CDA LEVEL2 大纲解析案例题Python实现代码
数据下载:
http://exam.cda.cn/static/exam_attachment/L2jmjxshiti.zip
导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
pd.options.display.max_columns = None
train_data = pd.read_csv('broadband_TrainingData.csv')
train_data.describe()
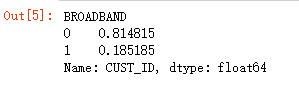
Q1:在训练数据集中,有接受服务(BROADBAND=1)的用户比例为何?
#方法一
train_data[train_data['BROADBAND']==1].shape[0] / train_data.shape[0]
#方法二
train_data.groupby('BROADBAND')['CUST_ID'].count() / train_data.shape[0]
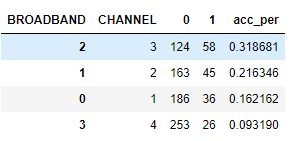
Q2:在训练数据集中,哪两个申办通路(CHANNEL)用户接受服务的比例较高?
channel_pivot = train_data.pivot_table(index='CHANNEL', columns='BROADBAND', values='CUST_ID', aggfunc='count').reset_index()
channel_pivot['acc_per'] = channel_pivot[1] / (channel_pivot[0]+channel_pivot[1])
channel_pivot = channel_pivot.sort_values(by='acc_per', ascending=False)
channel_pivot
Q3:在训练集中,以下哪些描述是正确的?
A.用户往来期间(TENURE)越高者,接受服务的比例越高;
B.年龄(AGE)越大者,接受服务的比例越高;
C.最近3个月平均电话费(ARPB_3M)越高者,接受服务的比例越低;
D.有办自动转账扣缴(AUTOPAY)者,接受服务的比例越高。
# A:TENURE
quartiles = pd.cut(np.sort(train_data['TENURE'].unique()), list(range(0, 75, 3))) #这边按步长3分组
grouped = train_data.groupby('TENURE')['BROADBAND'].agg(['count', 'sum']).reset_index()
new_grouped = grouped.groupby(quartiles)['count', 'sum'].sum()
new_grouped['acc_per'] = new_grouped['sum'] / new_grouped['count']
new_grouped['acc_per'].plot.bar()
# B:AGE
quartiles = pd.cut(np.sort(train_data['AGE'].unique()), list(range(0, 80, 3))) #这边按步长3分组
grouped = train_data.groupby('AGE')['BROADBAND'].agg(['count', 'sum']).reset_index()
new_grouped = grouped.groupby(quartiles)['count', 'sum'].sum()
new_grouped['acc_per'] = new_grouped['sum'] / new_grouped['count']
new_grouped['acc_per'].plot.bar()
# C:ARPB_3M
quartiles = pd.cut(np.sort(train_data['ARPB_3M'].unique()), list(range(0, 1400, 100))) #这边按步长3分组
grouped = train_data.groupby('ARPB_3M')['BROADBAND'].agg(['count', 'sum']).reset_index()
new_grouped = grouped.groupby(quartiles)['count', 'sum'].sum()
new_grouped['acc_per'] = new_grouped['sum'] / new_grouped['count']
new_grouped['acc_per'].plot.bar()
# D:AUTOPAY
grouped = train_data.groupby('AUTOPAY')['BROADBAND'].agg(['count', 'sum']).reset_index()
grouped['acc_per'] = grouped['sum'] / grouped['count']
grouped['acc_per'].plot.bar()
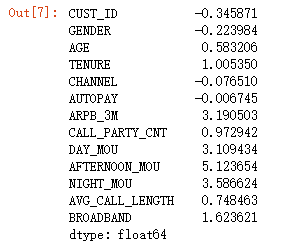
Q4:在训练数据集中,以下哪些字段的分布是属于右偏?
A、ARPB_3M
B、TENURE
C、NIGHT_MOU
D、以上皆非
#偏度大于0是右偏
train_data.skew()
Q5:在训练数据集中,以平均值法来侦测离群值(Outlier),以下哪些字段会有离群值的出现?
A、AGE B、TENURE C、AFTERNOON_MOU D、DAY_MOU
def find_outlier(df):
'''侦测离群值'''
if (t_mean - 3*t_std) <= df[col_name] <= (t_mean + 3*t_std):
return 1
else:
return 0
for col_name in ['AGE', 'TENURE', 'AFTERNOON_MOU', 'DAY_MOU']:
df_temp = train_data.copy()
t_mean = train_data[col_name].mean()
t_std = train_data[col_name].std()
df_temp['answer'] = df_temp.apply(find_outlier, axis=1)
if df_temp['answer'].sum() == df_temp.shape[0]:
print('{}无离群值'.format(col_name))
else:
print('{}有离群值,个数为{}'.format(col_name, df_temp.shape[0] - df_temp['answer'].sum()))

Q6:在训练数据集中,最近3个月平均电话费(ARPB_3M)经分析也有严重的离群值出现,利用平均法计算出其值的上线为625.请将ARPB_3M>625的记录筛选出来,其有接受服务(BROADBAND=1)的用户比例为何?
A、70.23% B、14.29% C、85.71% D、65.71%
train_data[train_data['ARPB_3M']>625]['BROADBAND'].sum()/train_data[train_data['ARPB_3M']>625]['BROADBAND'].count()
Q7:下列的描述何者是正确的?
A、无效的字段包括不相关(Irrelevant)及多余(Redundant)的字段
B、多余的字段可通过统计的检验来加以排除
C、可用卡方检验来检验TENUNE与目标字段BROADBAND的相关性
D、可用AVOVA检验来检验AFTERNOON_MOU与目标字段BROADBAND的相关性

Q8:在训练数据集中,请根据统计的检验的计算结果,分析以下哪个字段是最不重要的字段?
A、TENURE B、AGE C、AVG_CALL_LENGTH D、NIGHT_MOU
import statsmodels.stats.anova as anova
from statsmodels.formula.api import ols
for col in ['TENURE', 'AGE', 'AVG_CALL_LENGTH', 'NIGHT_MOU']:
print(col + '的ANOVA结果是:')
print(anova.anova_lm(ols('{}~BROADBAND'.format(col),train_data).fit()))
print('\n')
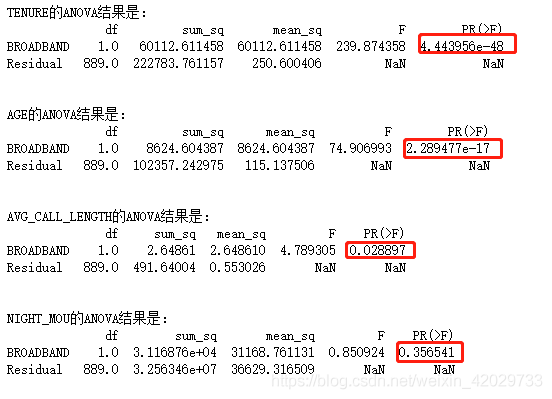
红色部分越大的越不重要