python的requests
它是python的一个第三方库,处理URL比urllib这个库要方便的多,并且功能也很丰富。
【可以先看4,5表格形式的说明,再看前面的】
安装
直接用pip安装,anconda是自带这个库的。
pip install requests
简单使用
requests的文档
1.简单访问一个url:
import requests url='http://www.baidu.com' res = requests.get(url) res.text res.status_code
百度ä¸�ä¸‹ï¼Œä½ å°±çŸ¥é“ 200©2017 Baidu 使用百度å‰å¿ 读 æ„è§å馈 京ICPè¯030173å·


乱码的,是由于没有转换字符,可以加入res.encoding='utf-8'解决,200是状态码。一般状态码是2xx都没什么问题的。
1xx:web服务器正确接收到请求了
2xx:处理成功,比如200表示正常,请求完成;204表示正常无响应等
3xx:重定向
4xx:客户端出现错误,比如著名的404找不到
5xx:服务器出现错误 ,比如500的内部错误
res.encoding='utf-8' print(res.text)
主要的点
(1).用get请求得到的数据是一个response对象,用response.text属性来查看。
(2).修改编码形式用response.encoding='utf-8/gbk/...',encoding是它的一个属性可以查看response.encoding
res.encoding >>>: >'utf-8'
(3).无论响应是文本还是二进制内容,我们都可以用content属性获得bytes对象:
import requests
url='http://www.baidu.com'
res = requests.get(url)
print(res.content)
print("----------")
print(res.text)
print("----------")
print(type(res))
\r\n\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80\xe4\xb8\x8b\xef\xbc\x8c\xe4\xbd\xa0\xe5\xb0\xb1\xe7\x9f\xa5\xe9\x81\x93 \r\n' ----------\xe5\x85\xb3\xe4\xba\x8e\xe7\x99\xbe\xe5\xba\xa6 About Baidu
©2017 Baidu \xe4\xbd\xbf\xe7\x94\xa8\xe7\x99\xbe\xe5\xba\xa6\xe5\x89\x8d\xe5\xbf\x85\xe8\xaf\xbb \xe6\x84\x8f\xe8\xa7\x81\xe5\x8f\x8d\xe9\xa6\x88 \xe4\xba\xacICP\xe8\xaf\x81030173\xe5\x8f\xb7
百度ä¸�ä¸‹ï¼Œä½ å°±çŸ¥é“ < /head>©2017 Baidu 使用百度å‰å¿è¯» æ„è§å馈 京ICPè¯030173å·
(4).status_code属性来查看该请求返回的状态码
2.带参数访问url
(1).带http 的头去访问可以传入参数:headers={'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit'} ,不至于很快就被判断惩恶爬虫,把你的IP给封了。
(2).Cookie
# 获得指定cookie
r.cookies['cookie_name']
# 传入cookie 用dict来传递
cs = {'token':'密码','status':'状态'}
res = requests.get(url, cookies='cs')
3).指定超时
res = requests.get(url, timeout=3) #3秒后超时
注意:一般用get方法就可以爬取一些比较简单容易的网站。
4.requests的一些常用方法和主要参数
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,用于以下各种方法的处理 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML提交局部修改请求的方法,对应于HTTP的PATCH |
| requests.delete() | 向HTML提交删除请求的方法,对应于HTTP的DELETE |
requests.get()方法的参数:
格式:requests.get(url, params=None, **kwargs) 最前面介绍的几个常用的掌握就够用了。
#url:要访问的url地址 # params:url中的额外参数,可选的,字典或者字典或字节形式传递 # **kwargs:控制访问的参数,可选 ## headers,timeout,cookies,data,json,proxies,allow_redirects,stream,veriftty,cert,files,auth
5.requests.Response对象的属性说明
| 属性 | 说明 |
|---|---|
| res.status_code | HTTP请求返回的状态码,200表示连接成功,404表示失败 |
| res.text | HTTP响应内容的字符串形式,即url对应的页面内容 |
| res.encoding | 从HTTP header中猜测的响应内容的编码形式,乱码可以修改防止乱码 |
| res.content | 从内容中分析出的响应内容的编码方式,备用 |
| res.apparent_encoding | HTTP响应内容的二进制形式 |
xpath简介
述
Xpath是一门在xml文档中查找信息的语言。Xpath可用来在xml文档中对元素和属性进行遍历。由于html的层次结构与xml的层次结构天然一致,所以使用Xpath也能够进行html元素的定位。
定位方法 1.绝对路径定位:
顾名思义,将Xpath表达式从html的最外层节点,逐层填写,最后定位到操作元素,一般浏览器插件出来都是绝对定位
类似:/html/body/div[1]/div[2]/div[5]/div[1]/div[1]/form/span[2]/input
2.相对路径定位
通过相对路径定位元素,提取的是元素的部分特征,只要提取恰当,能够保证版本间稳定,是进行自动化测试的首选。
类似://div[@class='e']/a/p/span/text() @后面是属性,最后的text()提取标签之间的文本数据
3.索引号定位
类似:/html/body/div[1]/div[2]/div[5]/div[1]/div[1]/form/span[last()-1]/input 表示form下倒数第二个span
4.属性定位
类似://*[@id=“kw” and @name=‘wd'] 表示 id 属性为 kw 且 name 属性为 wd
5.其它定位方法
还要别的定位方法,不常用,不介绍
lxml简介
导入lxml 的 etree 库
from lxml import etree
简单使用
(1).利用etree.HTML,将html字符串(bytes类型或str类型)转化为Element对象,Element对象具有xpath的方法,返回结果列表。
html = etree.HTML(text)
ret_list = html.xpath("xpath语法规则字符串")
(2).xpath方法返回列表的三种情况
返回空列表:根据xpath语法规则字符串,没有定位到任何元素
返回由字符串构成的列表:xpath字符串规则匹配的一定是文本内容或某属性的值
返回由Element对象构成的列表:xpath规则字符串匹配的是标签,列表中的Element对象可以继续进行xpath
注意:
(1).lxml.etree.HTML(html_str)可以自动补全标签
(2).lxml.etree.tostring函数可以将转换为Element对象再转换回html字符串
(3).爬虫如果使用lxml来提取数据,应该以lxml.etree.tostring的返回结果作为提取数据的依据
实例:爬取51.job的大数据职业信息的第一页【requests+xpath】
分析:打开首页,搜索大数据,定位是兰州,F12调式查看,爬取工作名称和公司名就好了


位置
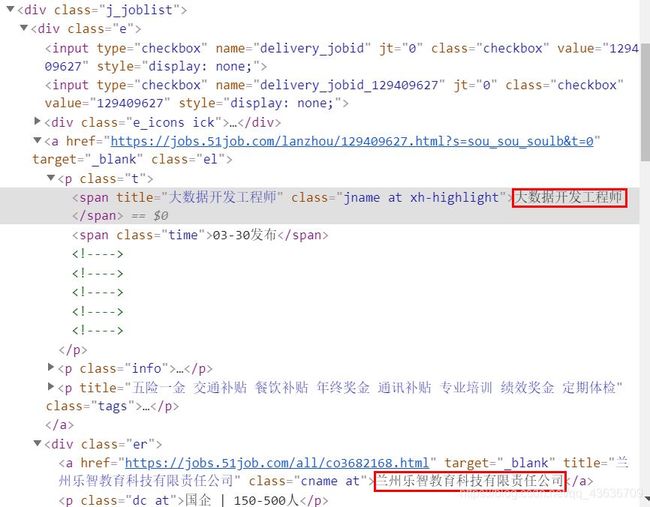


import requests
from lxml import etree
url = "https://search.51job.com/list/270200,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare="
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
res = requests.get(url,headers=header)
res.encoding = "gbk"
#print(res.text)
data = etree.HTML(res.text)#加载成html树
job_name = data.xpath("//div[@class='e']/a/p/span/text()")
cname = data.xpath("/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div/div[2]/a/@title")
到此这篇关于python中requests库+xpath+lxml简单使用的文章就介绍到这了,更多相关requests库+xpath+lxml使用内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!