消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性[架构],至于为什么使用和如何选择消息中间件的问题可以跳转这里 http://url.cn/5akWQiJ
使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ
这里我们介绍kafka
一.基本概念
介绍
kafka是一个分布式的,可分区的,可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。
首先Kafka将消息以topic为单位进行归纳。 发布消息的程序称为producers。预定消息的程序称为consumer。可以理解为生产者和消费者。kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker,producers通过网络将消息发送到kafka cluster。kafka cluster向消费者提供消息。如下图所示

客户端和服务端通过TCP协议通讯。kafka提供了java客户端,并且对多种语言都提供了支持。
Topic和logs
这里介绍一下kafka提供的一个抽象概念:topic。一个topic是对一组消息的归纳。对于每个topic,kafka对它的日志进行了分区,如下图所示:
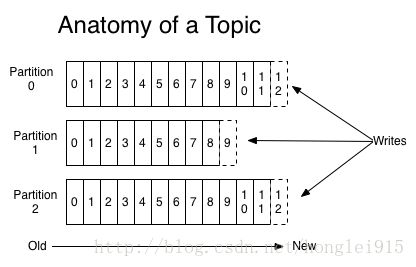
每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息。
在一个可配置的时间段内,Kafka集群保留所有发布的消息,不管这些消息有没有被消费。比如,如果消息的保存策略被设置为2天,那么在一个消息被发布的两天时间内,它都是可以被消费的。之后它将被丢弃以释放空间。Kafka的性能是和数据量无关的常量级的,所以保留太多的数据并不是问题。(kafka可以在o(1)的复杂度下进行数据持久化)
实际上每个consumer唯一需要维护的数据是消息在日志中的位置,也就是offset.这个offset有consumer来维护:一般情况下随着consumer不断的读取消息,这offset的值不断增加,但其实consumer可以以任意的顺序读取消息,比如它可以将offset设置成为一个旧的值来重读之前的消息。
以上特点的结合,使Kafka consumers非常的轻量级:它们可以在不对集群和其他consumer造成影响的情况下读取消息。你可以使用命令行来"tail"消息而不会对其他正在消费消息的consumer造成影响。
将日志分区可以达到以下目的:首先这使得每个日志的数量不会太大,可以在单个服务上保存。另外每个分区可以单独发布和消费,为并发操作topic提供了一种可能。
分布式
每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的。副本使Kafka具备了容错能力。每个分区都由一个服务器作为“leader”,零或若干服务器作为“followers”,leader负责处理消息的读和写,followers则去复制leader.如果leader down了,followers中的一台则会自动成为leader。集群中的每个服务都会同时扮演两个角色:作为它所持有的一部分分区的leader,同时作为其他分区的followers,这样集群就会据有较好的负载均衡。
Producers
Producer将消息发布到它指定的topic中,并负责决定发布到哪个分区。通常简单的由负载均衡机制随机选择分区,但也可以通过特定的分区函数选择分区。使用的更多的是第二种。
Consumers
发布消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。队列模式中,consumers可以同时从服务端读取消息,每个消息只被其中一个consumer读到;发布-订阅模式中消息被广播到所有的consumer中。Consumers可以加入一个consumer 组,共同竞争一个topic,topic中的消息将被分发到组中的一个成员中。同一组中的consumer可以在不同的程序中,也可以在不同的机器上。如果所有的consumer都在一个组中,这就成为了传统的队列模式,在各consumer中实现负载均衡。如果所有的consumer都不在不同的组中,这就成为了发布-订阅模式,所有的消息都被分发到所有的consumer中。更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个consumer。如下图示例:

由两个机器组成的集群拥有4个分区 (P0-P3) 2个consumer组. A组有两个consumer,B组有4个
相比传统的消息系统,Kafka可以很好的保证有序性。
传统的队列在服务器上保存有序的消息,如果多个consumers同时从这个服务器消费消息,服务器就会以消息存储的顺序向consumer分发消息。虽然服务器按顺序发布消息,但是消息是被异步的分发到各consumer上,所以当消息到达时可能已经失去了原来的顺序,这意味着并发消费将导致顺序错乱。为了避免故障,这样的消息系统通常使用“专用consumer”的概念,其实就是只允许一个消费者消费消息,当然这就意味着失去了并发性。
在这方面Kafka做的更好,通过分区的概念,Kafka可以在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每个分区分只分发给一个consumer组,这样一个分区就只被这个组的一个consumer消费,就可以顺序的消费这个分区的消息。因为有多个分区,依然可以在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量,也就是有多少分区就允许多少并发消费。
Kafka只能保证一个分区之内消息的有序性,在不同的分区之间是不可以的,这已经可以满足大部分应用的需求。如果需要topic中所有消息的有序性,那就只能让这个topic只有一个分区,当然也就只有一个consumer组消费它。
二.环境搭建
step1:下载kafka和zookeeper
分别解压到/usr/local目录下
进入zookeeper下的conf目录,将zoo_sample.cfg文件拷贝,并更名为zoo.cfg
添加环境变量
在/etc/profile中添加环境变量,
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${ZOOKEEPER_HOME}/bin:$PATH
step2:启动服务
首先尝试启动zookeeper
/usr/local/zookeeper-3.4.12/bin/zkServer.sh start //启动zookeeper
/usr/local/zookeeper-3.4.12/bin/zkCli.sh -server localhost:2181 //启动客户端脚本
/usr/local/zookeeper-3.4.12/bin/zkServer.sh status //查看状态
/usr/local/zookeeper-3.4.12/bin/zkServer.sh stop //停止zookeeper
接下来启动kafka
kafka需要使用Zookeeper,首先需要启动Zookeeper服务,上面的操作就已经启动了Zookeeper服务
bin/kafka-server-start.sh config/server.properties //启动kafka服务
bin/kafka-server-stop.sh config/server.properties //停止 Kafka服务
step3:创建topic
现在创建一个叫做"test"的topic,它只有一个分区,一个副本。
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
可以通过list命令查看创建的topic:
> bin/kafka-topics.sh --list --zookeeper localhost:2181
test
当然,除了手动创建topic,还可以配置broker让它自动创建topic.
step4:发送消息
Kafka 使用一个简单的命令行producer,从文件中或者从标准输入中读取消息并发送到服务端。默认的每条命令将发送一条消息。
运行producer并在控制台中输一些消息,这些消息将被发送到服务端:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test //ctrl+c可以退出发送。
HelloWorld, Another HelloWorld
step5: 启动consumer
Kafka也有一个命令行consumer可以读取消息并输出到标准输出:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
HelloWorld, Another HelloWorld
在一个终端中运行consumer命令行,另一个终端中运行producer命令行,就可以在一个终端输入消息,另一个终端读取消息。
这两个命令都有自己的可选参数,可以在运行的时候不加任何参数可以看到帮助信息。
step 6: 搭建一个多个broker的集群
刚才只是启动了单个broker,现在启动有3个broker组成的集群,这些broker节点也都是在本机上的:
首先为每个节点编写配置文件:
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties
在拷贝出的新文件中修改以下参数:
config/server-1.properties:
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1
config/server-2.properties:
broker.id=2
port=9094
log.dir=/tmp/kafka-logs-2
broker.id在集群中唯一的标注一个节点,因为在同一个机器上,所以必须制定不同的端口和日志文件,避免数据被覆盖。
刚才已经启动可Zookeeper和一个节点,现在启动另外两个节点:
bin/kafka-server-start.sh config/server-1.properties &
bin/kafka-server-start.sh config/server-2.properties &
创建一个拥有3个副本的topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
现在我们搭建了一个集群,怎么知道每个节点的信息呢?运行“"describe topics”命令就可以了:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
三.使用
1.引入依赖
org.springframework.kafka
spring-kafka
1.1.1.RELEASE
配置程序
首先是一个充当配置文件作用的接口,配置了Kafka的各种连接参数:
public interface KafkaProperties
{
final static String zkConnect = "10.22.10.139:2181";
final static String groupId = "group1";
final static String topic = "topic1";
final static String kafkaServerURL = "10.22.10.139";
final static int kafkaServerPort = 9092;
final static int kafkaProducerBufferSize = 64 * 1024;
final static int connectionTimeOut = 20000;
final static int reconnectInterval = 10000;
final static String topic2 = "topic2";
final static String topic3 = "topic3";
final static String clientId = "SimpleConsumerDemoClient";
}
producer
public class KafkaProducer extends Thread
{
private final kafka.javaapi.producer.Producer producer;
private final String topic;
private final Properties props = new Properties();
public KafkaProducer(String topic)
{
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "10.22.10.139:9092");
producer = new kafka.javaapi.producer.Producer(new ProducerConfig(props));
this.topic = topic;
}
@Override
public void run() {
int messageNo = 1;
while (true)
{
String messageStr = new String("Message_" + messageNo);
System.out.println("Send:" + messageStr);
producer.send(new KeyedMessage(topic, messageStr));
messageNo++;
try {
sleep(3000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
consumer
public class KafkaConsumer extends Thread
{
private final ConsumerConnector consumer;
private final String topic;
public KafkaConsumer(String topic)
{
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
createConsumerConfig());
this.topic = topic;
}
private static ConsumerConfig createConsumerConfig()
{
Properties props = new Properties();
props.put("zookeeper.connect", KafkaProperties.zkConnect);
props.put("group.id", KafkaProperties.groupId);
props.put("zookeeper.session.timeout.ms", "40000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
@Override
public void run() {
Map topicCountMap = new HashMap();
topicCountMap.put(topic, new Integer(1));
Map>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream stream = consumerMap.get(topic).get(0);
ConsumerIterator it = stream.iterator();
while (it.hasNext()) {
System.out.println("receive:" + new String(it.next().message()));
try {
sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
简单的发送接收
public class KafkaConsumerProducerDemo
{
public static void main(String[] args)
{
KafkaProducer producerThread = new KafkaProducer(KafkaProperties.topic);
producerThread.start();
KafkaConsumer consumerThread = new KafkaConsumer(KafkaProperties.topic);
consumerThread.start();
}
}
原文地址: http://www.360doc.com/content/17/0723/21/11253639_673606100.shtml