扩展阅读:
数据预处理
特征二值化
对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式表达如下:
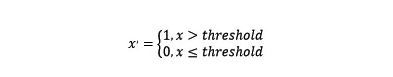
使用preproccessing库的Binarizer类对数据进行二值化的代码如下:
from sklearn.preprocessing importBinarizer
X = [[ 1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]]
binarizer = Binarizer().fit(X)
print(binarizer.transform(X))
output
[[ 1. 0. 1.]
[ 1. 0. 0.]
[ 0. 1. 0.]]
分类特征编码
特征更多的时候是分类特征,而不是连续的数值特征。
比如一个人的特征可以是[“male”, “female”],["from Europe", "from US", "from Asia"], ["uses Firefox", "uses Chrome","uses Safari", "uses Internet Explorer"]。
这样的特征可以高效的编码成整数,例如["male","from US", "uses Internet Explorer"]可以表示成[0, 1, 3],["female", "from Asia","uses Chrome"]就是[1, 2, 1]。
这个的整数特征表示并不能在scikit-learn的估计器中直接使用,因为这样的连续输入,估计器会认为类别之间是有序的,但实际却是无序的。(例如:浏览器的类别数据则是任意排序的)。一个将分类特征转换成scikit-learn估计器可用特征的可选方法是使用one-of-K或者one-hot编码,OneHotEncoder是该方法的一个实现。该方法将每个类别特征的m 可能值转换成m个二进制特征值,当然只有一个是激活值。例如:
from sklearn.preprocessing importOneHotEncoder
print(OneHotEncoder().fit_transform([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]).toarray())
output
[[ 1. 0. 1. 0. 0. 0. 0. 0. 1.]
[ 0. 1. 0. 1. 0. 1. 0. 0. 0.]
[ 1. 0. 0. 0. 1. 0. 1. 0. 0.]
[ 0. 1. 1. 0. 0. 0. 0. 1. 0.]]
缺失值处理
因为各种各样的原因,真实世界中的许多数据集都包含缺失数据,这类数据经常被编码成空格、NaNs,或者是其他的占位符。但是这样的数据集并不能scikit-learn学习算法兼容,因为大多的学习算法都默认假设数组中的元素都是数值,因而所有的元素都有自己的意义。使用不完整的数据集的一个基本策略就是舍弃掉整行或整列包含缺失值的数据。但是这样就付出了舍弃可能有价值数据(即使是不完整的 )的代价。 处理缺失数值的一个更好的策略就是从已有的数据推断出缺失的数值。
Imputer
类提供了缺失数值处理的基本策略,比如使用缺失数值所在行或列的均值、中位数、众数来替代缺失值。该类也兼容不同的缺失值编码。接下来是一个如何替换缺失值的简单示例,缺失值被编码为np.nan, 使用包含缺失值的列的均值来替换缺失值。
import numpy asnp
from sklearn.preprocessing importImputer
imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
imp.fit([[1, 2], [np.nan, 3], [7, 6]])
#Imputer(axis=0, copy=True, missing_values='NaN', strategy='mean', verbose=0)
X = [[np.nan, 2], [6, np.nan], [7, 6]]
print(imp.transform(X))
output
[[ 4. 2. ]
[ 6. 3.66666667]
[ 7. 6. ]]
数据变换
很多情况下,考虑输入数据中的非线性特征来增加模型的复杂性是非常有效的。常见的数据变换有基于多项式的、基于指数函数的、基于对数函数的。使用preproccessing库的PolynomialFeatures类对数据进行多项式转换的代码如下:
import numpy asnp
from sklearn.preprocessing importPolynomialFeatures
X = np.arange(6).reshape(3, 2)
PolynomialFeatures(2).fit_transform(X)
output
array([[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.]])
基本的数据预处理就包含以上的方法。
文中涉及源码在这里:源码
参考
sklearn preprocess
特征工程到底是什么?
作者:jacksu在链接:https://www.jianshu.com/p/c2e450c07de7
來源:著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。