1.1 项目来源
本次实践的目的就在于通过对该技术论坛网站的tomcat access log日志进行分析,计算该论坛的一些关键指标,供运营者进行决策时参考。
PS:开发该系统的目的是为了获取一些业务相关的指标,这些指标在第三方工具中无法获得的;
1.2 数据情况
该论坛数据有两部分:
(1)历史数据约56GB,统计到2012-05-29。这也说明,在2012-05-29之前,日志文件都在一个文件里边,采用了追加写入的方式。
(2)自2013-05-30起,每天生成一个数据文件,约150MB左右。这也说明,从2013-05-30之后,日志文件不再是在一个文件里边。
图2展示了该日志数据的记录格式,其中每行记录有5部分组成:访问者IP、访问时间、访问资源、访问状态(HTTP状态码)、本次访问流量。

图2 日志记录数据格式
二、关键指标KPI
2.1 浏览量PV
(1)定义:页面浏览量即为PV(Page View),是指所有用户浏览页面的总和,一个独立用户每打开一个页面就被记录1 次。
(2)分析:网站总浏览量,可以考核用户对于网站的兴趣,就像收视率对于电视剧一样。
计算公式:记录计数,从日志中获取访问次数。
2.2 注册用户数
该论坛的用户注册页面为member.php,而当用户点击注册时请求的又是member.php?mod=register的url。
计算公式:对访问member.php?mod=register的url,计数。
2.3 IP数
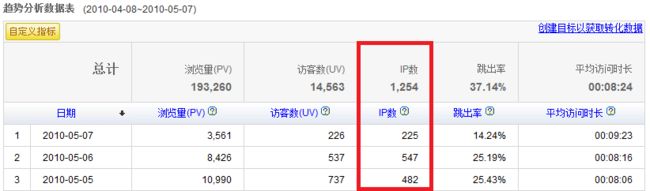
(1)定义:一天之内,访问网站的不同独立 IP 个数加和。其中同一IP无论访问了几个页面,独立IP 数均为1。
(2)分析:这是我们最熟悉的一个概念,无论同一个IP上有多少电脑,或者其他用户,从某种程度上来说,独立IP的多少,是衡量网站推广活动好坏最直接的数据。
计算公式:对不同的访问者ip,计数
2.4 跳出率
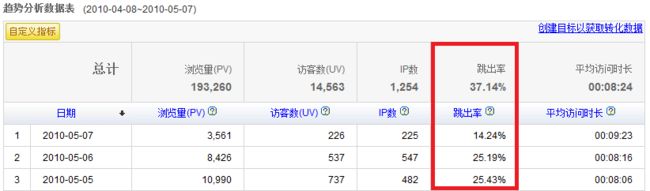
(1)定义:只浏览了一个页面便离开了网站的访问次数占总的访问次数的百分比,即只浏览了一个页面的访问次数 / 全部的访问次数汇总。
(2)分析:跳出率是非常重要的访客黏性指标,它显示了访客对网站的兴趣程度:跳出率越低说明流量质量越好,访客对网站的内容越感兴趣,这些访客越可能是网站的有效用户、忠实用户。
PS:该指标也可以衡量网络营销的效果,指出有多少访客被网络营销吸引到宣传产品页或网站上之后,又流失掉了,可以说就是煮熟的鸭子飞了。比如,网站在某媒体上打广告推广,分析从这个推广来源进入的访客指标,其跳出率可以反映出选择这个媒体是否合适,广告语的撰写是否优秀,以及网站入口页的设计是否用户体验良好。
计算公式:①统计一天内只出现一条记录的ip,称为跳出数;②跳出数/PV;
处理步骤
1 数据清洗
使用MapReduce对HDFS中的原始数据进行清洗,以便后续进行统计分析;
2 统计分析
使用Hive对清洗后的数据进行统计分析;
数据清洗
一、数据情况分析
1.1 数据情况回顾
该论坛数据有两部分:
(1)历史数据约56GB,统计到2012-05-29。这也说明,在2012-05-29之前,日志文件都在一个文件里边,采用了追加写入的方式。
(2)自2013-05-30起,每天生成一个数据文件,约150MB左右。这也说明,从2013-05-30之后,日志文件不再是在一个文件里边。
图1展示了该日志数据的记录格式,其中每行记录有5部分组成:访问者IP、访问时间、访问资源、访问状态(HTTP状态码)、本次访问流量。

图1 日志记录数据格式
本次使用数据来自于两个2013年的日志文件,分别为access_2013_05_30.log与access_2013_05_31.log,下载地址为:http://pan.baidu.com/s/1pJE7XR9
1.2 要清理的数据
(1)根据前一篇的关键指标的分析,我们所要统计分析的均不涉及到访问状态(HTTP状态码)以及本次访问的流量,于是我们首先可以将这两项记录清理掉;
(2)根据日志记录的数据格式,我们需要将日期格式转换为平常所见的普通格式如20150426这种,于是我们可以写一个类将日志记录的日期进行转换;
(3)由于静态资源的访问请求对我们的数据分析没有意义,于是我们可以将"GET /staticsource/"开头的访问记录过滤掉,又因为GET和POST字符串对我们也没有意义,因此也可以将其省略掉;
二、数据清洗过程
2.1 定期上传日志至HDFS
首先,把日志数据上传到HDFS中进行处理,可以分为以下几种情况:
(1)如果是日志服务器数据较小、压力较小,可以直接使用shell命令把数据上传到HDFS中;
(2)如果日志服务器非常多、数据量大,使用flume进行数据处理;
这里我们的实验数据文件较小,因此直接采用第一种Shell命令方式。
清洗之前
27.19.74.143 - - [30/May/2013:17:38:20 +0800] "GET /static/image/common/faq.gif HTTP/1.1" 200 1127
110.52.250.126 - - [30/May/2013:17:38:20 +0800] "GET /data/cache/style_1_widthauto.css?y7a HTTP/1.1" 200 1292
27.19.74.143 - - [30/May/2013:17:38:20 +0800] "GET /static/image/common/hot_1.gif HTTP/1.1" 200 680
27.19.74.143 - - [30/May/2013:17:38:20 +0800] "GET /static/image/common/hot_2.gif HTTP/1.1" 200 682
清洗之后
110.52.250.126 20130530173820 data/cache/style_1_widthauto.css?y7a
110.52.250.126 20130530173820 source/plugin/wsh_wx/img/wsh_zk.css
110.52.250.126 20130530173820 data/cache/style_1_forum_index.css?y7a
110.52.250.126 20130530173820 source/plugin/wsh_wx/img/wx_jqr.gif
27.19.74.143 20130530173820 data/attachment/common/c8/common_2_verify_icon.png
27.19.74.143 20130530173820 data/cache/common_smilies_var.js?y7a
2.2 编写MapReduce程序清理日志
package com.neuedu;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogCleanJob {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
if (args.length != 2) {
System.err.println("Usage:Merge and duplicate removal ");
System.exit(2);
}
Job job = Job.getInstance(conf, "LogCleanJob");
job.setJarByClass(LogCleanJob.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
static class MyMapper extends
Mapper {
LogParser logParser = new LogParser();
Text outputValue = new Text();
protected void map(
LongWritable key,
Text value,
Context context)
throws java.io.IOException, InterruptedException {
final String[] parsed = logParser.parse(value.toString());
// step1.过滤掉静态资源访问请求
if (parsed[2].startsWith("GET /static/")
|| parsed[2].startsWith("GET /uc_server")) {
return;
}
// step2.过滤掉开头的指定字符串
if (parsed[2].startsWith("GET /")) {
parsed[2] = parsed[2].substring("GET /".length());
} else if (parsed[2].startsWith("POST /")) {
parsed[2] = parsed[2].substring("POST /".length());
}
// step3.过滤掉结尾的特定字符串
if (parsed[2].endsWith(" HTTP/1.1")) {
parsed[2] = parsed[2].substring(0, parsed[2].length()
- " HTTP/1.1".length());
}
// step4.只写入前三个记录类型项
outputValue.set(parsed[0] + "\t" + parsed[1] + "\t" + parsed[2]);
context.write(key, outputValue);
}
}
static class MyReducer extends
Reducer {
protected void reduce(
LongWritable k2,
Iterable values,
Context context)
throws java.io.IOException, InterruptedException {
context.write(values.iterator().next(), NullWritable.get());
}
}
/*
* 日志解析类
*/
static class LogParser {
public static final SimpleDateFormat FORMAT = new SimpleDateFormat(
"d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH);
public static final SimpleDateFormat dateformat1 = new SimpleDateFormat(
"yyyyMMddHHmmss");
public static void main(String[] args) throws ParseException {
final String S1 = "27.19.74.143 - - [30/May/2013:17:38:20 +0800] \"GET /static/image/common/faq.gif HTTP/1.1\" 200 1127";
LogParser parser = new LogParser();
final String[] array = parser.parse(S1);
System.out.println("样例数据: " + S1);
System.out.format(
"解析结果: ip=%s, time=%s, url=%s, status=%s, traffic=%s",
array[0], array[1], array[2], array[3], array[4]);
}
/**
* 解析英文时间字符串
*
* @param string
* @return
* @throws ParseException
*/
private Date parseDateFormat(String string) {
Date parse = null;
try {
parse = FORMAT.parse(string);
} catch (ParseException e) {
e.printStackTrace();
}
return parse;
}
/**
* 解析日志的行记录
*
* @param line
* @return 数组含有5个元素,分别是ip、时间、url、状态、流量
*/
public String[] parse(String line) {
String ip = parseIP(line);
String time = parseTime(line);
String url = parseURL(line);
String status = parseStatus(line);
String traffic = parseTraffic(line);
return new String[] { ip, time, url, status, traffic };
}
private String parseTraffic(String line) {
final String trim = line.substring(line.lastIndexOf("\"") + 1)
.trim();
String traffic = trim.split(" ")[1];
return traffic;
}
private String parseStatus(String line) {
final String trim = line.substring(line.lastIndexOf("\"") + 1)
.trim();
String status = trim.split(" ")[0];
return status;
}
private String parseURL(String line) {
final int first = line.indexOf("\"");
final int last = line.lastIndexOf("\"");
String url = line.substring(first + 1, last);
return url;
}
private String parseTime(String line) {
final int first = line.indexOf("[");
final int last = line.indexOf("+0800]");
String time = line.substring(first + 1, last).trim();
Date date = parseDateFormat(time);
return dateformat1.format(date);
}
private String parseIP(String line) {
String ip = line.split("- -")[0].trim();
return ip;
}
}
}
一、借助Hive进行统计
1.1 准备工作:建立分区表

为了能够借助Hive进行统计分析,首先我们需要将清洗后的数据存入Hive中,那么我们需要先建立一张表。这里我们选择分区表,以日期作为分区的指标,建表语句如下:(这里关键之处就在于确定映射的HDFS位置,我这里是/project/techbbs/cleaned即清洗后的数据存放的位置)
hive> dfs -mkdir -p /project/techbbs/cleaned
hive>CREATE EXTERNAL TABLE techbbs(ip string, atime string, url string) PARTITIONED BY (logdate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/project/techbbs/cleaned';
建立了分区表之后,就需要增加一个分区,增加分区的语句如下:(这里主要针对20150425这一天的日志进行分区)
hive>ALTER TABLE techbbs ADD PARTITION(logdate='2015_04_25') LOCATION '/project/techbbs/cleaned/2015_04_25';
hive> load data local inpath '/root/cleaned' into table techbbs3 partition(logdate='2015_04_25');
1.2 使用HQL统计关键指标
(1)关键指标之一:PV量
页面浏览量即为PV(Page View),是指所有用户浏览页面的总和,一个独立用户每打开一个页面就被记录1 次。这里,我们只需要统计日志中的记录个数即可,HQL代码如下:
hive>CREATE TABLE techbbs_pv_2015_04_25 AS SELECT COUNT(1) AS PV FROM techbbs WHERE logdate='2015_04_25';

(2)关键指标之二:注册用户数
该论坛的用户注册页面为member.php,而当用户点击注册时请求的又是member.php?mod=register的url。因此,这里我们只需要统计出日志中访问的URL是member.php?mod=register的即可,HQL代码如下:
hive>CREATE TABLE techbbs_reguser_2015_04_25 AS SELECT COUNT(1) AS REGUSER FROM techbbs WHERE logdate='2015_04_25' AND INSTR(url,'member.php?mod=register')>0;

(3)关键指标之三:独立IP数
一天之内,访问网站的不同独立 IP 个数加和。其中同一IP无论访问了几个页面,独立IP 数均为1。因此,这里我们只需要统计日志中处理的独立IP数即可,在SQL中我们可以通过DISTINCT关键字,在HQL中也是通过这个关键字:
hive>CREATE TABLE techbbs_ip_2015_04_25 AS SELECT COUNT(DISTINCT ip) AS IP FROM techbbs WHERE logdate='2015_04_25';

(4)关键指标之四:跳出用户数
只浏览了一个页面便离开了网站的访问次数,即只浏览了一个页面便不再访问的访问次数。这里,我们可以通过用户的IP进行分组,如果分组后的记录数只有一条,那么即为跳出用户。将这些用户的数量相加,就得出了跳出用户数,HQL代码如下:
hive>CREATE TABLE techbbs_jumper_2015_04_25 AS SELECT COUNT(1) AS jumper FROM (SELECT COUNT(ip) AS times FROM techbbs WHERE logdate='2015_04_25' GROUP BY ip HAVING times=1) e;

PS:跳出率是指只浏览了一个页面便离开了网站的访问次数占总的访问次数的百分比,即只浏览了一个页面的访问次数 / 全部的访问次数汇总。这里,我们可以将这里得出的跳出用户数/PV数即可得到跳出率。