OpenCV3实现人脸识别(三)——训练与识别自己的人脸数据
前言
1.前面已经演示过使用OpenCV官方分类器实现人脸检测并拍照下要用来训练人脸识别的样本数据,并生成包含有人脸样本的列表文件(.txt)文件。
2.我的编程环境是Windows 7 64位,IDE是VS2015,配置了OpenCV3.3与OpenCV_Contrib,Boost 1.66,其中Boost是用来操作文件和目录用的,是于如果配置以上的环境,可以看我之前写的博文。
3.OpenCV 自带了三个人脸识别算法:Eigenfaces,Fisherfaces 、LBPH(和局部二值模式直方图)。如果想知道它们的工作原理及相互之间的区别,请阅读 OpenCV 的官方文档。
4.我在这里只演示如何使用Eigenfaces来实现人脸识别的训练与测试,如果想测试Fisherfaces和LBPH这两个识别算法,只要把声明与初始化类的部分改成对应的算法就可以了。
一、资源准备
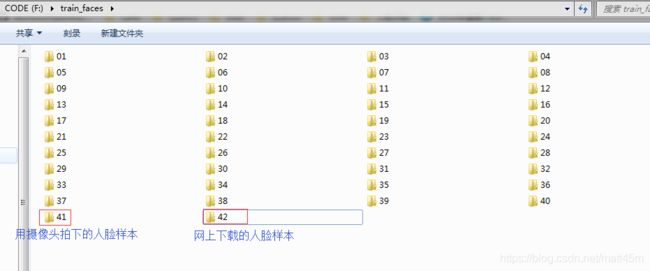
1、要训练之前,应该有两个数据,一个放着人脸样本的文件夹,可以从这里下载我上传好的文件夹。一个是内容里面有人脸样本绝对路径加标签的txt文件,人脸样本的文件夹如下图,41这个文件夹是放着我从摄像头拍下来自己的脸,42这个文件夹是我从网上下载下来的芦田爱菜(Ashida Mana)的人脸图像,因为她的表情真的很丰富,差异相对大一些。
存放训练集的文件夹:
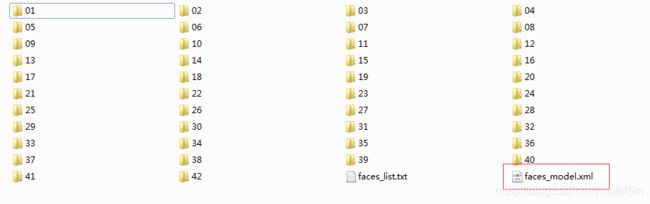
2.然后调用buildList()这个函数,生成内容里有人脸样本绝对路径加标签的txt文件,格式如下图,前是样本数据的绝对路径,分号之后该样本的标签名,分号是用来隔开样本与标签用的,只是方便后面的文件读取。

二、训练代码
这里我给两个方式的读写文件方式的训练代码,一个是从txt文件里读取样本路径和标签代码,一个是使用boost把样本读到到C++ STL容器的训练代码。
1.从txt文件读取样本和标签的代码,使用这个函数的前提是必须在前面生成内容里有人脸样本绝对路径加标签的txt文件,函数的第第一个参数传入txt文件的路径,第二参数是保存模型文件的路径:
trainFacesTxt()函数代码:
void trainFacesTxt(string faces_list, string save_model)
{
//打开人脸列表文件
ifstream face_file(faces_list, ifstream::in);
if(!face_file)
{
std::cout << "无法打开训练集的列表文件!" << endl;
return;
}
string line, path, class_label;
vector faces;
vector labels;
char separator = ';';
while (getline(face_file, line))
{
stringstream liness(line);
//读一行
getline(liness, path, separator);
getline(liness, class_label);
if (!path.empty() && !class_label.empty())
{
//把图像压入容器
faces.push_back(imread(path, 0));
//把标签压入容器
labels.push_back(atoi(class_label.c_str()));
}
}
//判断是否为空
if (faces.size() < 1 || labels.size() < 1)
{
std::cout << "初始化训练集....." << std::endl;
return;
}
int height = faces[0].rows;
int width = faces[0].cols;
std::cout << "训练集的图像的高:" << height << "训练集的图像的宽:" << width << std::endl;
Mat test_sample = faces[faces.size() - 1];
int test_label = labels[labels.size() - 1];
faces.pop_back();
labels.pop_back();
//判断图像类型
for (size_t i = 0; i < faces.size(); i++)
{
if (faces.at(i).type() != CV_8UC1)
{
std::cerr << "图像的类型必须为CV_8UC1!" << endl;
return;
}
}
//检测尺寸等于正样本尺寸第一张的尺寸
Size positive_image_size = faces[0].size();
cout << "正样本的尺寸是:" << positive_image_size << endl;
//遍历所有样品,检测尺寸是否相同
for (size_t i = 0; i < faces.size(); i++)
{
if (positive_image_size != faces[i].size())
{
std::cerr << "所有的样本的尺寸大小不一,请重新调整好样本大小!" << endl;
return;
}
}
//创建一个人脸识别的类
Ptr model = EigenFaceRecognizer::create();
//开始训练
model->train(faces, labels);
// recognition face
int predicted_label = model->predict(test_sample);
std::cout << "样本标签类型为:" << test_label << "预测的样本标签为:" << predicted_label << endl;
//保存训练好的模型
model->write(save_model);
std::cout << "训练完成!" << endl;
}
2.直接用boost库从存放路径读取,这里就不需要提前生成txt,函数的第一个参数是存放人脸样本的目录,第二个是是保存模型的路径和模型的名字。
trainFacesDir()函数代码:
void trainFacesDir(string faces_list,string save_model)
{
vector labels;
vector faces;
multimap faces_labels;
int index = 0;
if (!fs::is_directory(faces_list))
{
std::cerr << "请输入一个合法的路径!" << endl;
return;
}
else if (fs::is_empty(faces_list))
{
std::cerr << "输入路径为空路径!" << endl;
return;
}
//递归遍历当前目录下的子文件
fs::recursive_directory_iterator begin_iter(faces_list);
fs::recursive_directory_iterator end_iter;
for (; begin_iter != end_iter; begin_iter++)
{
string file_path = begin_iter->path().string();
fs::path file_name(file_path);
//判断是否为目录
if (fs::is_directory(file_name))
{
//标签
index++;
}
else
{
// 读取文件夹下的文件level 1表示这是一副训练图,通过multimap容器来建立由类目名称到训练图的一对多的映射
string filename = begin_iter->path().string();
//图像的类型为CV_8CU1
Mat temp = imread(filename,0);
if (temp.empty())
{
continue;
}
pair p(index, temp);
//键名可以重复
faces_labels.insert(p);
}
}
multimap ::iterator i = faces_labels.begin();
//得到要训练的数据集与标签
for (; i != faces_labels.end(); i++)
{
labels.push_back((*i).first);
faces.push_back((*i).second);
}
//从最后一个人脸样品集读出一张图像用来测试
Mat test_sample =faces[faces.size() - 1];
//标签等于最后人脸样品标签
int test_label = labels[labels.size() - 1];
//从容器里删掉最后一张
faces.pop_back();
//标签减1
labels.pop_back();
//判断图像类型
for (size_t i = 0; i < faces.size(); i++)
{
if (faces.at(i).type() != CV_8UC1)
{
std::cerr << "图像的类型必须为CV_8UC1!" << endl;
return;
}
}
//检测尺寸等于正样本尺寸第一张的尺寸
Size positive_image_size = faces[0].size();
cout << "正样本的尺寸是:" << positive_image_size << endl;
//遍历所有样品,检测尺寸是否相同
for (size_t i = 0; i < faces.size(); i++)
{
if (positive_image_size != faces[i].size())
{
std::cerr << "所有的样本的尺寸大小不一,请重新调整好样本大小!" << endl;
return;
}
}
//创建一个人脸识别的类
Ptr model = EigenFaceRecognizer::create();
//开始训练
model->train(faces, labels);
// recognition face
int predicted_label = model->predict(test_sample);
std::cout << "样本标签类型为:" << test_label << "预测的样本标签为:" << predicted_label << endl;
//保存训练好的模型
model->write(save_model);
std::cout << "训练完成!" << endl;
}
3.运行上面的函数,在传入的路径下生成一个xml的模型文件,我这里命名为face_model.xml文件,测试时调用这个文件。
三、测试代码
测试代码我也写两个函数,一个是从摄像头读取,然后识别当前人脸。
1、从摄像头读取图像并识别,函数的第一个函数是传入的摄像头索引号,第二个是训练好人脸模型路径文件名。
testFace()函数代码:
void testFace(int cap_index,string model_path)
{
//加载一个人脸识别器
Ptr model_test = EigenFaceRecognizer::create();
//opencv3.3要用read,要不然会出错
model_test->read(model_path);
//加载一个人脸检测分类器
CascadeClassifier faceDetector;
faceDetector.load(face_path);
//检测传入的摄像头
VideoCapture capture(cap_index);
if (!capture.isOpened())
{
std::cerr << "无法打开当前摄像头!" << endl;
return;
}
Mat frame;
namedWindow("faceRecognition", CV_WINDOW_AUTOSIZE);
vector faces;
Mat dst;
Mat test_sample;
string name;
while (capture.read(frame))
{
//镜像
flip(frame, frame, 1);
//检测人脸
faceDetector.detectMultiScale(frame, faces, 1.1, 1, 0, Size(80, 100), Size(380, 400));
for (int i = 0; i < faces.size(); i++)
{
Mat roi = frame(faces[i]);
cvtColor(roi, dst, COLOR_BGR2GRAY);
resize(dst, test_sample, Size(92, 112));
int label = 0;
label = model_test->predict(test_sample);
//输出检测到的人脸标签
cout << label << endl;
//画出人脸
rectangle(frame, faces[i], Scalar(255, 0, 0), 2, 8, 0);
switch (label)
{
case 41:
name = "matt";
break;
case 42:
name = "Ashida Mana";
break;
default:
name = "Unknown";
break;
}
putText(frame, name, faces[i].tl(), FONT_HERSHEY_PLAIN, 1.0, Scalar(0, 0, 255), 2, 8);
}
imshow("faceRecognition", frame);
char c = waitKey(10);
if (c == 27)
{
break;
}
}
}
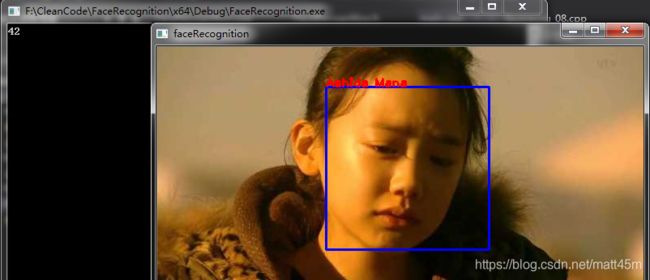
运行结果:

从摄像头拍下的人脸样本标签保存为41,但有时因为人脸的摆动,会出现误识别现象。
2、从文件夹下读取图像并识别,函数的第一个函数是传入的存放包含人脸的图像,第二个是训练好人脸模型路径文件名。
testFace()函数代码:
void testFace(string image_path, string model_path)
{
//加载一个人脸识别器
Ptr model_test = EigenFaceRecognizer::create();
//opencv3.3要用read,要不然会出错
model_test->read(model_path);
//加载一个人脸检测分类器
CascadeClassifier faceDetector;
faceDetector.load(face_path);
Mat frame;
namedWindow("faceRecognition", CV_WINDOW_AUTOSIZE);
vector faces;
Mat dst;
Mat test_sample;
string name;
if (!fs::is_directory(image_path))
{
std::cerr << "请传入一个合法的非空的路径!" << endl;
return;
}
fs::directory_iterator begin_iter(image_path);
fs::directory_iterator end_iter;
for(;begin_iter != end_iter; begin_iter ++)
{
frame = imread(begin_iter->path().string());
if (frame.empty())
{
continue;
}
//检测人脸
faceDetector.detectMultiScale(frame, faces, 1.1, 1, 0, Size(80, 100), Size(380, 400));
for (int i = 0; i < faces.size(); i++)
{
Mat roi = frame(faces[i]);
cvtColor(roi, dst, COLOR_BGR2GRAY);
resize(dst, test_sample, Size(92, 112));
int label = 0;
label = model_test->predict(test_sample);
//输出检测到的人脸标签
cout << label << endl;
//画出人脸
rectangle(frame, faces[i], Scalar(255, 0, 0), 2, 8, 0);
switch (label)
{
case 41:
name = "matt";
break;
case 42:
name = "Ashida Mana";
break;
default:
name = "Unknown";
break;
}
putText(frame, name, faces[i].tl(), FONT_HERSHEY_PLAIN, 1.0, Scalar(0, 0, 255), 2, 8);
}
imshow("faceRecognition", frame);
waitKey(0);
}
}
运行结果,识别正确的图像:
识别不到的:

结语
1.以上的所有关于人脸训练与识别的代码演示,只是一个通用的代码框架,识别的准确率并不能达到可以使用在项目上。要真正达到应用级,好多地方都要优化,如样本的提取,提取样本的摄像头的角度与识别时的使用的摄像头角度,识别时检测到人脸之后的相关矫正等等。
2.现在好多深度学习的网络可以实现出更高的准确率,比如caffe的DeepID等,之后有时间会去写相关的训练与应用。
3.关于整个工程的源码,运行程序时的bug,或者有如何优化的想法都可以加这个群(487350510)互相讨论学习。