Hive的进阶(表的操作等)
一、Hive对数据库的基本操作-库、表
1.1规则语法
注释语法:
- – – 单行注释
- // 单行注释
- /*
*多行注释
*/
大小写规则:
- Hive的数据库名、表名都不区分大小写
- 建议关键字大写
命名规则
- 名字不能使用数字开头
- 不能使用关键字
- 尽量不使用特殊符号
- 如果表比较多,那么表名和字段名可以定义规则加上前缀
快速创建库和表:
– hive有⼀个默认的数据库default,如果不明确的说明要使用哪个库,则使用默认数据
库。
hive> create database zoo;
hive> create database if not exists zoo;
hive> create database if not exists qfdb comment ‘this is a database of xxx’;
– 创建库的本质:在hive的warehouse目录下创建⼀个目录(库名.db命名的目录)
– 切换库:
hive> use zoo;
–创建表
hive> create table t_user(id int,name string);
– 使用库+表的形式创建表:
hive> create table qfdb.t_user(id int,name string);
二、建表语法
Hive的数据类型分为基本数据类型和复杂数据类型,下面是基本数据类型(复杂类型暂无)
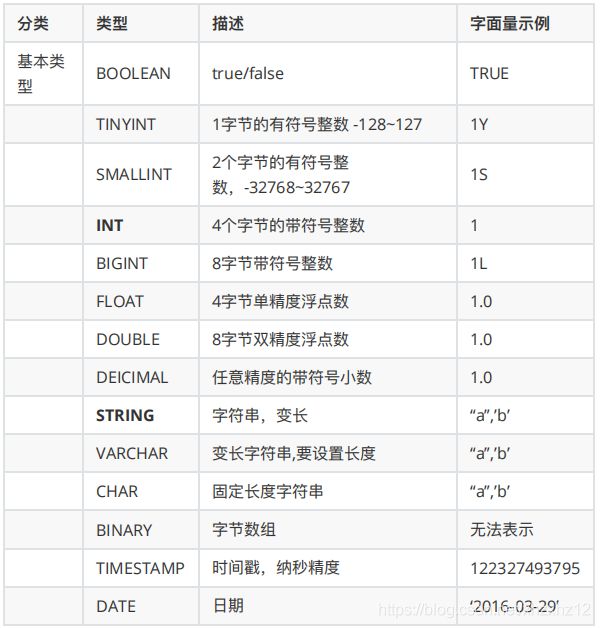
下面是⼀个常见的创建表的语法:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] TABLENAME
[COLUMNNAME COLUMNTYPE [COMMENT 'COLUMN COMMENT'],...]
[COMMENT 'TABLE COMMENT']
[PARTITIONED BY (COLUMNNAME COLUMNTYPE [COMMENT 'COLUMN
COMMENT'],...)]
[CLUSTERED BY (COLUMNNAME COLUMNTYPE [COMMENT 'COLUMN
COMMENT'],...) [SORTED BY (COLUMNNAME [ASC|DESC])...] INTO
NUM_BUCKETS BUCKETS]
[ROW FORMAT ROW_FORMAT]
[STORED AS FILEFORMAT]
[LOCATION HDFS_PATH];
如果要看完整的创建表语法,可以参考下面完整创建表语句:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS]
[db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later) ]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
其中具体创建表的参数类型可以参考如下:
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0
and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available
in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13
and later)
| SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat
configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT
output_format_classname
column_constraint_specification:
: [ PRIMARY KEY|UNIQUE|NOT NULL|DEFAULT [default_value]|CHECK
[check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
default_value:
: [
LITERAL|CURRENT_USER()|CURRENT_DATE()|CURRENT_TIMESTAMP()|NULL ]
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...)
REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
[, CONSTRAINT constraint_name UNIQUE (col_name, ...) DISABLE
NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name CHECK [check_expression]
ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
简单例子:
create table t_user
(
id int,
name string
)
设置按照 '\t' 进行读取文件内容,'\n' 换行
row format delimited fields terminated by '\t' lines terminated by '\n';
三、查看表
查看当前数据库中的表:
# 查看当前数据库的表
show tables;
# 查看另外⼀个数据库中的表
show tables in zoo;
查看表结构
# 查看表信息
desc tableName;
# 查看详细信息
desc formatted tableName;
#查看创建表信息
show create table tableName;
四、表类型详解
4.1表分类
在Hive中,表类型主要分为两种:
- 内部表: 也叫管理表,表目录会创建在hdfs的/user/hive/warehouse/下的相应的库对应的目录中。
- 外部表: 外部表会根据创建表时LOCATION指定的路径来创建目录,如果没有指定LOCATION,则位置跟内部表相同,⼀般使用的是第三方提供的或者公用的数
据。
4.2两者之间区别
内部表和外部表在创建时的差别:
就差两个关键字,EXTERNAL LOCATION 举例:
- 内部表
CREATE TABLE T_INNER(ID INT);
- 外部表
CREATE EXTERNAL TABLE T_OUTER(ID INT) LOCATION 'HDFS:///AA/BB/XX';
Hive表创建时要做的两件事:
- 在HDFS下创建表目录
- 在元数据库Mysql创建相应表的描述数据(元数据)
drop时有不同的特性:
1、drop时,元数据都会被清除
2、drop时,内部表的表目录会被删除,但是外部表的表目录不会被删除。
使用场景
- 内部表:平时用来测试或者少量数据,并且自己可以随时修改删除数据.
- 外部表:使用后数据不想被删除的情况使用外部表(推荐使用)所以,整个数据仓库的最底层的表使用外部表
五、数据加载
数仓简单介绍

create table if not exists qfuser(
id int,
name string
)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile;
-- 创建表的本质:在使⽤的库⽬录下创建⼀个⽬录(⽬录名就是表名)
5.1加载数据
构建数据
[root@master hive]# mkdir /hivedata
[root@master hive]# cd /hivedata
[root@master hive]# vi user.txt
-- 加⼊下⾯的数据
1,廉德枫
2,刘浩
3,王鑫
4,司翔
加载数据到Hive
加载⼀般分为两种:
- ⼀种是从本地Linux上加载到Hive中
- 另外⼀种是从HDFS加载到Hive中
-- 常⽤⽅式:
[root@master hive]# load data [local] inpath '/hivedata/user.txt' [overwrite] into table t_user;
-- 从hdfs导⼊user.txt 如果没有加⼊row format ,那么导⼊的全是null
--#提前在root⽬录下上传数据上去
[root@master hive]# hdfs dfs -put /hivedata/user.csv/user/root/user.csv
-- 从hdfs中加载数据
[root@master hive]# load data inpath 'user.csv' into table qfuser;
-- 从本地加载数据
[root@master hive]# load data local inpath '/hivedata/user.csv' into table qfuser;
加载数据的本质:
- 如果数据在本地,加载数据的本质就是将数据copy到hdfs上的表目录下。
- 如果数据在hdfs上,加载数据的本质是将数据移动到hdfs的表目录下。
注意:Hive使用的是严格的读时模式:加载数据时不检查数据的完整性,读时发
现数据不对则使用NULL来代替。 而Mysql使用的是写时模式:在写入数据时就进行检查
5.2 insert into 方式灌入数据
先创建⼀个和旧表结构⼀样的表:
create table qfusernew(
id int,
name string
) comment 'this is a table'
然后把旧表的数据可以通过查询条件灌入到新表
insert into qfusernew
select * from qfuser where id < 3;
5.3克隆表
5.3.1不带数据,只克隆表的结构
-- 从qfusernew 克隆新的表结构到qfuserold
create table if not exists qfuserold like qfusernew;
5.3.2克隆表并带数据
#如果当前数据库是zoo,那么在下⾯warehouse后要加上当前数据库的名字 zoo.db
create table if not exists t5 like qfusernew location '/user/hive/warehouse/qfusernew';
# 查询t5 有具体的数据
select * from t5;
OK
1 zhang
2 li
在创建表时候也可以通过指定location来指定数据位置
create table if not exists t6(
id int,
name string
) comment 'this is a table'
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/user/hive/warehouse/qfusernew';
-- 注意location后⾯接的⼀定是hdfs中的⽬录,不是⽂件
5.3.3克隆表并带数据
用as是更灵活的方式 , 跟创建表的方式⼀样,元数据和目录都会创建。
create table t7
as
select * from t6;
-- 查看库描述:
desc/describe database [extended] qf1704;
-- 查看表描述:
desc/describe [extended] t7;
-- 查看表结构信息
desc formatted t7;
-- 查看表创建语句,⽐较全
show create table t7;
5.3.4示例
创建表
CREATE TABLE log1(
id string COMMENT 'this is id column',
mac string,
phonenumber bigint,
ip string,
url string,
status1 string,
status2 string,
upflow int,
downflow int,
status3 string,
dt string
)
COMMENT 'this is log table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ' '
LINES TERMINATED BY '\n'
stored as textfile;
# 在hive提示符下加载数据:
[root@master hive]# load data local inpath '/opt/soft/hive/hivedata/data.txt' into table log1;
# 1、统计每个电话号码的总流量(M)
select l.phonenumber,
round(sum(l.upflow + l.downflow) / 1024.0,2) as total
from log1 l
group by l.phonenumber;
# 2、第⼆个需求,求访问次数排名前3的url:
select l.url url,
count(l.url) as urlcount
from log1 l
group by l.url
order by urlcount desc
limit 3;
六、表属性修改
6.1修改表名:rename to
alter table t7 rename to a1;
6.2修改列名:change column
alter table a1 change column name name1 string;
6.3修改列的位置:change column
alter table log1 change column ip string after status1;
alter table log1 change column mac string first;
6.4修改字段类型:change column
alter table a1 change column name string;
6.5增加字段:add columns
alter table a1 add columns (sex int);
6.6 替换字段:replace columns
alter table a1 replace columns(
id int,
name string,
size int,
pic string
);
6.7内部表和外部表转换:
alter table a1 set tblproperties('EXTERNAL'='TRUE'); #内部表转外部表,true⼀定要⼤写;
alter table a1 set tblproperties('EXTERNAL'='false');#false⼤⼩写都没有关系
七、Hive Shell技巧
7.1 查看所有hive参数
# 在hive命令⾏直接输⼊set 即可
hive> set
7.2只执行⼀次Hive命令
通过shell的参数 -e 可以执行一次就运行完的命令
[root@master hive]# hive -e "select * from cat"
小技巧2:可以通过外部命令快速查询某个变量值:hive -S -e “set” |grep cli.print
-S 是静默模式,会省略到多余的输出
7.3单独执行⼀个sql文件
通过参数-f +file文件名就可以,经常用在以后的sql文件单独执行,导入数据场景中
[root@master hive]# hive -f /path/cat.sql
7.4执行Linux命令
在Hive的shell中 加上前缀! 最后以分号;结尾,可以执⾏linux的命令
hive> ! pwd ;
7.5执行HDFS命令
用户可以在Hive的shell中执行HDFS的DFS命令,不用敲入前缀hdfs或者hadoop
hive> dfs -ls /tmp
7.6使用历史命令和自动补全
在Hive的Shell操作中可以使用上下箭头查看历史记录
如果忘记了命令可以用tab键进行补全
7.7显示当前库:
下面是通过配置文件 hive-site.xml 显示
hive.cli.print.current.db
false
Whether to include the current database in the Hive prompt.
7.8当前session⾥设置该参数:
hive> set hive.cli.print.current.db=true;
7.9查看当前参数设置的值:
小技巧1:可以在shell中输⼊set命令,可以看到hive已经设定好的参数
hive> set hive.cli.print.current.db;