- 使用top1000来取title
(0) 得到query_title对应表
create table if not exists graph_embedding.hs_heter_graph_embedding_out_nearest_neighbor_007(
node_id bigint,
emb string
) LIFECYCLE 14;
hs_heter_graph_embedding_out_nearest_neighbor_007
PAI -name am_vsearch_nearest_neighbor_014 -project algo_market
-Dcluster="{"worker":{"count":1,"gpu":100}}"
-Ddim=100
-Did_col="node_id"
-Dvector_col="emb"
-Dinput_slice=1
-Dtopk=1000
-Dnprob=1024
-Dmetric="l2"
-Dinput="odps://graph_embedding/tables/hs_heter_graph_embedding_video_recall_"
-Dquery="odps://graph_embedding/tables/hs_heter_graph_embedding_ave_info_"
-Doutputs="odps://graph_embedding/tables/hs_heter_graph_embedding_out_nearest_neighbor_007"
-DenableDynamicCluster=true -DmaxTrainingTimeInHour=60;
1000 result : hs_heter_graph_embedding_out_nearest_neighbor_007
(1) 分割result
create table hs_tmp_10 as select bi_udf:bi_split_value(node_id, emb, " ") as (query_id, title_id) from hs_heter_graph_embedding_out_nearest_neighbor_007;
create table hs_tmp_11 as select graph_embedding:hs_split(query_id, title_id, ":") as (query_id, title_id, score) from hs_tmp_10;
加title:
create table hs_tmp_12 as
select a.query_id, a.title_id, b.title, a.score from
(select * from hs_tmp_11)a join
(select title, id from hs_jingyan_query_related_video_pool_2_3)b
on a.title_id == b.id;
(2) 除去叶子类目中找不到的结果,顺便加上叶子类目信息
create table hs_tmp_13 as
select int(a.query_id - 1) as index, a.title_id, a.title, b.item_id, a.score, b.cate_id, b.cate_name from
(select * from hs_tmp_12 where title in (select title from hs_leaf_class_for_title_2))a join (select * from hs_leaf_class_for_title_2)b on a.title == b.title;
(3)过滤
pai -name pytorch -project algo_public_dev -Dpython=3.6 -Dscript="file:///apsarapangu/disk1/hengsong.lhs/origin_deep_cluster_odps_5.tar.gz" -DentryFile="test_query_with_title.py" -Dtables="odps://graph_embedding/tables/hs_tmp_13,odps://graph_embedding/tables/hs_leaf_class_for_query_0" -Doutputs="odps://graph_embedding/tables/hs_tmp_14" -Dbucket="oss://bucket-automl/" -Darn="acs:ram::1293303983251548:role/graph2018" -Dhost="cn-hangzhou.oss-internal.aliyun-inc.com" -DuserDefinedParameters="" -DworkerCount=1;
(4)得到title对应信息
| index | origin_query | query | video_id | title | item_id | score | cate_id | cate_name | url |
create table hs_tmp_15 as
select distinct * from
(select coalesce(get_json_object(body, '.entities.k1.item_id/l')) as item_id_a, title, id as video_id, coalesce(CONCAT('http://cloud.video.taobao.com', get_json_object(body, '.entities.k3.play_url/s')))as url from hs_jingyan_query_related_video_pool_2_3)a join (select * from hs_tmp_14)b on a.item_id_a == b.item_id;
create table hs_tmp_17 as select int(index + 1) as index, title_id, title, item_id, score, cate_id, cate_name from hs_tmp_13;
create table hs_tmp_16 as
select distinct c.index, c.query, d.title_id as video_id, d.title, d.item_id, d.score, d.cate_id, d.cate_name from (select * from (select * from hs_tmp_14)a join (select * from hs_jingyan_query_related_top_query_3)b on a.index== b.id) c join (select * from hs_tmp_17)d on c.index == d.index;
create table hs_result_title_query_1w_top1000_only1page_filtered as
select distinct a.*, b.url from
(select * from hs_tmp_16)a join (select * from hs_tmp_15)b on a.item_id == b.item_id where b.url is not NULL;
(5)更正video_id
create table hs_result_title_query_1w_top1000_only1page_filtered_1 as
select distinct b.index, b.query, a.video_id, b.title, b.item_id, b.score, b.cate_id, b.cate_name, b.url from
(select id, coalesce(get_json_object(body, '.entities.k2.video_id/l')) as video_id from hs_jingyan_query_related_video_pool_2_3)a join (select * from hs_result_title_query_1w_top1000_only1page_filtered)b on a.id == b.video_id;
- docker使用
docker(建议大家在开发机上使用docker)
docker基础镜像:reg.docker.alibaba-inc.com/zhiji/imgtoolkit_video:nightly-dev
docker启动命令:sudo docker run -ti --name hengsong3 --net=host reg.docker.alibaba-inc.com/zhiji/imgtoolkit_video:nightly-dev bash (注意,如果加了-name,可以重复使用,装的docker环境都在的,如果不加name,每次退出后自己装的docker环境就不复存在了,如果需要基于这个搞自己的docker,可以联系之己)
docker attach命令:sudo docker attach hengsong3
docker 重启命令: sudo docker restart hengsong3
- 得到最新的query top10000及其embedding 向量
graph_embedding.jl_jingyan_query_related_top_query
(1)得到最新分区query表
create table hs_jingyan_query_related_top_query_1 as
select row_number()over() as index, query from graph_embedding.jl_jingyan_query_related_top_query where ds=max_pt('graph_embedding.jl_jingyan_query_related_top_query');
(2)过滤
create table hs_jingyan_query_related_top_query_2 (index bigint, query_origin string, query string);
需要去掉的词:
旗舰店
旗舰
官方
官网
pai -name pytorch -project algo_public_dev -Dpython=3.6 -Dscript="file:///apsarapangu/disk1/hengsong.lhs/origin_deep_cluster_odps_5.tar.gz" -DentryFile="test_query_with_title.py" -Dtables="odps://graph_embedding/tables/hs_tmp_13,odps://graph_embedding/tables/hs_jingyan_query_related_top_query_1" -Doutputs="odps://graph_embedding/tables/hs_jingyan_query_related_top_query_2" -Dbucket="oss://bucket-automl/" -Darn="acs:ram::1293303983251548:role/graph2018" -Dhost="cn-hangzhou.oss-internal.aliyun-inc.com" -DuserDefinedParameters="" -DworkerCount=1;
(3)得到最新的embedding向量
create table hs_jingyan_query_related_top_query_3 as SELECT index as id, query_origin, query, search_kg:alinlp_word_embedding(query, "100", "MAINSE") as query_emb from hs_jingyan_query_related_top_query_2;
- 只取query第一页的结果
jl_jingyan_query_related_top_query_detailed
create table hs_tmp_18 as select se_keyword, item_list from jl_jingyan_query_related_top_query_detailed where page_seq == 1;
create table hs_tmp_19 as select bi_udf:bi_split_value(se_keyword, item_list, ",") as (query, item_id) from hs_tmp_18;
create table hs_tmp_20 as
select distinct b.query, a.* from
(select item_id, cate_id, cate_name from tbcdm.dim_tb_itm where ds=max_pt('tbcdm.dim_tb_itm'))a join (select query, item_id from hs_tmp_19)b on a.item_id == b.item_id;
- 将query第一页和query最新分区结果联合(为每个query确定id)
create table hs_leaf_class_for_query_1 as
select distinct a.id as id, a.query_origin as query, b.cate_id, b.cate_name from
((select index, query_origin, query from hs_jingyan_query_related_top_query_3)a join (select query, item_id, cate_id, cate_name from hs_tmp_20)b on a.query_origin == b.query) where a.index == 4;
只取第一页的结果:query数量降为原来的1/3
- 说两句
使用视频embedding作为中心点可以得到比较不错的结果
叶子类目的过滤效果很好
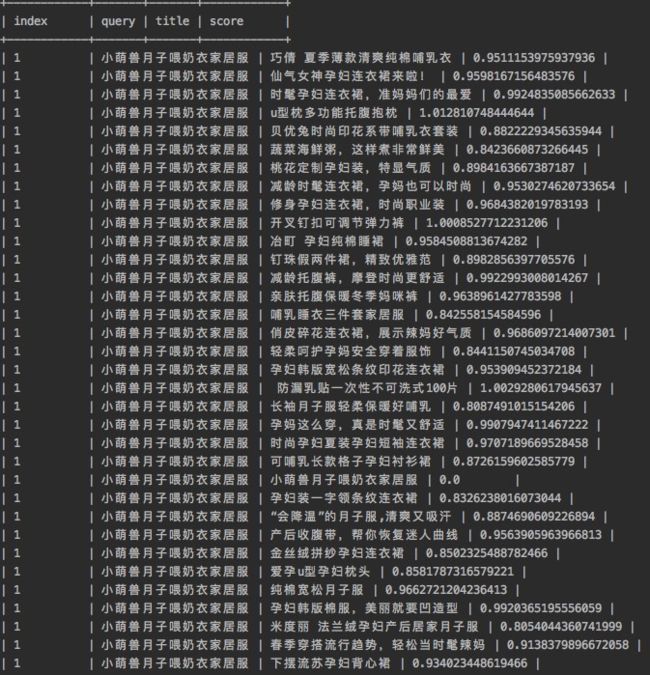
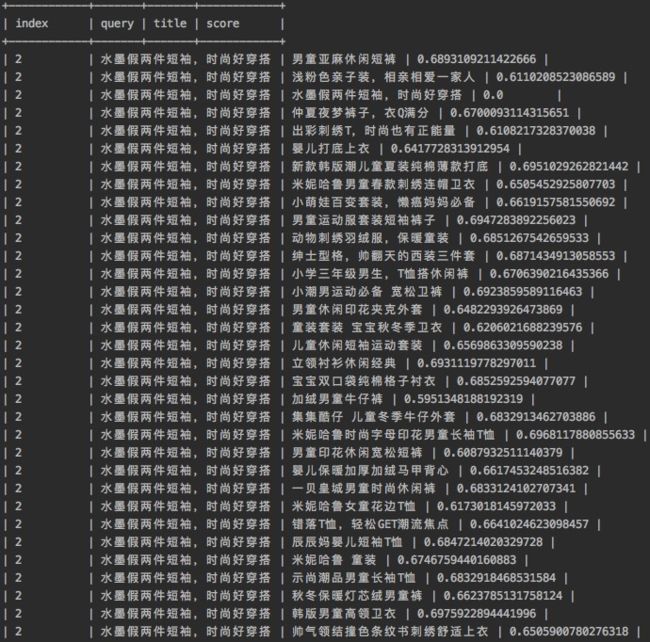
- hs_result_title_query_1w_top1000_only1page_filtered_1