原文链接深入理解GCD之dispatch_semaphore
再研究完dispatch_queue之后,本来是打算进入到dispath_group的源码,但是dispath_group基本是围绕着dispatch_semaphore即信号量实现的,所以我们先进入到dispatch_semaphore的源码学习。在GCD中使用dispatch_semaphore用来保证资源使用的安全性(队列的同步执行就是依赖信号量实现)。可想而知,dispatch_semaphore的性能应该是不差的。
dispatch_semaphore_t
dispatch_semaphore_s是信号量的结构体。代码如下:
struct dispatch_semaphore_s {
DISPATCH_STRUCT_HEADER(dispatch_semaphore_s, dispatch_semaphore_vtable_s);
long dsema_value; //当前信号量
long dsema_orig; //初始化信号量
size_t dsema_sent_ksignals;
#if USE_MACH_SEM && USE_POSIX_SEM
#error "Too many supported semaphore types"
#elif USE_MACH_SEM
semaphore_t dsema_port;
semaphore_t dsema_waiter_port;
#elif USE_POSIX_SEM
sem_t dsema_sem;
#else
#error "No supported semaphore type"
#endif
size_t dsema_group_waiters;
struct dispatch_sema_notify_s *dsema_notify_head; //notify链表头部
struct dispatch_sema_notify_s *dsema_notify_tail; //notify链表尾部
};
typedef mach_port_t semaphore_t;
struct dispatch_sema_notify_s {
struct dispatch_sema_notify_s *volatile dsn_next; //下一个信号节点
dispatch_queue_t dsn_queue; //操作的队列
void *dsn_ctxt; //上下文
void (*dsn_func)(void *); //执行函数
};
虽然上面还有一些属性不知道是做什么作用的,但我们继续往下走。
dispatch_semaphore_create
dispatch_semaphore_create用于信号量的创建。
dispatch_semaphore_t
dispatch_semaphore_create(long value)
{
dispatch_semaphore_t dsema;
// If the internal value is negative, then the absolute of the value is
// equal to the number of waiting threads. Therefore it is bogus to
// initialize the semaphore with a negative value.
if (value < 0) {//value必须大于等于0
return NULL;
}
//申请dispatch_semaphore_s的内存
dsema = calloc(1, sizeof(struct dispatch_semaphore_s));
if (fastpath(dsema)) {
//设置dispatch_semaphore_s 的操作函数
dsema->do_vtable = &_dispatch_semaphore_vtable;
//设置链表尾部
dsema->do_next = DISPATCH_OBJECT_LISTLESS;
//引用计数
dsema->do_ref_cnt = 1;
dsema->do_xref_cnt = 1;
//目标队列的设置
dsema->do_targetq = dispatch_get_global_queue(
DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
//当前信号量和初始化信号的赋值
dsema->dsema_value = value;
dsema->dsema_orig = value;
#if USE_POSIX_SEM
int ret = sem_init(&dsema->dsema_sem, 0, 0);
DISPATCH_SEMAPHORE_VERIFY_RET(ret);
#endif
}
return dsema;
}
上面的源码中dsema->do_vtable = &_dispatch_semaphore_vtable;
_dispatch_semaphore_vtable定义如下:
const struct dispatch_semaphore_vtable_s _dispatch_semaphore_vtable = {
.do_type = DISPATCH_SEMAPHORE_TYPE,
.do_kind = "semaphore",
.do_dispose = _dispatch_semaphore_dispose,
.do_debug = _dispatch_semaphore_debug,
};
这里有个_dispatch_semaphore_dispose函数就是信号量的销毁函数。代码如下:
static void
_dispatch_semaphore_dispose(dispatch_semaphore_t dsema)
{
//信号量的当前值小于初始化,会发生闪退。因为信号量已经被释放了
if (dsema->dsema_value < dsema->dsema_orig) {
DISPATCH_CLIENT_CRASH(
"Semaphore/group object deallocated while in use");
}
#if USE_MACH_SEM
kern_return_t kr;
//释放信号,这个信号是dispatch_semaphore使用的信号
if (dsema->dsema_port) {
kr = semaphore_destroy(mach_task_self(), dsema->dsema_port);
DISPATCH_SEMAPHORE_VERIFY_KR(kr);
}
//释放信号,这个信号是dispatch_group使用的信号
if (dsema->dsema_waiter_port) {
kr = semaphore_destroy(mach_task_self(), dsema->dsema_waiter_port);
DISPATCH_SEMAPHORE_VERIFY_KR(kr);
}
#elif USE_POSIX_SEM
int ret = sem_destroy(&dsema->dsema_sem);
DISPATCH_SEMAPHORE_VERIFY_RET(ret);
#endif
_dispatch_dispose(dsema);
}
dispatch_semaphore_wait
创建好一个信号量后就会开始进入等待信号发消息。
long
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout)
{
//原子性减1,这里说明dsema_value是当前信号值,并将新值赋给value
long value = dispatch_atomic_dec2o(dsema, dsema_value);
dispatch_atomic_acquire_barrier();
if (fastpath(value >= 0)) {
//说明有资源可用,直接返回0,表示等到信号量的信息了
return 0;
}
//等待信号量唤醒或者timeout超时
return _dispatch_semaphore_wait_slow(dsema, timeout);
}
_dispatch_semaphore_wait_slow
在dispatch_semaphore_wait中,如果value小于0,就会执行_dispatch_semaphore_wait_slow等待信号量唤醒或者timeout超时。_dispatch_semaphore_wait_slow的代码如下:
static long
_dispatch_semaphore_wait_slow(dispatch_semaphore_t dsema,
dispatch_time_t timeout)
{
long orig;
again:
// Mach semaphores appear to sometimes spuriously wake up. Therefore,
// we keep a parallel count of the number of times a Mach semaphore is
// signaled (6880961).
//第一部分:
//只要dsema->dsema_sent_ksignals不为零就会进入循环
//dispatch_atomic_cmpxchg2o(dsema, dsema_sent_ksignals, orig,orig - 1)的意思是
//dsema->dsema_sent_ksignals如果等于orig,则将orig - 1赋值给dsema_sent_ksignals,
//并且返回true,否则返回false。
//如果返回true,说明又获取了资源
while ((orig = dsema->dsema_sent_ksignals)) {
if (dispatch_atomic_cmpxchg2o(dsema, dsema_sent_ksignals, orig,
orig - 1)) {
return 0;
}
}
#if USE_MACH_SEM
mach_timespec_t _timeout;
kern_return_t kr;
//第二部分:dispatch_semaphore_s中的dsema_port赋值,以懒加载的形式
_dispatch_semaphore_create_port(&dsema->dsema_port);
// From xnu/osfmk/kern/sync_sema.c:
// wait_semaphore->count = -1; /* we don't keep an actual count */
//
// The code above does not match the documentation, and that fact is
// not surprising. The documented semantics are clumsy to use in any
// practical way. The above hack effectively tricks the rest of the
// Mach semaphore logic to behave like the libdispatch algorithm.
//第三部分:
switch (timeout) {
default:
//计算剩余时间,调用mach内核的等待函数semaphore_timedwait()进行等待。
//如果在指定时间内没有得到通知,则会一直阻塞住,监听dsema_port等待其通知;
//当超时的时候,会执行下面的case代码(这个default没有break)。
do {
uint64_t nsec = _dispatch_timeout(timeout);
_timeout.tv_sec = (typeof(_timeout.tv_sec))(nsec / NSEC_PER_SEC);
_timeout.tv_nsec = (typeof(_timeout.tv_nsec))(nsec % NSEC_PER_SEC);
kr = slowpath(semaphore_timedwait(dsema->dsema_port, _timeout));
} while (kr == KERN_ABORTED);
if (kr != KERN_OPERATION_TIMED_OUT) {
DISPATCH_SEMAPHORE_VERIFY_KR(kr);
break;
}
// Fall through and try to undo what the fast path did to
// dsema->dsema_value
case DISPATCH_TIME_NOW:
//若当前信号量desma_value小于0,对其加一并返回超时信号KERN_OPERATION_TIMED_OUT。
//KERN_OPERATION_TIMED_OUT代表等待超时而返回
//由于一开始在第一部分代码中进行了减1操作,所以需要加1以撤销之前的操作。
while ((orig = dsema->dsema_value) < 0) {
if (dispatch_atomic_cmpxchg2o(dsema, dsema_value, orig, orig + 1)) {
return KERN_OPERATION_TIMED_OUT;
}
}
// Another thread called semaphore_signal().
// Fall through and drain the wakeup.
case DISPATCH_TIME_FOREVER:
//一直等待直到有信号。当有信号的时候说明dsema_value大于0,会跳转到again,重新执行本函数的流程
do {
kr = semaphore_wait(dsema->dsema_port);
} while (kr == KERN_ABORTED);
DISPATCH_SEMAPHORE_VERIFY_KR(kr);
break;
}
#elif USE_POSIX_SEM
//此处的代码省略,跟上面USE_MACH_SEM代码类似
#endif
goto again;
}
在上面的源码还有几个地方需要注意:
第一部分的那个while循环和if条件。在
dsema_sent_ksignals非0的情况下便会进入while循环,if的条件是dsema->dsema_sent_ksignals如果等于orig,则将orig - 1赋值给dsema_sent_ksignals,并且返回true,否则返回false。很明显,只要能进入循环,这个条件是一定成立的,函数直接返回0,表示等到信号。而在初始化信号量的时候没有对dsema_sent_ksignals赋值,所以就会进入之后的代码。也就是说没有信号量的实际通知或者遭受了系统异常通知,并不会解除等待在上面中出现了
semaphore_timedwait和semaphore_wait。这些方法是在semaphore.h中的。所以说dispatch_semaphore是基于mach内核的信号量接口实现的。另外这两个方法传入的参数是dsema_port即dsema_port被mach内核semaphore监听,所以我们理解dsema_port是dispatch_semaphore的信号。我们回过头再看一下
dispatch_semaphore_s结构体中的dsema_waiter_port。全局搜索一下可以发现,这个属性是用在dispatch_group中。之前也说了dispatch_group的实现是基于dispatch_semaphore,在dispatch_group里semaphore_wait监听的并不是dsema_port而是dsema_waiter_port。
dispatch_semaphore_wait流程如下图所示:

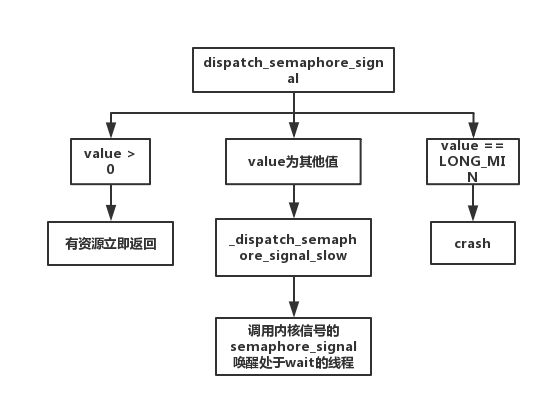
dispatch_semaphore_signal
发送信号的代码相对等待信号来说简单很多,它不需要阻塞,只发送唤醒。
long
dispatch_semaphore_signal(dispatch_semaphore_t dsema)
{
dispatch_atomic_release_barrier();
//原子性加1,value大于0 说明有资源立即返回
long value = dispatch_atomic_inc2o(dsema, dsema_value);
if (fastpath(value > 0)) {
return 0;
}
if (slowpath(value == LONG_MIN)) {
DISPATCH_CLIENT_CRASH("Unbalanced call to dispatch_semaphore_signal()");
}
return _dispatch_semaphore_signal_slow(dsema);
}
_dispatch_semaphore_signal_slow
long
_dispatch_semaphore_signal_slow(dispatch_semaphore_t dsema)
{
// Before dsema_sent_ksignals is incremented we can rely on the reference
// held by the waiter. However, once this value is incremented the waiter
// may return between the atomic increment and the semaphore_signal(),
// therefore an explicit reference must be held in order to safely access
// dsema after the atomic increment.
_dispatch_retain(dsema);
(void)dispatch_atomic_inc2o(dsema, dsema_sent_ksignals);
#if USE_MACH_SEM
_dispatch_semaphore_create_port(&dsema->dsema_port);
kern_return_t kr = semaphore_signal(dsema->dsema_port);
DISPATCH_SEMAPHORE_VERIFY_KR(kr);
#elif USE_POSIX_SEM
int ret = sem_post(&dsema->dsema_sem);
DISPATCH_SEMAPHORE_VERIFY_RET(ret);
#endif
_dispatch_release(dsema);
return 1;
}
_dispatch_semaphore_signal_slow的作用就是内核的semaphore_signal函数唤醒在dispatch_semaphore_wait中等待的线程量,然后返回1。
dispatch_semaphore_signal流程如下图所示:
总结
dispatch_semaphore是基于mach内核的信号量接口实现的调用
dispatch_semaphore_wait信号量减1,调用dispatch_semaphore_signal信号量加1在
wait中,信号量大于等于0代表有资源立即返回,否则等待信号量或者返回超时;在signal中,信号量大于0代表有资源立即返回,否则唤醒某个正在等待的线程dispatch_semaphore利用了两个变量desma_value和dsema_sent_ksignals来处理wait和signal,在singnal中如果有资源,则不需要唤醒线程,那么此时只需要使用desma_value。当需要唤醒线程的时候,发送的信号是dsema_sent_ksignals的值,此时会重新执行wait的流程,所以在wait中一开始是用dsema_sent_ksignals做判断。再看一下
dispatch_semaphore_s结构体的变量。
struct dispatch_semaphore_s {
DISPATCH_STRUCT_HEADER(dispatch_semaphore_s, dispatch_semaphore_vtable_s);
long dsema_value; //当前信号量
long dsema_orig; //初始化信号量
size_t dsema_sent_ksignals; //唤醒时候的信号量
#if USE_MACH_SEM && USE_POSIX_SEM
#error "Too many supported semaphore types"
#elif USE_MACH_SEM
semaphore_t dsema_port; //结构体使用的semaphore信号
semaphore_t dsema_waiter_port;//dispatch_group使用的使用的semaphore信号
#elif USE_POSIX_SEM
sem_t dsema_sem;
#else
#error "No supported semaphore type"
#endif
size_t dsema_group_waiters;
struct dispatch_sema_notify_s *dsema_notify_head; //notify链表头部
struct dispatch_sema_notify_s *dsema_notify_tail; //notify链表尾部
};
补充
如何控制线程并发数
方法1:使用信号量进行并发控制
dispatch_queue_t concurrentQueue = dispatch_queue_create("concurrentQueue", DISPATCH_QUEUE_CONCURRENT);
dispatch_queue_t serialQueue = dispatch_queue_create("serialQueue",DISPATCH_QUEUE_SERIAL);
dispatch_semaphore_t semaphore = dispatch_semaphore_create(4);
for (NSInteger i = 0; i < 15; i++) {
dispatch_async(serialQueue, ^{
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
dispatch_async(concurrentQueue, ^{
NSLog(@"thread:%@开始执行任务%d",[NSThread currentThread],(int)i);
sleep(1);
NSLog(@"thread:%@结束执行任务%d",[NSThread currentThread],(int)i);
dispatch_semaphore_signal(semaphore);});
});
}
NSLog(@"主线程...!");
结果

方法2:YYDispatchQueuePool的实现思路
YYKit组件中的YYDispatchQueuePool也能控制并发队列的并发数
在iOS保持界面流畅的技巧原文中提到:
其思路是为不同优先级创建和 CPU 数量相同的 serial queue,每次从 pool 中获取 queue 时,会轮询返回其中一个 queue。我把 App 内所有异步操作,包括图像解码、对象释放、异步绘制等,都按优先级不同放入了全局的 serial queue 中执行,这样尽量避免了过多线程导致的性能问题。