2021年最新微博爬取评论及制作词云(2021.4.25)
课上老师留了作业做这个花了一小会时间做了一下,分享下过程。
一.首先我们选择微博移动端去爬取即这个网址微博移动版
二.登陆后获取到我们的cookie和user-agent,存下来一会会用。
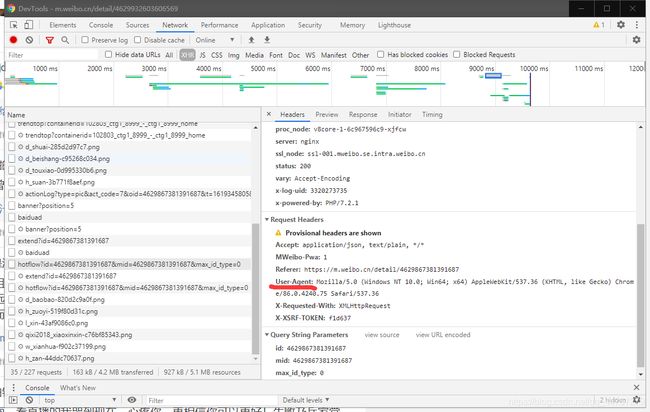

三.分析评论url,我们可以发现往下翻评论时每次可获得一个url,一个url中包含几十条评论,找到规律如下:
第一个为:https://m.weibo.cn/comments/hotflow?id=4629867381391687&mid=4629867381391687&max_id_type=0
第二个为:https://m.weibo.cn/comments/hotflow?id=4629867381391687&mid=4629867381391687&max_id=187367128830156&max_id_type=0
其中第二个比第一个多了个max_id,我们在第一个url中能找到这个max_id如下: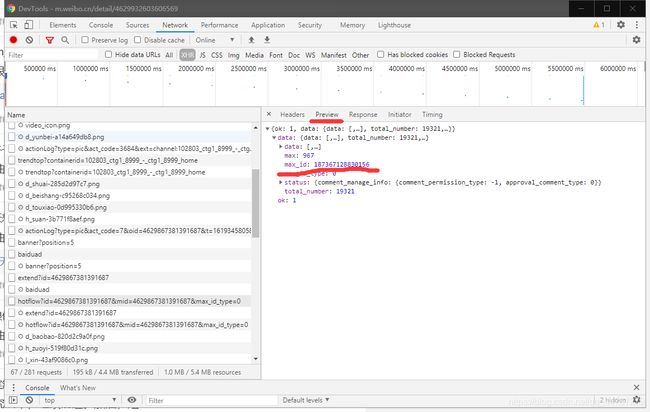
之后第三个的max_id也由第二个url中的max_id提供,微博通过这样的机制就保证了评论的一个连续性。从而也让我们找到了爬虫的书写方法。代码如下:
# 商业转载请联系作者获得授权,非商业转载请注明出处。
# For commercial use, please contact the author for authorization. For non-commercial use, please indicate the source.
# 协议(License):署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
import requests
import json
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0',
'Cookie': ''#此处加入自己的cookie
}
max_id = ""
text_sum = 0
ping_sum = 0
def get_comment():
global max_id, text_sum,ping_sum
max_id_type = 0
if text_sum >= 14:
max_id_type = 1
else:
max_id_type = 0
url = 'https://m.weibo.cn/comments/hotflow?id=4602765680061207&mid=4602765680061207&max_id=' + str(
max_id) + '&max_id_type=' + str(max_id_type)
print(url)
html = requests.get(url, headers=headers)
print(html.content.decode())
html_text = json.loads(html.text) # 把获得数据转换成字典格式
print(html_text)
for i in html_text['data']['data']:
ping_sum+=1
text = i['text']
# print(text)
without_img = re.compile(r'', re.S)
true_text = re.sub(without_img, '', text) # 去掉链接
print(true_text)
with open('D:\\text.txt', "a", encoding="utf8") as f:
f.write(true_text + '\n')
max_id = html_text['data']['max_id']
text_sum += 1
print(text_sum)
print(ping_sum)
if __name__ == '__main__':
# 爬取第一页
url = 'https://m.weibo.cn/comments/hotflow?id=4602765680061207&mid=4602765680061207&' + '&max_id_type=0'
html = requests.get(url, headers=headers)
html_text = json.loads(html.text)
for i in html_text['data']['data']:
text = i['text']
print(text)
without_img = re.compile(r'', re.S)
true_text = re.sub(without_img, '', text)
with open('D:\\text.txt', "a", encoding="utf8") as a:
a.write(true_text + '\n')
# 爬取第一页往后
max_id = html_text['data']['max_id']
print(max_id)
for i in range(2, 50):
get_comment()
其中max_id_type这个东西在十五次以后就会变成1,故在代码中也进行了特判。以上代码使用只需要将第二条中你自己的cookie复制上去,并在python3.6下安装好库即可运行。如果想爬取其他微博,只需要更改代码中的url中的id和mid,他们两个是一样的。这个id每次你打开任意一条微博网页端在地址栏都有。
另附上制作词云代码:
# 商业转载请联系作者获得授权,非商业转载请注明出处。
# For commercial use, please contact the author for authorization. For non-commercial use, please indicate the source.
# 协议(License):署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
path_txt='D://text.txt'
f = open(path_txt,'r',encoding='UTF-8').read()
cut_text = " ".join(jieba.cut(f))
wordcloud = WordCloud(
#设置字体
font_path="C:/Windows/Fonts/simfang.ttf",
#设置了背景,宽高
background_color="white",width=1500,height=1080).generate(cut_text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()