步骤
- 分词、去停用词
- 词袋模型向量化文本
- TF-IDF模型向量化文本
- LSI模型向量化文本
- 计算相似度
理论知识
两篇中文文本,如何计算相似度?相似度是数学上的概念,自然语言肯定无法完成,所有要把文本转化为向量。两个向量计算相似度就很简单了,欧式距离、余弦相似度等等各种方法,只需要中学水平的数学知识。
那么如何将文本表示成向量呢?
词袋模型
最简单的表示方法是词袋模型。把一篇文本想象成一个个词构成的,所有词放入一个袋子里,没有先后顺序、没有语义。
例如:
John likes to watch movies. Mary likes too.
John also likes to watch football games.
这两个句子,可以构建出一个词典,key为上文出现过的词,value为这个词的索引序号
{"John": 1, "likes": 2,"to": 3, "watch": 4, "movies": 5,"also": 6, "football": 7, "games": 8,"Mary": 9, "too": 10}
那么,上面两个句子用词袋模型表示成向量就是:
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
[1, 1,1, 1, 0, 1, 1, 1, 0, 0]
相对于英文,中文更复杂一些,涉及到分词。准确地分词是所有中文文本分析的基础,本文使用结巴分词,完全开源而且分词准确率相对有保障。-
TF-IDF模型
词袋模型简单易懂,但是存在问题。中文文本里最常见的词是“的”、“是”、“有”这样的没有实际含义的词。一篇关于足球的中文文本,“的”出现的数量肯定多于“足球”。所以,要对文本中出现的词赋予权重。
一个词的权重由TF * IDF 表示,其中TF表示词频,即一个词在这篇文本中出现的频率;IDF表示逆文档频率,即一个词在所有文本中出现的频率倒数。因此,一个词在某文本中出现的越多,在其他文本中出现的越少,则这个词能很好地反映这篇文本的内容,权重就越大。
回过头看词袋模型,只考虑了文本的词频,而TF-IDF模型则包含了词的权重,更加准确。文本向量与词袋模型中的维数相同,只是每个词的对应分量值换成了该词的TF-IDF值。 TF
TF
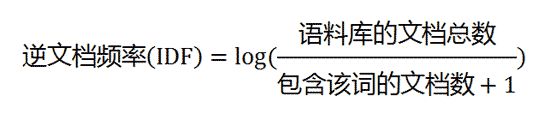
- LSI模型
TF-IDF模型足够胜任普通的文本分析任务,用TF-IDF模型计算文本相似度已经比较靠谱了,但是细究的话还存在不足之处。实际的中文文本,用TF-IDF表示的向量维数可能是几百、几千,不易分析计算。此外,一些文本的主题或者说中心思想,并不能很好地通过文本中的词来表示,能真正概括这篇文本内容的词可能没有直接出现在文本中。
因此,这里引入了Latent Semantic Indexing(LSI)从文本潜在的主题来进行分析。LSI是概率主题模型的一种,另一种常见的是LDA,核心思想是:每篇文本中有多个概率分布不同的主题;每个主题中都包含所有已知词,但是这些词在不同主题中的概率分布不同。LSI通过奇异值分解的方法计算出文本中各个主题的概率分布,严格的数学证明需要看相关论文。假设有5个主题,那么通过LSI模型,文本向量就可以降到5维,每个分量表示对应主题的权重。
python实现
分词上使用了结巴分词,词袋模型、TF-IDF模型、LSI模型的实现使用了gensim库。
import jieba.posseg as pseg
import codecs
from gensim import corpora, models, similarities
构建停用词表
stop_words = '/Users/yiiyuanliu/Desktop/nlp/demo/stop_words.txt'
stopwords = codecs.open(stop_words,'r',encoding='utf8').readlines()
stopwords = [ w.strip() for w in stopwords ]
结巴分词后的停用词性 [标点符号、连词、助词、副词、介词、时语素、‘的’、数词、方位词、代词]
stop_flag = ['x', 'c', 'u','d', 'p', 't', 'uj', 'm', 'f', 'r']
对一篇文章分词、去停用词
def tokenization(filename):
result = []
with open(filename, 'r') as f:
text = f.read()
words = pseg.cut(text)
for word, flag in words:
if flag not in stop_flag and word not in stopwords:
result.append(word)
return result
选取三篇文章,前两篇是高血压主题的,第三篇是iOS主题的。
filenames = ['/Users/yiiyuanliu/Desktop/nlp/demo/articles/13 件小事帮您稳血压.txt',
'/Users/yiiyuanliu/Desktop/nlp/demo/articles/高血压患者宜喝低脂奶.txt',
'/Users/yiiyuanliu/Desktop/nlp/demo/articles/ios.txt'
]
corpus = []
for each in filenames:
corpus.append(tokenization(each))
print len(corpus)
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/1q/5404x10d3k76q2wqys68pzkh0000gn/T/jieba.cache
Loading model cost 0.349 seconds.
Prefix dict has been built succesfully.
3
建立词袋模型
dictionary = corpora.Dictionary(corpus)
print dictionary
Dictionary(431 unique tokens: [u'\u627e\u51fa', u'\u804c\u4f4d', u'\u6253\u9f3e', u'\u4eba\u7fa4', u'\u996e\u54c1']...)
doc_vectors = [dictionary.doc2bow(text) for text in corpus]
print len(doc_vectors)
print doc_vectors
3
[[(0, 1), (1, 3), (2, 2), (3, 1), (4, 3), (5, 3), (6, 3), (7, 1), (8, 1), (9, 1), (10, 1), (11, 3), (12, 1), (13, 2), (14, 3), (15, 3), (16, 1), (17, 2), (18, 1), (19, 1), (20, 1), (21, 2), (22, 1), (23, 1), (24, 1), (25, 1), (26, 1), (27, 3), (28, 1), (29, 1), (30, 1), (31, 1), (32, 1), (33, 1), (34, 1), (35, 1), (36, 1), (37, 1), (38, 1), (39, 1), (40, 2), (41, 1), (42, 2), (43, 1), (44, 2), (45, 1), (46, 4), (47, 1), (48, 2), (49, 1), (50, 2), (51, 1), (52, 1), (53, 1), (54, 1), (55, 1), (56, 1), (57, 1), (58, 1), (59, 1), (60, 1), (61, 1), (62, 1), (63, 1), (64, 1), (65, 3), (66, 1), (67, 1), (68, 1), (69, 2), (70, 2), (71, 5), (72, 1), (73, 2), (74, 3), (75, 1), (76, 1), (77, 1), (78, 2), (79, 1), (80, 1), (81, 1), (82, 1), (83, 2), (84, 3), (85, 1), (86, 2), (87, 1), (88, 3), (89, 1), (90, 1), (91, 1), (92, 2), (93, 1), (94, 1), (95, 2), (96, 2), (97, 1), (98, 3), (99, 1), (100, 1), (101, 1), (102, 2), (103, 1), (104, 1), (105, 1), (106, 1), (107, 1), (108, 2), (109, 1), (110, 1), (111, 1), (112, 1), (113, 1), (114, 1), (115, 1), (116, 1), (117, 1), (118, 1), (119, 2), (120, 1), (121, 1), (122, 1), (123, 1), (124, 1), (125, 1), (126, 1), (127, 1), (128, 5), (129, 5), (130, 1), (131, 1), (132, 2), (133, 1), (134, 1), (135, 1), (136, 1), (137, 1), (138, 6), (139, 1), (140, 1), (141, 1), (142, 4), (143, 1), (144, 2), (145, 1), (146, 1), (147, 1), (148, 2), (149, 1), (150, 1), (151, 5), (152, 1), (153, 1), (154, 1), (155, 1), (156, 1), (157, 1), (158, 1), (159, 1), (160, 1), (161, 2), (162, 15), (163, 3), (164, 1), (165, 1), (166, 2), (167, 1), (168, 6), (169, 1), (170, 1), (171, 1), (172, 3), (173, 1), (174, 1), (175, 2), (176, 1), (177, 1), (178, 2), (179, 2), (180, 1), (181, 6), (182, 1), (183, 1), (184, 1), (185, 2), (186, 1), (187, 1), (188, 1), (189, 1), (190, 1), (191, 1), (192, 1), (193, 1), (194, 1), (195, 1), (196, 1), (197, 1), (198, 1), (199, 1), (200, 1), (201, 5), (202, 1), (203, 2), (204, 2), (205, 1), (206, 1), (207, 1), (208, 1), (209, 2), (210, 1), (211, 1), (212, 1), (213, 1), (214, 1), (215, 1), (216, 1), (217, 1), (218, 1), (219, 3), (220, 1), (221, 1), (222, 4), (223, 1), (224, 1), (225, 1), (226, 1), (227, 1), (228, 1), (229, 1), (230, 1), (231, 2), (232, 12), (233, 1), (234, 1), (235, 1), (236, 2), (237, 1), (238, 1), (239, 1), (240, 1), (241, 1), (242, 1), (243, 1), (244, 1), (245, 1), (246, 1), (247, 4), (248, 2), (249, 1), (250, 1), (251, 1), (252, 1), (253, 2), (254, 1), (255, 1), (256, 1), (257, 6), (258, 1), (259, 2)], [(6, 1), (7, 1), (11, 1), (14, 1), (15, 2), (27, 1), (47, 2), (71, 1), (78, 1), (92, 2), (101, 1), (106, 1), (112, 4), (121, 1), (138, 6), (143, 1), (151, 2), (155, 1), (158, 1), (162, 4), (170, 2), (203, 1), (213, 1), (227, 1), (232, 7), (254, 2), (260, 1), (261, 1), (262, 1), (263, 1), (264, 1), (265, 1), (266, 1), (267, 2), (268, 1), (269, 1), (270, 1), (271, 1), (272, 1), (273, 1), (274, 1), (275, 1), (276, 2), (277, 3), (278, 1), (279, 1), (280, 1), (281, 1), (282, 1), (283, 1), (284, 1), (285, 1), (286, 2), (287, 1), (288, 3), (289, 1), (290, 1), (291, 1), (292, 2), (293, 2), (294, 1), (295, 1), (296, 1), (297, 3), (298, 1), (299, 1), (300, 1), (301, 1), (302, 1)], [(14, 5), (19, 1), (22, 1), (25, 1), (27, 3), (77, 3), (89, 1), (103, 2), (132, 1), (137, 2), (147, 1), (161, 1), (169, 5), (201, 2), (208, 2), (257, 1), (266, 1), (272, 1), (303, 2), (304, 2), (305, 1), (306, 6), (307, 1), (308, 2), (309, 2), (310, 1), (311, 2), (312, 1), (313, 1), (314, 10), (315, 1), (316, 1), (317, 3), (318, 1), (319, 1), (320, 1), (321, 3), (322, 2), (323, 3), (324, 2), (325, 14), (326, 1), (327, 1), (328, 3), (329, 1), (330, 1), (331, 2), (332, 6), (333, 2), (334, 3), (335, 1), (336, 1), (337, 1), (338, 1), (339, 1), (340, 4), (341, 1), (342, 1), (343, 1), (344, 3), (345, 1), (346, 1), (347, 1), (348, 1), (349, 1), (350, 1), (351, 2), (352, 4), (353, 2), (354, 1), (355, 1), (356, 1), (357, 3), (358, 1), (359, 14), (360, 1), (361, 1), (362, 1), (363, 1), (364, 2), (365, 1), (366, 1), (367, 1), (368, 4), (369, 1), (370, 1), (371, 1), (372, 1), (373, 1), (374, 1), (375, 1), (376, 2), (377, 1), (378, 1), (379, 1), (380, 1), (381, 2), (382, 1), (383, 4), (384, 1), (385, 2), (386, 1), (387, 1), (388, 2), (389, 1), (390, 1), (391, 1), (392, 2), (393, 1), (394, 1), (395, 2), (396, 1), (397, 1), (398, 2), (399, 1), (400, 1), (401, 2), (402, 1), (403, 3), (404, 2), (405, 1), (406, 1), (407, 2), (408, 1), (409, 2), (410, 1), (411, 2), (412, 2), (413, 1), (414, 1), (415, 1), (416, 1), (417, 1), (418, 1), (419, 5), (420, 1), (421, 1), (422, 1), (423, 3), (424, 1), (425, 1), (426, 1), (427, 1), (428, 1), (429, 1), (430, 6)]]
建立TF-IDF模型
tfidf = models.TfidfModel(doc_vectors)
tfidf_vectors = tfidf[doc_vectors]
print len(tfidf_vectors)
print len(tfidf_vectors[0])
3
258
构建一个query文本,是高血压主题的,利用词袋模型的字典将其映射到向量空间
query = tokenization('/Users/yiiyuanliu/Desktop/nlp/demo/articles/关于降压药的五个问题.txt')
query_bow = dictionary.doc2bow(query)
print len(query_bow)
print query_bow
35
[(6, 1), (11, 1), (14, 1), (19, 1), (25, 1), (28, 1), (38, 2), (44, 3), (50, 4), (67, 1), (71, 1), (97, 1), (101, 3), (105, 2), (137, 1), (138, 4), (148, 6), (151, 2), (155, 1), (158, 3), (162, 4), (169, 1), (173, 2), (203, 1), (232, 12), (236, 1), (244, 9), (257, 1), (266, 1), (275, 2), (282, 1), (290, 2), (344, 1), (402, 1), (404, 3)]
index = similarities.MatrixSimilarity(tfidf_vectors)
用TF-IDF模型计算相似度,相对于前两篇高血压主题的文本,iOS主题文本与query的相似度很低。可见TF-IDF模型是有效的,然而在语料较少的情况下,与同是高血压主题的文本相似度也不高。
sims = index[query_bow]
print list(enumerate(sims))
[(0, 0.28532028), (1, 0.28572506), (2, 0.023022989)]
构建LSI模型,设置主题数为2(理论上这两个主题应该分别为高血压和iOS)
lsi = models.LsiModel(tfidf_vectors, id2word=dictionary, num_topics=2)
lsi.print_topics(2)
[(0,
u'0.286*"\u9ad8\u8840\u538b" + 0.241*"\u8840\u538b" + 0.204*"\u60a3\u8005" + 0.198*"\u559d" + 0.198*"\u4f4e" + 0.198*"\u8865\u9499" + 0.155*"\u538b\u529b" + 0.155*"\u852c\u83dc" + 0.132*"\u542b\u9499" + 0.132*"\u8840\u9499"'),
(1,
u'0.451*"iOS" + 0.451*"\u5f00\u53d1" + 0.322*"\u610f\u4e49" + 0.193*"\u57f9\u8bad" + 0.193*"\u9762\u8bd5" + 0.193*"\u884c\u4e1a" + 0.161*"\u7b97\u6cd5" + 0.129*"\u9ad8\u8003" + 0.129*"\u5e02\u573a" + 0.129*"\u57fa\u7840"')]
lsi_vector = lsi[tfidf_vectors]
for vec in lsi_vector:
print vec
[(0, 0.74917098831536277), (1, -0.0070559356931168236)]
[(0, 0.74809557226254608), (1, -0.054041302062161914)]
[(0, 0.045784366765220297), (1, 0.99846660199817183)]
在LSI向量空间中,所有文本的向量都是二维的
query = tokenization('/Users/yiiyuanliu/Desktop/nlp/demo/articles/关于降压药的五个问题.txt')
query_bow = dictionary.doc2bow(query)
print query_bow
[(6, 1), (11, 1), (14, 1), (19, 1), (25, 1), (28, 1), (38, 2), (44, 3), (50, 4), (67, 1), (71, 1), (97, 1), (101, 3), (105, 2), (137, 1), (138, 4), (148, 6), (151, 2), (155, 1), (158, 3), (162, 4), (169, 1), (173, 2), (203, 1), (232, 12), (236, 1), (244, 9), (257, 1), (266, 1), (275, 2), (282, 1), (290, 2), (344, 1), (402, 1), (404, 3)]
query_lsi = lsi[query_bow]
print query_lsi
[(0, 7.5170080232286249), (1, 0.10900815862153138)]
index = similarities.MatrixSimilarity(lsi_vector)
sims = index[query_lsi]
print list(enumerate(sims))
[(0, 0.99971396), (1, 0.99625134), (2, 0.060286518)]
可以看到LSI的效果很好,一个高血压主题的文本与前两个训练文本的相似性很高,而与iOS主题的第三篇训练文本相似度很低
参考资料:
Coursera: Text Mining and Analytics
阮一峰:TF-IDF与余弦相似性的应用(一):自动提取关键词
如何计算两个文档的相似度