多模态情感分析模型VistaNet代码实践
目录
-
- 1 介绍
- 2 原理简述
- 3 层的定义
- 4 模型定义
- 写在最后
1 介绍
关于模型 VistaNet 的原理,我已在之前的文章 基于多模态数据的情感分析 中进行了详细介绍。本文是其姊妹篇,主要以搭建模型的代码为主,对算法原理不清楚的小伙伴建议先熟悉一下原理。
鉴于有很多小伙伴评论和私信问我有没有此模型的代码,最近两天我对 VistaNet 进行了复现,本文会结合算法的原理进行代码的讲解,代码中加入充分注释以易理解。
Tips: 文本代码使用 TF2.x 实现。
下面进入正题…
2 原理简述
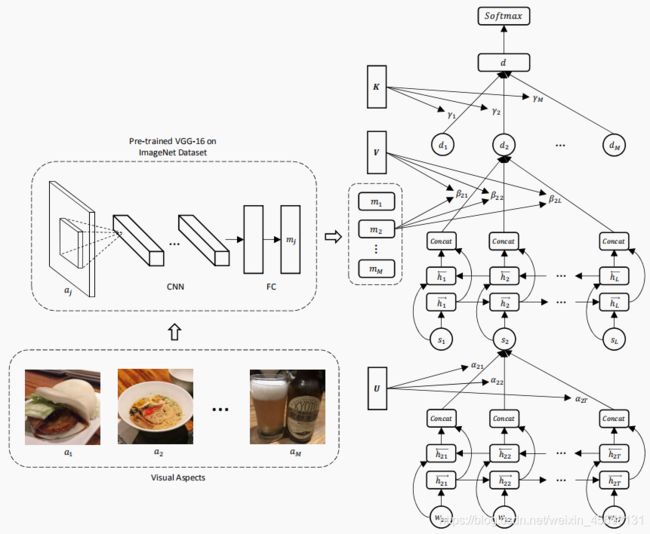 上图为 VistaNet 的模型结构图,大致分为三层:
上图为 VistaNet 的模型结构图,大致分为三层:
- Word Encoder + Attention: 将一个句子的所有词输入单层双向 GRU 层得到词向量,然后这些词向量经过自注意力机制计算得到对应的权重,最后加权累加得到句子的向量表示。(模型输入的一条样本为一个文档 (一段评论),文档的每个句子都会经过该层得到向量表示,一个文档的最大句子数定义为L,所以经过该层共得到 L 个句向量 )
- Sentence Encoder + Attention: 将一个文档的所有句向量输入单层双向 GRU 层得到加强语义后的句向量,评论附带的图片会经过 VGG-16 得到图像向量。所有句向量分别跟每一个图像向量使用注意力计算得到相应的权重,然后加权累加得到一个文档向量,有 M 张图像就会得到 M 个文档向量,表示不同图像对应的不同向量描述。
- Document Encoder + Attention: 多个文档向量经过自注意力计算相应权重,然后加权求和得到最终的文档向量描述d,最后接任务层做 softmax 得到多分类结果即可。
3 层的定义
3.1 Word Encoder + Attention
以下是自注意力的计算流程,表示对 GRU 层每时刻的输出 h 进行行加权求和。

下面是自注意力层的实现代码,建议结合公式理解代码,并且注意每次运算后张量 shape 的变化。
import tensorflow as tf
from tensorflow.keras.layers import Layer
from tensorflow.keras.layers import Dense, Conv2D, MaxPool2D, Dropout, Flatten
import tensorflow.keras.backend as K
# 自注意力层
class Self_Attention(Layer):
# input: [None, n, k]输入为n个维度为k的词向量
# mask: [None, n]表示填充词位置的mask
# output: [None, k]输出n个词向量的加权和
def __init__(self, dropout_rate=0.0):
super(Self_Attention, self).__init__()
self.dropout_layer = Dropout(dropout_rate)
def build(self, input_shape):
self.k = input_shape[0][-1] #词向量维度
self.W_layer = Dense(self.k, activation='tanh', use_bias=True) #对h的映射
self.U_weight = self.add_weight(name='U', shape=(self.k, 1), #U记忆矩阵
initializer=tf.keras.initializers.glorot_uniform(),
trainable=True)
def call(self, inputs, **kwargs):
input, mask = inputs #输入有两部分[input, mask]
if K.ndim(input) != 3:
raise ValueError("The dim of inputs is required 3 but get {}".format(K.ndim(input)))
# 计算score
x = self.W_layer(input) # [None, n, k]
score = tf.matmul(x, self.U_weight) # [None, n, 1]
score = self.dropout_layer(score) # 随机dropout(也可不要)
# softmax之前进行mask
mask = tf.expand_dims(mask, axis=-1) # [None, n, 1]
padding = tf.cast(tf.ones_like(mask)*(-2**31+1), tf.float32) #mask的位置填充很小的负数
score = tf.where(tf.equal(mask, 0), padding, score)
score = tf.nn.softmax(score, axis=1) # [None, n, 1] mask之后计算softmax
# 向量加权和
output = tf.matmul(input, score, transpose_a=True) # [None, k, 1]
output /= self.k**0.5 # 归一化
output = tf.squeeze(output, axis=-1) # [None, k]
return output
3.2 Sentence Encoder + Attention
下面是图像与句向量之间的注意力计算公式,首先是分别对图像向量与句向量的非线性转换,然后计算两者的内积,再乘上记忆矩阵 V,经过 softmax 得到对应的权重。

class Image_Text_Attention(Layer):
# 该层的输入有三部分image_emb、seq_emb、mask
# image_emb: [None, M, 4096]对应M个4096维的图像向量(由vgg16提取得到),每条评论的M可以不一致
# seq_emb: [None, L, k]表示L个维度为k的句向量
# mask: [None, L]表示L个句子的mask(因为存在句子数不足L的文档,有被padding的句子)
# output: [None, M, k]输出为M个图像对应的文档向量表示
def __init__(self, dropout_rate=0.0):
super(Image_Text_Attention, self).__init__()
self.dropout_layer = Dropout(dropout_rate)
def build(self, input_shape):
self.l = input_shape[1][1] # 句子个数
self.k = input_shape[1][-1] # 句向量维度
self.img_layer = Dense(1, activation='tanh', use_bias=True) # 将image_emb映射到1维
self.seq_layer = Dense(1, activation='tanh', use_bias=True) # 将seq_emb也映射到1维(方便内积)
self.V_weight = self.add_weight(name='V', shape=(self.l, self.l),
initializer=tf.keras.initializers.glorot_uniform(),
trainable=True)
def call(self, inputs, **kwargs):
image_emb, seq_emb, mask = inputs # 输入为三部分[image_emb, seq_emb, mask]
# 线性映射
p = self.img_layer(image_emb) # [None, M, 1]
q = self.seq_layer(seq_emb) # [None, L, 1]
# 内积+映射(计算score)
emb = tf.matmul(p, q, transpose_b=True) # [None, M, L]
emb = emb + tf.transpose(q, [0, 2, 1]) # [None, M, L]
emb = tf.matmul(emb, self.V_weight) # [None, M, L]
score = self.dropout_layer(emb) # 随机dropout(也可不要)
# mask
mask = tf.tile(tf.expand_dims(mask, axis=1), [1, score.shape[1], 1]) # [None, M, L],将mask矩阵复制到与score相同的形状
padding = tf.cast(tf.ones_like(mask) * (-2 ** 31 + 1), tf.float32)
score = tf.where(tf.equal(mask, 0), padding, score)
score = tf.nn.softmax(score, axis=-1) # [None, M, L]
# 向量加权和
output = tf.matmul(score, seq_emb) # [None, M, k]
output /= self.k**0.5 # 归一化
return output
3.3 Document Encoder + Attention
该部分的注意力计算公式如下,同第一层的自注意力层,是将 M 个文档向量加权求和得到一个文档向量,该层直接使用之前的 Self_Attention 层即可。
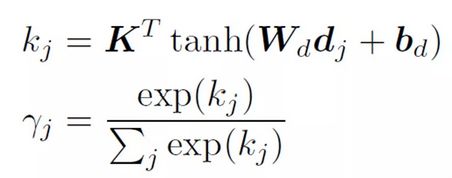
3.4 VGG-16
VGG16 的原理这里不再赘述,可自行查找其原理,并结合起来理解以下代码。
class VggNet(Layer):
def __init__(self, block_nums, out_dim=1000, dropout_rate=0.0):
# block_nums: [list],表示每个模块中连续卷积的个数,vgg16为[2,2,3,3,3]
# out_dim: 该层最终的输出维度
super(VggNet, self).__init__()
self.cnn_block1 = self.get_cnn_block(64, block_nums[0])
self.cnn_block2 = self.get_cnn_block(128, block_nums[1])
self.cnn_block3 = self.get_cnn_block(256, block_nums[2])
self.cnn_block4 = self.get_cnn_block(512, block_nums[3])
self.cnn_block5 = self.get_cnn_block(512, block_nums[4])
self.out_block = self.get_out_block([4096, 4096], out_dim, dropout_rate)
self.flatten = Flatten()
# 单个卷积模块的搭建(layer_num个连续卷积加一个池化)
def get_cnn_block(self, out_channel, layer_num):
layer = []
for i in range(layer_num):
layer.append(Conv2D(filters=out_channel,
kernel_size=3,
padding='same',
activation='relu'))
layer.append(MaxPool2D(pool_size=(2,2), strides=2))
return tf.keras.models.Sequential(layer) #封装成一个模块
# 输出模块的搭建(连续的全连接层)
def get_out_block(self, hidden_units, outdim, dropout_rate):
layer = []
for i in range(len(hidden_units)-1):
layer.append(Dense(hidden_units[i], activation='relu'))
layer.append(Dropout(dropout_rate))
layer.append(Dense(outdim, activation='softmax'))
return tf.keras.models.Sequential(layer) #封装成一个模块
def call(self, inputs, **kwargs):
# 标准输入:[batchsize, 224, 224, 3]
if K.ndim(inputs) != 4:
raise ValueError("The dim of inputs is required 4 but get {}".format(K.ndim(inputs)))
x = inputs
cnn_block_list = [self.cnn_block1, self.cnn_block2, self.cnn_block3, self.cnn_block4, self.cnn_block5]
# 卷积层
for cnn_block in cnn_block_list:
x = cnn_block(x)
x = self.flatten(x)
# 输出层
output = self.out_block(x)
return output
4 模型定义
搭建好了所有需要使用的 Layer 后,下面开始整体模型的搭建。
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, GRU, Bidirectional
class VistaNet(Model):
def __init__(self, block_nums=[2,2,3,3,3], out_dim=4096, vgg_dropout=0.0, attention_dropout=0.0, gru_units=[64, 128], class_num=5):
# block_nums: vgg16各层卷积的个数
# out_dim: vgg16输出维度
# dropout: 各层的dropout系数
# gru_units: 两个单层双向GRU的输出维度
# class_num: 模型最终输出维度
super(VistaNet, self).__init__()
self.vgg16 = VggNet(block_nums, out_dim, vgg_dropout) # VGG-16
self.word_self_attention = Self_Attention(attention_dropout)# 第一层中的自注意力
self.img_seq_attention = Image_Text_Attention(attention_dropout) # 第二层中的Image-Text注意力
self.doc_self_attention = Self_Attention(attention_dropout) # 第三层中的自注意力
# 两个单层双向GRU层
self.BiGRU_layer1 = Bidirectional(GRU(units=gru_units[0],
kernel_regularizer=tf.keras.regularizers.l2(1e-5),
recurrent_regularizer=tf.keras.regularizers.l2(1e-5),
return_sequences=True),
merge_mode='concat')
self.BiGRU_layer2 = Bidirectional(GRU(units=gru_units[1],
kernel_regularizer=tf.keras.regularizers.l2(1e-5),
recurrent_regularizer=tf.keras.regularizers.l2(1e-5),
return_sequences=True),
merge_mode='concat')
self.output_layer = Dense(class_num, activation='softmax') # 任务层
def call(self, inputs, training=None, mask=None):
# 输入inputs包含三部分:(假设batchsize为1,省略掉第一维None)
# image_inputs: [M, 227, 227, 3]一条评论样本包含的M个图像
# text_inputs: [L, T, k]一条样本表示一个文档,所以输入张量为3维:[最大句子数,最大单词数, 词向量维度]
# mask: [L, T]每句话中mask词的位置
image_inputs, text_inputs, mask = inputs
# 获取图像emb向量
image_emb = self.vgg16(image_inputs) # [M, 224, 224, 3] -> [M, 4096]
# 经过GRU层获取词向量word_emb
word_emb = self.BiGRU_layer1(text_inputs) # [L, T, k] -> [L, T, 2k]
# 经过self_attention得到句向量seq_emb
input = [word_emb, mask] # [L, T, 2k] & [L, T]
seq_emb = self.word_self_attention(input) # [L, T, 2k] -> [L, 2k]
# 经过GRU层提取语义
input = tf.expand_dims(seq_emb, axis=0) # [1, L, 2k]
seq_emb = self.BiGRU_layer2(input) # [1, L, 2k] -> [1, L, 4k]
# 经过img_seq_attention得到M个文档向量doc_emb
image_emb = tf.expand_dims(image_emb, axis=0) # [1, M, 4096]
mask = tf.argmax(mask, axis=1) # [L, ]
mask = tf.expand_dims(mask, axis=0) # [1, L]
input = [image_emb, seq_emb, mask]
doc_emb = self.img_seq_attention(input) # [1, M, 4k] M个文档向量表示
# 经过self_attention得到最终的文档向量
mask = tf.ones(shape=[1, doc_emb.shape[1]]) # [1, M],全为非0值,因为该注意力无需mask
input = [doc_emb, mask]
D_emb = self.doc_self_attention(input) # [1, 4k]
# output layer
output = self.output_layer(D_emb) # [1, class_num]
return output
到此,VistaNet 模型的整体搭建就结束了。
番外篇:
本没打算对该模型进行复现,因为一直没有找到对应的数据集,搭好了也没法调试。但应广大小伙伴的需求,还是复现了一下。然后自己生成虚拟样本调试了一番,顺利跑通了该模型。
model = VistaNet()
# 随机生成一条样本
image_input = np.random.rand(6, 224, 224, 3) #6个评论图像
text_input = np.random.rand(50, 128, 256) #包含50句话,每句话128个词的文档
mask = np.random.rand(50, 128) #50句话中每个词的padding位置
input = [image_input, text_input, mask]
pre = model(input) # [1,class_num] class_num个类别的输出
输入数据格式说明: (一条样本)
- image_input:M个图像数据需要处理成四维张量格式 [M,width, height, channel],因为每条样本的 M可能不同,所以暂时无法批量的作为 dataset 输入模型,只能一次输入一个样本(有好方法的小伙伴记得教教我);
- text_input:一个文档需要先分句,然后对每句进行分词,得到三维张量 [L, T,K],L为最大句子数,T为句子的最大单词数,K为词向量维度;
- mask:表示一个文档被 padding 的位置矩阵,形状为 [L,T]。
写在最后
需要复现的小伙伴可参考这份代码。希望看完此文的你,能够有所收获~
有问题欢迎评论or私信,也可以去我的知乎,我在那更活跃一些。