batch normalization的原理和作用_【推荐算法】Deep & Cross Network模型原理和实践...
1 算法背景
Deep & Cross Network是谷歌和斯坦福大学在2017年提出的用于Ad Click Prediction的模型,主要用在广告点击率预估方面,应用于推荐系统排序阶段。Deep & Cross Network(简称DCN),顾名思义应该是包含两大块,Cross和Deep两个部分,依然还是围绕特征组合表示来做文章。
针对CTR任务中的特征组合问题,传统方法主要通过FM、FFM等算法针对低阶特征组合进行建模,没有考虑到高阶特征对于CTR任务的贡献。那么如何来挖掘出有效的高阶特征组合呢?我们很自然的想法,通过多层的神经网络去解决。2017年华为提出了DeepFM模型,同时训练FM模型和DNN模型,并将FM的隐向量作为DNN的输入,最后将两者并行处理,笔者在【推荐算法】DeepFM模型原理与实践一文中,对此作了详细的介绍,结合笔者的思考给出了基于tf2.0的实现。本文介绍的Deep & Cross Network模型也是为了实现更高阶的特征组合,但是它在特征输入后的Embedding层以及特征交互模块与DeepFM有所不同。
2 模型结构
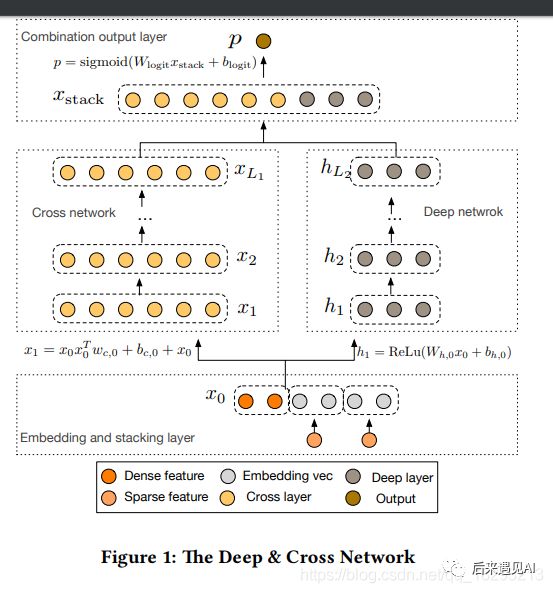 Deep & Cross Network模型结构
Deep & Cross Network模型结构
DCN模型结构比较简单,以一个嵌入和堆叠层(embedding and stacking layer)开始,接着并列连一个cross network和一个deep network,接着通过一个combination layer将两个network的输出进行组合。
2.1 嵌入(Embedding)和堆叠层(stacking)
这一层就是将离散特征embedding之后再flatten,然后与数值类型的特征合并在一起作为整个模型的输入,输入表示如下:
网上大部分文章在这一层的实现方式是:
- 输入层有三个输入:离散特征Index、离散特征onehot、连续数值型特征
- 对离散特征Index使用
Embedding(n, em_dim),获取所有特征的向量表示。[batch_size, n_cate_features, emb_dim] - 将onehot特征
[batch_size, n_cate_features]reshape为[batch_size, n_cate_features, 1],然后与前面的embedding相乘得到当前这一组特征的embedding[batch_size, n_cate_features, emb_dim] - 将当前这一组特征的embedding
[batch_size, n_cate_features, emb_dim]flatten为[batch_size, n_cate_features*emb_dim] - 将上述离散特征embedding与数值类型的特征
[batch_size, n_numeric_features]concate起来作为整个模型的输入[batch_size, n_cate_features + n_numeric_features]
笔者对这一层的实现方式做了一点简化,听我慢慢道来。
什么是Embedding?
Embedding操作其实就是用一个矩阵和one-hot之后的输入相乘,也可以看成是一次查询(lookup)。这个Embedding矩阵跟网络中的其他参数是一样的,是需要随着网络一起学习的。
既然如此,咱们显式地初始化一个embedding矩阵,用自定义层实现即可,省去了离散特征Index的构造。分为四步:
第一步:初始化embedding矩阵
self.kernel = self.add_weight(name='cate_em_vecs',
shape=(1, input_shape[1] * self.emb_dim),
initializer='glorot_uniform',
trainable=True)
等等,为啥kernel是一个[1, n_cate_features * emb_dim]的矩阵?难道不应该是[n_cate_features, emb_dim]么?因为迟早要和数值型输入concate,直接定义成一行的,免得reshape.
第二步:使用repeat_elements(x, rep=self.emb_dim, axis=1)将onehot型输入在第1维复制em_dim倍
x = K.repeat_elements(x, rep=self.emb_dim, axis=1)
第三步:将前两步的矩阵按元素相乘得到离散特征的embedding,[batch_size, n_cate_features*emb_dim]
第四步:将上述离散特征embedding与数值类型的特征[batch_size, n_numeric_features]concate起来作为整个模型的输入[batch_size, n_cate_features + n_numeric_features]
总体看起来,简洁了一丢丢。
2.2 交叉网络(Cross Network)
交叉网络的核心思想是以有效的方式应用显式特征交叉。交叉网络由交叉层组成,每个层具有以下公式:
其中:
- 是第和第层cross layers的输出;
- 是第 层layer的weight和bias参数。注意这里是一个只有一列的矩阵
在完成一个特征交叉后,每个cross layer会将它的输入加回去,这里借鉴了残差网络的思想。相当于是在拟合该层输出和上一层输出的残差。
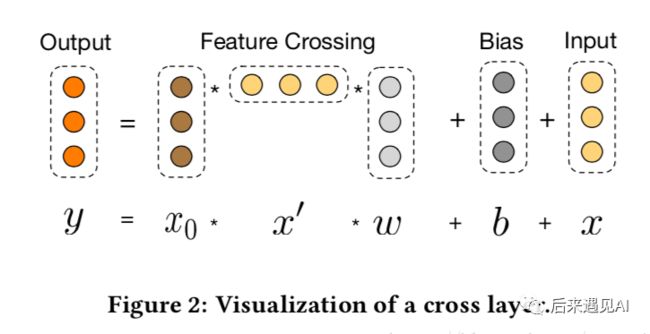
可以看到,交叉网络的特殊结构使特征组合的阶数随着交叉层深度的增加而增大。相对于输入来说,一个层的cross network的cross feature的阶数为。如果用表示交叉层数,表示输入的维度,那么整个cross network的参数个数为:
从上式可以发现,复杂度是输入维度的线性函数。所以相比于deep network,cross network引入的复杂度微不足道。论文中表示,Cross Network之所以能够高效的学习组合特征,就是因为x0 * xT的秩为1,使得我们不用计算并存储整个的矩阵就可以得到所有的cross terms。
但是,正是因为cross network的参数比较少导致它的表达能力受限,为了捕捉高度非线性的相互作用,DCN并行的引入了Deep Network。
根据论文中的计算公式,笔者实现了一个crossLayer,代码如下:
class CrossLayer(keras.layers.Layer):
def __init__(self, **kwargs):
self.cross_dense = keras.layers.Dense(1, use_bias=True)
super(CrossLayer, self).__init__(**kwargs)
def call(self, inp, **kwargs):
x0, xl = inp
if (K.ndim(x0) <= 2):
x0 = x0[..., tf.newaxis]
if (K.ndim(xl) <= 2):
xl = xl[..., tf.newaxis]
# [batch_size, n_features, 1] -> [batch_size, n_features, n_features]
x0l = tf.matmul(x0, xl, transpose_b=True)
out = self.cross_dense(x0l) + xl
out = tf.reshape(out, (-1, out.shape[1]))
return out
def compute_output_shape(self, input_shape):
return (input_shape[0][0], input_shape[0][1])
主要分为4步:
将输入和reshape为
[batch_size, n_features, 1]计算,这一步使得特征形成了交互,示意图如下:
计算,这里其实就是相当于对进行一次Dense,再加上
将输出由
[batch_size, n_features, 1]reshape为[batch_size, n_features]
2.3 Deep Network
这里就是朴实无华的多层Dense了,输入就是嵌入(Embedding)和堆叠层(stacking)的输出,这里就不多介绍了。
2.4 模型输出
最后将Cross和Deep两个部分的结果拼接起来加一层逻辑回归就是最终的模型输出:
self.concate_out = keras.layers.Concatenate(axis=-1, name="concate_out")
self.com_dense = keras.layers.Dense(1, activation="sigmoid")
self.combine_out = self.concate_out([xl, y_deep])
self.combine_out = self.com_dense(self.combine_out)
self.model = keras.Model([self.cate_inp, self.numeric_inp], self.combine_out)
self.model.compile(loss=keras.losses.binary_crossentropy,
optimizer="adam",
metrics=[keras.metrics.binary_accuracy, keras.metrics.Recall()])
2.5 模型整体结构和代码
dcn.py
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import backend as K
class CateEmbedding(keras.layers.Layer):
def __init__(self, emb_dim, **kwargs):
self.emb_dim = emb_dim
super(CateEmbedding, self).__init__(**kwargs)
def build(self, input_shape):
self.kernel = self.add_weight(name='cate_em_vecs',
shape=(1, input_shape[1] * self.emb_dim),
initializer='glorot_uniform',
trainable=True)
def call(self, x, **kwargs):
x = K.repeat_elements(x, rep=self.emb_dim, axis=1)
return x * self.kernel
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1] * self.emb_dim)
class CrossLayer(keras.layers.Layer):
def __init__(self, **kwargs):
self.cross_dense = keras.layers.Dense(1, use_bias=True)
super(CrossLayer, self).__init__(**kwargs)
def call(self, inp, **kwargs):
x0, xl = inp
if (K.ndim(x0) <= 2):
x0 = x0[..., tf.newaxis]
if (K.ndim(xl) <= 2):
xl = xl[..., tf.newaxis]
# [batch_size, n_features, 1] -> [batch_size, n_features, n_features]
x0l = tf.matmul(x0, xl, transpose_b=True)
out = self.cross_dense(x0l) + xl
out = tf.reshape(out, (-1, out.shape[1]))
return out
def compute_output_shape(self, input_shape):
return (input_shape[0][0], input_shape[0][1])
class DeepCrossNetwork:
def __init__(self, n_cate_features, n_numeric_features, emb_dim, num_cross_layers, dnn_units=[8, 8, 8], rate=.2):
self.cate_inp = keras.Input(shape=(n_cate_features,), name="cate_inp")
self.numeric_inp = keras.Input(shape=(n_numeric_features,), name="numeric_inp")
self.cate_emb_layer = CateEmbedding(emb_dim, name="cate_emb")
self.concate_inp = keras.layers.Concatenate(axis=-1, name="concate_inp")
self.cross_layers = [CrossLayer(name="cross_{}".format(i)) for i in range(num_cross_layers)]
# self.reshape = keras.layers.Reshape((n_cate_features + n_numeric_features,))
self.dnn_layers = [keras.layers.Dense(units, activation="relu") for units in dnn_units]
self.rate = rate
self.concate_out = keras.layers.Concatenate(axis=-1, name="concate_out")
self.com_dense = keras.layers.Dense(1, activation="sigmoid")
def build(self):
# (batch_size, n_cate_features) -> (batch_size, n_cate_features * emb_dim)
cate_emb = self.cate_emb_layer(self.cate_inp)
# (batch_size, n_cate_features * emb_dim + n_numeric_featrues)
inp = self.concate_inp([cate_emb, self.numeric_inp])
xl = inp
for layer in self.cross_layers:
xl = layer([inp, xl])
y_deep = keras.layers.Dropout(self.rate)(inp)
for layer in self.dnn_layers:
y_deep = layer(y_deep)
y_deep = keras.layers.Dropout(self.rate)(y_deep)
self.combine_out = self.concate_out([xl, y_deep])
self.combine_out = self.com_dense(self.combine_out)
self.model = keras.Model([self.cate_inp, self.numeric_inp], self.combine_out)
self.model.compile(loss=keras.losses.binary_crossentropy,
optimizer="adam",
metrics=[keras.metrics.binary_accuracy, keras.metrics.Recall()])
结构图如下:
keras.utils.plot_model(dcn.model, "dcn.png", show_layer_names=True, show_shapes=True)
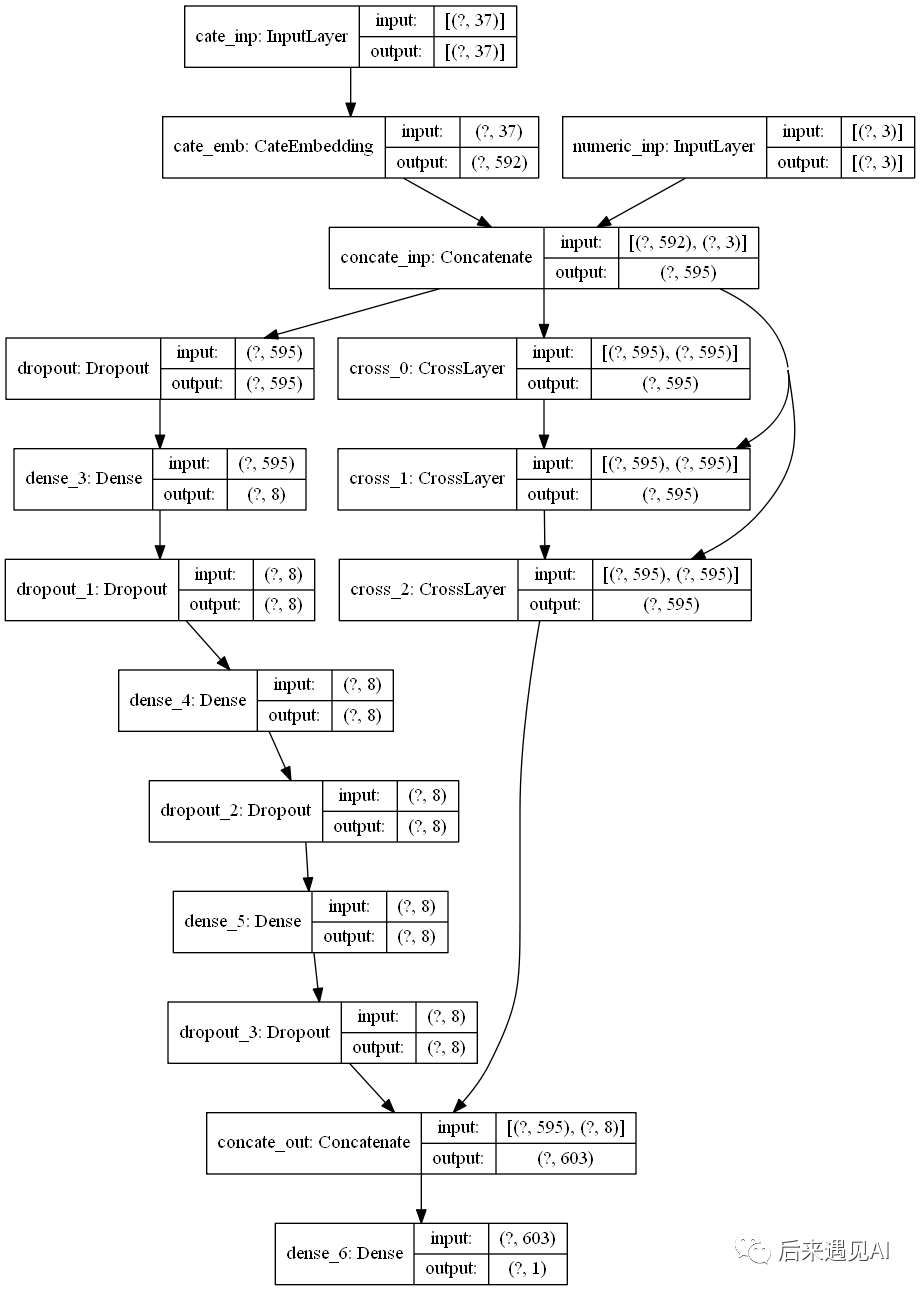 dcn
dcn
3 案例实践:基于DCN预估电信用户流失
3.1 导入库
import tensorflow as tf
import tensorflow.keras.backend as K
from tensorflow import keras
import numpy as np
import pandas as pd
from dcn import DeepCrossNetwork
# 设置GPU显存动态增长
gpus = tf.config.experimental.list_physical_devices(device_type="GPU")
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
3.2 输入数据处理
# 单值离散特征
single_discrete = ['gender', 'SeniorCitizen', 'Partner', 'Dependents', 'PhoneService', 'PaperlessBilling']
# 多值离散特征
multi_discrete = ['MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection',
'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaymentMethod']
# 连续数值特征
continuous = ["tenure", "MonthlyCharges", "TotalCharges"]
# 连续数值特征处理
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[continuous] = scaler.fit_transform(data[continuous])
multi_discrete_data = pd.get_dummies(data[multi_discrete], columns=multi_discrete)
data = pd.concat([data, multi_discrete_data], axis=1)
features = single_discrete + list(multi_discrete_data.columns) + continuous
# 划分训练集测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data[features], data["Churn"],
test_size=.1,
random_state=10, shuffle=True)
# 切分离散输入和连续数值型输入
X_train_discreete = X_train[single_discrete + list(multi_discrete_data.columns)]
X_train_continuous = X_train[continuous]
X_test_discreete = X_test[single_discrete + list(multi_discrete_data.columns)]
X_test_continuous = X_test[continuous]
# 洗牌、划分batch,转为可输入模型tensor,注意这里是多输入的模型,可用如下方式打包输入数据
train_dataset1 = tf.data.Dataset.from_tensor_slices((X_train_discreete.values, X_train_continuous.values))
train_dataset2 = tf.data.Dataset.from_tensor_slices(y_train.values)
train_dataset = tf.data.Dataset.zip((train_dataset1, train_dataset2)).shuffle(len(X_train)).batch(32)
test_dataset1 = tf.data.Dataset.from_tensor_slices((X_test_discreete.values, X_test_continuous.values))
test_dataset2 = tf.data.Dataset.from_tensor_slices(y_test.values)
test_dataset = tf.data.Dataset.zip((test_dataset1, test_dataset2)).batch(32)
3.3 建立模型
dcnal = DeepCrossNetwork(n_cate_features=37,
n_numeric_features=3,
emb_dim=8,
num_cross_layers=2)
dcnal.build()
dcnal.model.summary()
#output:
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
cate_inp (InputLayer) [(None, 37)] 0
__________________________________________________________________________________________________
cate_emb (CateEmbedding) (None, 296) 296 cate_inp[0][0]
__________________________________________________________________________________________________
numeric_inp (InputLayer) [(None, 3)] 0
__________________________________________________________________________________________________
concate_inp (Concatenate) (None, 299) 0 cate_emb[0][0]
numeric_inp[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 299) 0 concate_inp[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 8) 2400 dropout[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 8) 0 dense_2[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 8) 72 dropout_1[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 8) 0 dense_3[0][0]
__________________________________________________________________________________________________
cross_0 (CrossLayer) (None, 299) 300 concate_inp[0][0]
concate_inp[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 8) 72 dropout_2[0][0]
__________________________________________________________________________________________________
cross_1 (CrossLayer) (None, 299) 300 concate_inp[0][0]
cross_0[0][0]
__________________________________________________________________________________________________
dropout_3 (Dropout) (None, 8) 0 dense_4[0][0]
__________________________________________________________________________________________________
concate_out (Concatenate) (None, 307) 0 cross_1[0][0]
dropout_3[0][0]
__________________________________________________________________________________________________
dense_5 (Dense) (None, 1) 308 concate_out[0][0]
==================================================================================================
Total params: 3,748
Trainable params: 3,748
Non-trainable params: 0
模型总共包含3748个待训练参数,训练集大小才6000,有点少。
dcnal.model.fit(train_dataset, epochs=20)
#output:
Train for 199 steps
Epoch 1/20
199/199 [==============================] - 3s 16ms/step - loss: 0.4868 - binary_accuracy: 0.7706 - recall: 0.3749
Epoch 2/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4233 - binary_accuracy: 0.7987 - recall: 0.5287
Epoch 3/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4196 - binary_accuracy: 0.8021 - recall: 0.5251
Epoch 4/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4170 - binary_accuracy: 0.8023 - recall: 0.5386
Epoch 5/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4153 - binary_accuracy: 0.8029 - recall: 0.5409
Epoch 6/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4176 - binary_accuracy: 0.8021 - recall: 0.5333
Epoch 7/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4150 - binary_accuracy: 0.8045 - recall: 0.5374
Epoch 8/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4172 - binary_accuracy: 0.8044 - recall: 0.5374
Epoch 9/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4163 - binary_accuracy: 0.8033 - recall: 0.5363 1s - loss: 0.4207 - bina
Epoch 10/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4152 - binary_accuracy: 0.8050 - recall: 0.5310
Epoch 11/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4154 - binary_accuracy: 0.8033 - recall: 0.5357
Epoch 12/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4147 - binary_accuracy: 0.8034 - recall: 0.5281
Epoch 13/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4144 - binary_accuracy: 0.8044 - recall: 0.5404
Epoch 14/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4176 - binary_accuracy: 0.8025 - recall: 0.5292
Epoch 15/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4149 - binary_accuracy: 0.8039 - recall: 0.5363
Epoch 16/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4144 - binary_accuracy: 0.8048 - recall: 0.5339
Epoch 17/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4166 - binary_accuracy: 0.8037 - recall: 0.5316
Epoch 18/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4176 - binary_accuracy: 0.8040 - recall: 0.5281
Epoch 19/20
199/199 [==============================] - 2s 12ms/step - loss: 0.4129 - binary_accuracy: 0.8042 - recall: 0.5322 0s - loss: 0.4188 - binary_a
Epoch 20/20
199/199 [==============================] - 3s 13ms/step - loss: 0.4130 - binary_accuracy: 0.8055 - recall: 0.5409
最终准确率在81%左右,召回率差不多54%,和DeepFM差不多,这里就不介绍调参工作了。
3.4 模型评估
loss, acc, recall = dcnal.model.evaluate(test_dataset)
loss, acc, recall
#output:
23/23 [==============================] - 0s 12ms/step - loss: 0.3805 - binary_accuracy: 0.8156 - recall: 0.4214
(0.3805022394972975, 0.81560284, 0.42138365)
验证集上准确率为80.3%,和训练集差不多,召回率为42.1%,有点过拟合了。