;
上图中是创建一个 迁移任务的操作; 解释一下里面的几个参数;
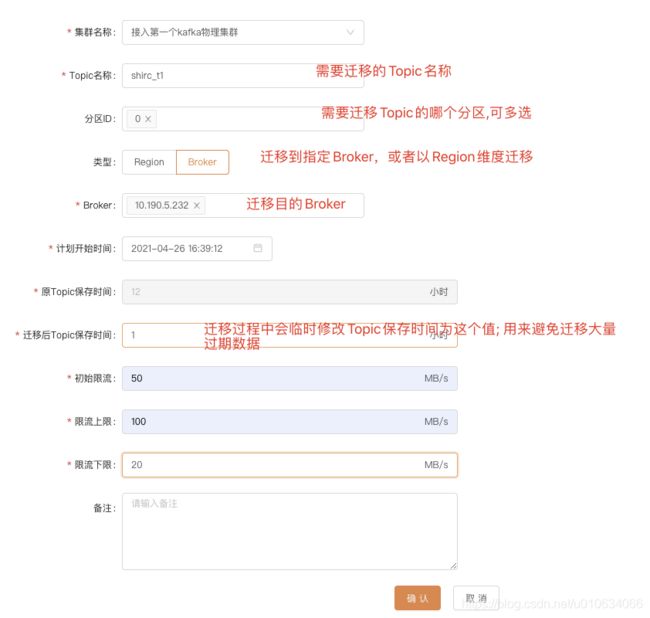
上面我主要讲解几个参数
迁移后Topic的保存时间:
我们上面讲解迁移注意事项的时候有讲解到,需要 减少迁移的数据量 ; 假如你默认保存了7天的数据量, 那么这个迁移的数据量可能非常的大,并且很多都是已经消费过得过期数据; 所以我们需要在先把这么多过期数据给清理掉之后再开始迁移; 这个参数填的就是保存最近多久的数据;删掉过期的数据; 并且迁移结束之后会把时间改回成原来的时间;
初始限流:
限流上线:
限流下线:
可能你看到这几个参数会很奇怪, 限流不就是一个确定的值么,填一个限流值就行了,搞这么多是要干啥;
其实是 KM想做成的是动态调整限流, 根据不同时间和集群状态去动态调整, 比如空闲时候我最大可以允许你流量达到100M/s(限流上线); 但是如果你在迁移的时候可能压力比较大,我不想让你一开始就用这个100M/s限流; 迁移开始时候使用初始限流,但是限流不能过小,因为要考虑正常情况下副本同步时候的流量,所以有了限流下线 ;
然后KM每隔一段时间(1分钟)就会去检查迁移状态,然后动态调整限流值;
当然,现在KM中其实用的还是初始限流这个值来作为限流; 并没有动态的来调整流速; 这个是将来需要改造的点;
创建完迁移任务之后,KM定时器检测到达到开始时间之后,就会开始正式迁移;
执行的过程跟我们上面讲到的迁移流程一样,只是程序自动帮我们去实现了;
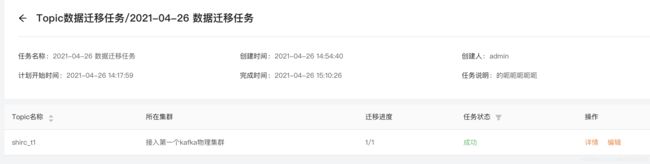
如果数据量大,迁移任务建议放在空闲时间段
集群任务
这个模块是用于自动化kafka集群升级用的,但是需要配合夜莺系统来使用(主要是在KM上将升级包发送到服务器上);
这个功能对应大集群来说非常好用,自动在线升级; 不需要手动去操作;
简单看一下使用图


如何对接夜莺系统, 等我有空再补充 对接夜莺系统,TODO
版本管理
创建集群任务的时候, 需要上传 kafka升级包,和配置文件集

平台管理
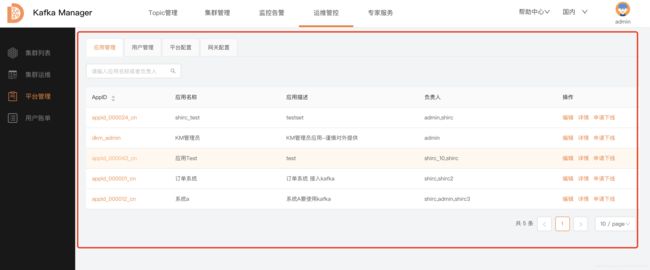
应用管理
管理 所有使用Kafka的应用, Topic的创建需要管理到对应的系统(哪个系统); 这里展示的是所有的应用;如果想看自己负责的应用;查看路径是 Topic管理 -> 应用管理
应用申请
具有应用申请权限的用户可以申请新的应用 ; 然后由运维人员审批;
申请的地方在 Topic管理 -> 应用管理 -> 应用申请
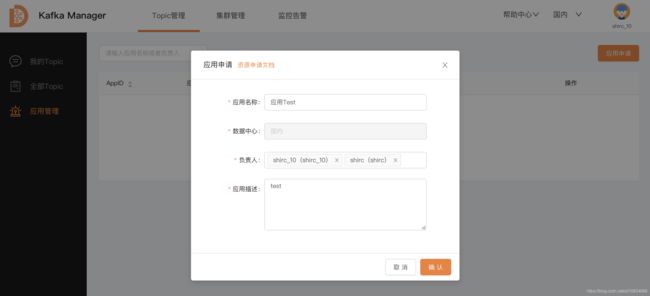
应用负责人至少是两个

应用详情
展示一些应用基本信息, 其中AppId和 密钥 在Topic鉴权的时候会使用到;
运维人员和应用责任人可以编辑信息,比如可以添加新的责任人;
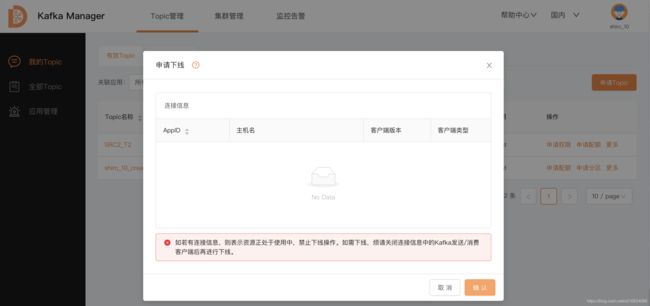
申请下线
如果应用已经废弃不使用了,可以申请下线; 除了在这里
运维管理人员可以申请下线;应用负责人可以在 Topic管理->应用管理 那里申请下线;

这里的展示的 连接信息 是需要配置滴滴的kafka-gateway组件才会展示的; 否则是拿不到相应的信息的; kafka-gateway并未开源,如果需要请联系官方;
连接信息展示Demo TODO…
在申请应用下线之前, 需要先确认该应用下面创建的所有topic都下线,否则运维人员下线的时候会提示:先下线topic,才能下线应用~
还需要注意就是如果申请了其他topic的使用权限,需要先取消权限

应用负责人需要申请Topic下线地方在 Topic管理->我的Topic->更多->申请下线
注意只有 你是应用负责人才能申请下线; 如果只是有部分使用权限是不能申请下线的;
同样的,这里的展示的 连接信息 是需要配置滴滴的kafka-gateway组件才会展示的; 否则是拿不到相应的信息的; kafka-gateway并未开源,如果需要请联系官方;
用户管理
运维人员 管理用户

用户角色
KafkaManager的用户角色分了3种:
运维人员: 拥有平台所有权限
研发人员: 除了专家服务等权限,其他都有
普通用户: 普通开发者, 只有Topic管理,集群管理,监控告警等等权限
其实这里的角色权限取名理解起来比较费解,一开始我也以为研发人员就是我们所理解的普通开发者;
但是实际上
普通用户: 这个角色才是我们写代码使用kafak的开发者; 只需要关心自己的Topic模块就行;
研发人员: 包含普通用户的权限,但是它又具备运维管控的权限,使用场景就是 可能该角色是一个小组的TeamLeader;或者技术专家,他在普通用户的基础上需要去了解一下整个物理集群的监控状态,和找一些问题;
KM的用户角色和权限这一块还比较粗糙,跟社区反馈过,社区回应的是 将来会大改这一块,做一套统一的权限资源管理;
平台配置
一些系统的内部配置
配置键: ADMIN_ORDER_HANDLER_CONFIG 指定账户拥有审批权限
配置值Demo: [ "shirc_10", "shirc1" ]
描述: 很多审批需要运维人员进行审批; 如果运维人员太忙,不想花费时间在审批上,则可以指定部分账户拥有 审批权限; 代替审批; 这时候运维人员就没有权限审批了,审批按钮被隐藏了

申请人通过详情这里可以看到哪些人可以审批; 就可以找到对应的人帮忙审批一下了;
配置键: REGION_CAPACITY_CONFIG 设置集群Broker的默认最大支持流量
具体详情: 在 Kafka的灵魂伴侣Logi-KafkaManger三之运维管控–集群列表 有详细描述
系统每隔2分钟就去尝试将未落盘(比如刚接入KM,已经存在的Topic都未落盘)的Topic刷新到DB中; 当前前提是配置打开了 task.op.sync-topic-enabled: true
但是默认情况下,topic这个时候虽然刷到DB中了,但是属于无主Topic.没有绑定到对应的应用中
如果你想在刷到DB中的时候让它默认就绑定到某个默认的应用上就可以用到下面的配置了;
SYNC_TOPIC_2_DB_CONFIG_KEY 定期将未落盘的Topic刷新到DB中的时候,是否绑定到具体的应用和权限;
[ { "clusterId": 4, "defaultAppId": "dkm_admin", "addAuthority": true }, { "clusterId": 5, "defaultAppId": "dkm_admin", "addAuthority": true } ]
clusterId: 物理集群id
defaultAppId:默认绑定到的应用id
addAuthority: 是否同时增加应用对该topic的读写权限;

使用场景: 感觉没啥大用,就算这个时候没有绑定到应用上,后面我们还是可以针对Topic一个个去绑定对应的应用的;
其他一些不是很重要的配置就不列举了,有兴趣可以直接看源码
网关配置
配合 滴滴的
kafka-gateway组件使用的; 开源版本不需要关注
网关配置详细TODO
专栏文章列表
Kafka的灵魂伴侣Logi-KafkaManger一之集群的接入及相关概念讲解
Kafka的灵魂伴侣Logi-KafkaManger二之kafka针对Topic粒度的配额管理(限流)
Kafka的灵魂伴侣Logi-KafkaManger三之运维管控–集群列表
如果文章对你有帮助的话, 麻烦给博主一键三连呀, 原创不易 你的支持是我输出的动力 ✌