neo4j使用使用Cypher查询图形数据,Cypher是描述性的图形查询语言,语法简单,功能强大。
和SQL很相似,Cypher语言的关键字不区分大小写,但是,属性值,标签,关系类型和变量是区分大小写的。
1)变量
变量用于对搜索模式的部分进行命名,并在同一个查询中引用,在()中命名变量,变量名是区分大小写的,示例代码创建了两个标量n和b,通过return子句返回变量b。
match (n) --> (b)
return b
2) 访问属性
在Cypher查询中,通过点号来访问属性,格式是Variable.PropertyKey,通过id函数来访问实体的id格式是id(Variable).
match(n) -->(b)
where id(n) = 5 and b.age = 18
return b;
1. 创建节点
节点模式的构成:(var: label1 :label2 {key1:value1,key2:value2}).
每个节点都有一个整数id,创建新节点时,neo4j自动为节点设置ID值,在整个数据库中,节点的id值是递增和唯一的。
create (n:Person {name :'Tom Hanks', born:1956})
return n;
create (n:Person{name:'robert zemeckis', born:1951}) return n;
create(n:Movie{title:'Forrest Gup', released:1951}) return n;
2. 查询节点
通过match子句查询数据库,match子句用于指定搜索的模式,where子句为match子句增加谓词,对模式进行约束。
1)查询整个图数据库
match(n) return n;
2) 查询born属性小于1955的节点
match(n)
where n.born <1955
return n;
3) 查询具有指定label的节点
match(n:movie) return n;
4) 查询具有指定属性的节点
match(n{name:'Tpm Hanks'}) return n;
3. 创建关系
关系的构成: StartNode - [var:relationtype {key1:value1,key2:values2}] -> EndNode
创建关系时,必须指定关系类型
1) 创建没有任何属性的关系
match(a:person), (b:movie)
where a.name = 'Robert Zemeckis' and b.title = 'Forrest Gup'
create (a) - [r: DIRECTED] -> (b)
return r;
2) 创建关系,并设置关系的属性
match(a:person),(b:movie)
where a.name = 'Tom Hanks' and b.title = 'Forrest Gup'
create (a) -[r:acted_in{roles:['Forrest'] }] -> (b)
return r;
4. 查询关系
在Cypher中,关系分为3种:“--”表示有关系,忽略关系的类型和方向;符号“-->” 和 "<--" 表示有方向的关系。
1)查询整个数据图形
match(n) return n;
2)查询跟指定节点有关系的节点
# 返回跟movie标签有关系的所有节点
match(n) -- (m:movie)
return n;
3) 查询有向关系的节点
match(:person{name:'Tom Hanks'} -->(movie)
return movie;
4) 为关系命名,通过[r]为关系定义一个变量名,通过函数type获取关系的类型
match(:person{ name :'Tom Hanks'}) -[r] ->(movie)
return r, type(r);
5)查询特定的关系类型,通过[var:relationshiptype{key:value}] 指定关系的类型和属性
match(:person{name:'Tom Hanks'} ) - [r:acted_in{ roles:'Forrest'}] -> (movie)
return r ,type(r);
5. 更新图形
set子句,用于更新实体的属性和节点的标签;
remove子句,用于移除实体的属性和节点的标签。
1) 创建一个完整的path
由于path是由节点和关系构成,当路径中的关系或节点不存在时,neo4j会自动创建。
create p = (vic:worker:person{name:'vic' , title:'developer'}) - [: works_at] -> (neo) <- [:works_at] - (michael:worker:person{name:'michael', title:'manager'})
return p;
变量neo代表的节点没有属性,但是,有一个ID值,通过ID值为该节点设置属性和标签。
2)为节点增加属性
通过节点的ID获取节点,neo4j推荐通过where子句和ID函数来实现。
match(n)
where id(n) = 203
set n.name = 'neo'
return n;
3)为节点增加标签
match(n)
where id(n) = 203
set n:company
return n;
4)为关系增加属性
match(n) -[r]-(m)
where id(n) =203 and id(m) = 8
set r.team = 'Azure'
return n;
6. merge子句
merge子句的作用有两个:
- 当模式存在时,匹配该模式;
- 当模式不存在时,创建新的模式,功能是match子句和create子句的组合。
在mrge子句之后,可以显式指定on create 和on match子句,用于修改绑定的节点和关系的属性。
通过merge子句,可以指定图形中必须存在一个节点,该节点必须具有特定的标签,属性等,如果不存在,那么merge子句将创建相应的节点。
1)通过merge子句匹配搜索模式
匹配模式:一个节点有person标签,并且具有name属性;如果数据库不存在该模式,那么,创建新的节点,如果存在该模式,那么,绑定该节点。
merge(michael:person{name:'michael douglas'})
return michael;
2)在merge子句中指定on create子句
如果需要创建节点,那么执行on create 子句,修改节点的属性。
merge(keanu:person{name:'keanu reeves'})
on create set keanu.created = timestamp()
return keanu.name,keanu.created;
3)在merge子句中指定on match子句
如果节点已经存在于数据库中,那么,执行on match子句修改节点的属性。
merge(per:person)
on match set per.found = True, per.lastaccessed = timestamp()
return per.name, per.found, per.lastaccessed;
4) 在merge子句中同时指定on create和on match子句
merge(keanu:person{name:'Keanu Reeves'})
on create set keanu.created = timestamp()
on match set keanu.lastseen = timestamp()
return keanu.name, keanu.created, keanu.lastseen;
5)merge子句用于match或create一个关系
match(charlie:person{name:'Charlie Sheen'}), (wallstreet:movie{title:'Wall Street'})
merge (charlie) -[r:acted_in] ->(wallstreet)
return charlie.name, type(r), wallstreet.title;
6) merge子句用于match或create多个关系
match(oliver:person{name:'Oliver Stone'}), (reiner:person{name:'Rob Reiner'})
merge(oliver)-[:directed]->(mov:movie) <- [:acted_in]-(reiner)
return mov;
7)merge子句用于子查询
match(per:person)
merge(city:City{name:per.bornIn})
return person.name, person.bornIn,city;
match(per:person)
merge(per)-[r:has_chauffeur]->(chauffeur:Chauffeur{name:per.chauffeurName})
return per.name, per.chauffeurName, chauffeur;
match(per:person)
merge(city:City{name:per.bornIn})
merge(person) -[r:born_in] ->(city)
return per.name, per.bornIn, city;
8. 跟实体相关的函数
1)通过id函数,返回节点或关系的ID
match(:person{name:'Oliver Stone'}) - [r] ->(movie)
return id(r);
2)通过type函数,查询关系的类型
match(:person{name:'Oliver Stone'}) - [r] -> (movie)
return type(r);
3)通过labels函数,查询节点的标签
match(:person{name:'Oliver Stone'}) -[r] - >(movie)
return lables(movie);
4)通过keys函数,查看节点或关系的属性值
match(a)
where a.name = 'Alice'
return keys(a);
5)通过properties函数,查看节点或关系的属性
create (p:person{name:'Stefan', city:'Berlin'})
return properties(p);
9. 模式
模式,用于描述如何搜索数据,模式的格式是:使用()标识节点,使用[]标识关系。
1)节点模式
节点具有标签和属性,Cypher为了引用节点,需要给节点命名:
- (n):该模式用于描述节点,节点的变量名是n;匿名节点是()
- (n: label):节点具有特定的标签label,也可以指定多个标签
- (n{name:"Vic"}):节点具有name属性,且name属性的值是“Vic”,也可以指定多个属性
- (n:label{name:"Vic"}):节点具有特定的标签和name属性,并且name属性值是“Vic”
2)关系模式
在属性图中,节点之间存在关系,关系通过[]表示,节点之间的关系通过箭头()-[]->()表示,例如:
- [r]:关系的变量名是r;匿名关系是[]
- [r:type]:关系类型是type,且每一个关系必须有且仅有一个类型
- [r:type{name:"Friend"}]:关系的类型是type,关系具有属性name,并且name属性值是Friend
3)关联节点模式
节点之间通过关系联系在一起,由于关系具有方向性,因此,-->表示存在有向的关系,--表示存在关联,不指定关系的方向,例如:
- (a) -[r]->(b):该模式用于描述节点ab之间存在有向的关系r
- (a) -->(b):该模式用于描述a和b之间存在有向关系
4)变长路径的模式
从一个节点,通过直接关系,连接到另外一个节点,这个过程叫遍历,经过的节点和关系的组合叫做路径,路径是节点和关系的有序组合:
- (a)-->(b):是步长为1的路径,节点a和b之间有关系直接关联
- (a)-->()-->(b):是步长为2的路径,从节点a,经过两个关系和一个节点,到达节点b
Cypher语言支持变长路径模式,变长路径的表示方式是:[*N..M],N和M表示路径长度的最小值和最大值。
- (a)-[*2]->(b):从a节点到b节点经过的路径长度为2
- (a)-[*3..5]->(b):从a到b经过的路径长度,最小值是3,最大值是5
- (a)-[*..5]->(b):从a到b的路径长度最大值是5
- (a)-[*3..]->(b):从a到b路径长度最小值是3
- (a)-[*]-(b):不限制路径长度
5)路径变量
路径可以指定给一个变量,该变量是路径变量,用于引用查询路径。
p = (a)-[*3..5]->(b)
6)示例
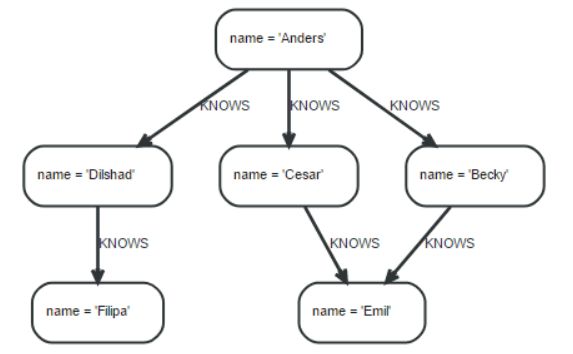
查询模式:查找跟Filipa有关系的人,路径程度为1或2
match(me) -[:KNOWS*1..2]-(remote_friend)
where me.name = 'Flilipa'
return remote_friend.name;
10. 查询子句
1)with子句
一个查询有很多查询子句,每一个查询子句按照特定的顺序执行,每一个子句是查询的一部分,with子句表示查询的一部分,在该部分输出结果之前,把输出传递到其他子句中去。
with子句保留otherperson,并新增聚合查询count(*),通过where子句过滤,返回查询结果
match(david{name:'David'}) -- (otherperson) -->()
with otherperson, count(*) as foaf
where foaf > 1
return otherperson.name;
2) foreach子句
foreach子句,用于更新列表中的数据,更新的格式:
match p = (begin) -[*]->(end)
where begin.name = 'A' and end.name = 'D'
foreach (n in nodes(p) | set n.marked = TRUE);