attention引导的全景分割统一网络(AUNet)

Abstract
本文研究了全景分割这一最近提出的任务, 即在实例级对前景 (FG) 对象进行分割, 在语义层面对背景 (BG) 内容进行分割。现有的方法大多分别处理这两个问题, 但在本文中, 我们揭示了它们之间的潜在关系, 特别是 FG 对象提供了补充线索, 以帮助 BG 理解。我们的方法名为 "关注引导统一网络" (AUNet), 它是一个统一的框架, 同时具有 FG 和 BG 分割的两个分支。在 BG 分支中增加了两个关注源, 即 RPN 和 FG 分割掩码, 分别提供对象级和像素级的关注。我们的方法推广到不同的主干, 在 FG 和 BG 分割中都有一致的精度增益, 并在 MS COCO (46.5 pq) 和 Cityscapes (59.0 PQ) 基准中sets new state-of-the-arts
1. Introduction
场景理解是计算机视觉中一项基本而又具有挑战性的任务, 它对自主驾驶和机器人等其他应用产生了巨大的影响。场景理解的经典任务主要包括目标检测、实例分割和语义分割。本文考虑了最近提出的一个名为全景分割 [23] 的任务, 该任务旨在查找实例级别的所有前景 (FG) 对象 (named things, 主要包括可计数的目标, 如人员、动物、工具等), 同时分析背景 (BG) 内容 (named stuff, 主要包括无定形区域和/或材料, 如草, 天空, 道路等) 在语义层面上。基准算法 [23] 和 MS-COCO 全景挑战优胜者 [1] 通过直接结合 FG 实例分割模型 [15] 和 BG 场景解析 [45] 算法来处理此任务, 这些算法忽略了潜在的关系, 未能借用丰富的内容事物和事物之间的上下文提示。
本文提出了一个概念上简单统一的全景分割框架。为了促进 FG 事物和 BG 内容之间的信息流, 我们将传统的实例分割和语义分割网络结合起来, 形成了一个具有两个分支的统一网络。此策略可立即提高分割精度, 并提高计算效率 (因为可以共享网络主干)。这意味着全景分割受益于 FG 对象和 BG 内容提供的互补信息, 为我们的方法奠定了基础。
更进一步, 我们探讨了将更高级别的视觉线索 (即超越从backbone末端提取的特征) 整合到更准确的分割中的可能性。这是通过两个基于注意力的模块分别在对象级别和像素级别工作来实现的。对于第一个模块, 我们指的是regional proposals(区域建议), 每个建议都表示可能的 FG 内容, 并调整相应区域被视为 FG 项和 BG 项的概率。对于第二个模块, 我们提取 FG 分割掩码, 并使用它来细化 FG 事物和 BG 事物之间的边界。在深度网络的背景下, 这两个模块分别称为建议注意模块 (Proposal Attention Module PAM) 和掩码注意模块 (Mask Attention Module MAM), 它们是作为 FG 和 BG 分支之间的额外连接实现的。在 MAM 中, 设计了一个名为 Roiupsample的层, 用于定义固定形状 FG 掩码中像素与相应feature map之间的精确映射函数。实际上, 所有额外的连接都从 FG 分支转到 BG 分支, 主要是因为观察到 FG 分割往往更准确。此外, BG stuff, 虽然是由 FG 的东西细化, 也提供反馈通过梯度。因此, FG 和 BG 分割精度都有了很大的提高。
名为 "关注引导的统一网络" (AUNet) 的整体方法可以轻松地实例化到各种网络主干, 并以端到端方式进行优化。我们在两个流行的细分基准中评估 AUNet, 即 MS-COCO [28] 和 Cityscapes [8] 数据集, 并声明 PQ 方面的最先进的性能, 这是一个集成了事物和事物准确性的标准指标 [23]。此外, 通过广泛的烧蚀研究 4.2(不知道是什么), 验证了联合优化和两个基于注意的模块所带来的好处。
这项研究的主要贡献是为 FG 和 BG 分割提供一个简单而统一的框架, 在 MSCOCO [28] 和 Cityscapes [8] 数据集中达到最高性能。此外, 本工作还研究了 FG 对象和 BG 内容提供的补充信息。虽然全景分割是研究这一主题的自然场景, 但它的应用在于更广泛的视觉任务。我们的解决办法----AUNet----是在这一领域的初步探索, 但我们期待着朝着这一方向作出更多努力。
(根据上下文理解,这里领域指的是场景理解,作者做全景分割可能是以帮助场景理解为目的)
本文的其余部分按如下方式进行了组织。第2节简要回顾了相关工作。第3节阐述了拟议的 AUNet, 包括两个以注意为基础的模块。在第4节中显示了实验之后, 我们在第5节结束了这项工作
2. Related Work
传统的基于深度学习的场景理解研究往往集中在前景或背景目标 [15, 45] 上。最近, 在目标检测 [13, 14, 34] 和实例分割 [9, 15, 25, 31] 的快速进展, 使其能够在更精细的级别上实现对象定位和分割。同时, 语义分割 [5, 6, 33, 45] 的发展提高了场景解析的性能。尽管这些任务的有效性, 但它们的分离导致了实例分割中缺乏上下文提示, 以及在语义分割方面带来的个体混乱。为了弥补这一差距, 最近, 研究人员提出了一个新的任务, 称为泛视分割 [23], 旨在同时完成这两个任务 (FG 实例和 BG 语义分割)。
全景分割: 在 [23] 中, 作者结合实例和语义分割模型, 给出了全景分割的基准。后来, 在初始化语义结果的基础上提出了一种弱监督的方法 [24], 并设计了一种端到端方法 [11], 将 FG 和 BG 线索结合起来。然而, 他们的表现远远低于基准 [23]。与它们不同的是, 我们提出的 AUNet 在端到端框架中实现了最佳性能。此外, 我们还建立了基于建议的实例和基于 FCN 的语义分割之间的联系。最近的工作包括 [22, 29, 40]。
实例分割: 实例分割旨在区分同一对象的不同实例。解决这一任务的方法主要有两种, 即proposal-based method和segmentation-based methods。Proposal-based的方法, 在准确的区域提案的帮助下, 往往取得了更高的性能。最近例子包括 MNC [9], FCIS [25], 面具 RCNN [15] 和 PANet [31]。此外, segmentation-based的方法聚合像素级提示, 将实例与语义分割 [2、26、32] 或深度排序 [44] 结果结合起来。
语义分割: 随着 FCN [33] 等所谓编码解码网络的发展, 语义分割技术取得了快速进展 [5, 6, 45]。在分割过程中, 捕获上下文信息起着至关重要的作用, 为此提出了各种方法, 包括用于deeplab [5, 6] 的多尺度上下文的 ASPP、用于全局上下文的 DenseASPP [41] 和收集上下文prior的 PSPNet (这个方法不懂)[45]。还努力使用attention模块进行空间特征选择, 如 [12、42、43], 下文将详细讨论这些模块。
Attention-based Modules: 基于附件的模块已广泛应用于视觉任务, 包括图像处理、视频理解和对象跟踪 [7、19、37、46、47]。特别是,SENet [19] formulated channel-wiserelationships via an attention-and-gating mechanism, nonlocal network [37] bridged self-attention for machine translation [36] to video classification using non-local filters. 。在场景理解的范围内, [42] 和 [43] 通过通道关注操作聚合了全局上下文信息以及类相关特征。最近, [12] 分别采用self-attention和channel attention的方法对空间的远程上下文和信道维度进行建模。在这项工作中, 我们建立了前景的东西和背景的东西在全景分割与一系列的粗到精细的注意力块之间的关系。

3. Attention-guided Unified Network
3.1. Problem and Baselines
全景分割任务旨在了解一个视图中可见的所有内容, 这意味着必须为图像的每个像素分配一个语义标签和一个实例 ID。为了解决这个问题, 现有的顶级算法 [1, 23] 直接结合了来自不同模型的实例和语义结果, 如mask R-NNN [15] 和 PSPNet [45]。
我们将全景分割的问题,表达为识别和分割所有的 FG things, 并了解所有的 BG stuff。通过这种方式, 我们从两个方面解决了这个问题, 即统一网络中的前景分支和BG分支 (图 2)。在细节上, 给定一个输入图像 x, 我们的目标是生成 FG things结果 YTh 和 BG stuff结果 YSt。因此, 在3.4 节中, 使用融合方法可以直接从 YTh 和 YSt 生成全景分割结果 YPa。如第4.1 节所述, 分割结果的性能通过全景质量 (PQ) [23] 进行评估。为此, 我们首先介绍了我们的全景分割的统一框架。然后, 阐述了我们设计的注意力引导模块中的关键要素, 包括建议注意模块 (PAM) 和掩模注意模块 (MAM)。最后, 我们给出了我们的实现细节。
在这项工作中, 我们将从单独的模型中生成stuff和things的方法视为我们的基线。具体而言, 基线方法给出的结果 YTh 和东西 YSt 分别从单独的模型 MTh 和 MSt。FG 模型 MTh 和 BG 模型 MSt 被赋予了相似的主干 (例如, FPN [27]) 为以下统一的框架。
3.2. Unified Framework
为了bridge the gap between FG things与 BG stuff之间的差距, 我们提出了注意引导统一网络 (AUNet)。与基线方法相比, 提出的 AUNet 通过共享相同的主干将两种模型 (MTh 和 MSt) 融合在一起, 并从并行分支生成 YTh 和 YSt。如图2所示, AUNet 在概念上很简单: 采用 FPN 作为主干, 从不同的尺度中提取判别特征, 并由所有分支共享。
与传统方法 (直接组合在 MTh 和 MSt 中的结果) 不同, 所提出的的 AUNet 使用联合损失函数 L (定义于3.4 节) 对它们进行优化, 并在统一的框架中促进这两个任务。详细地, 我们采用了一个proposal-based的实例分段模块, 在FG分支中生成更精细的掩码 m。而对于BG分支, 轻量级头部被设计为从共享的多尺度特征中聚合场景信息。通过这种方式, 共享主干由 FG things和 BG stuff同时进行监督, 从而促进了特征空间中两个分支之间的连接。为了更明确地建立 FG things和 BG stuff之间的联系, 增加了两个注意模块的来源。我们考虑了 i-th 尺度 BG 特征图与相应的 RPN 特征图之间的粗注意操作, 分别用 Si 和 Pi 表示。注意模块可以表述为 Si ⊗ Pi, 其中 "⊗" 表示注意力操作, 如图2所示。此外,the finer relationship is established by the attention between the processed feature map Spam and the generated FG segmentation mask Proi, which can be formulated as Spam ⊗ Proi。详细信息将在下一节中进行调查。
3.3. Attention-guided Modules
考虑到 FG things与 BG stuff之间的互补关系, 我们引入了从FG分支到BG分支的特征, 以获得更多的上下文提示。从另一个角度来看, 连接两个分支的注意操作也在基于建议的方法和基于 fcn 的方法分割之间建立了联系。为此, 提出了两个空间注意模块, 即proposal注意模块 (PAM) 和mask注意模块 (MAM)。
3.3.1 Proposal Attention Module

RPN第一层先经过3x3的卷积,得到输出的特征图,共享的是这一部分,同时,这一部分输出的与input size大小相同,通道改变为256,也就是说,含有背景信息,但不明显
在经典的两阶段检测框架中, 引入区域建议网络 [34] 给出了预测的二进制类标签 (前景和背景) 和边界框坐标。这意味着 RPN 功能包含丰富的背景信息, 只能从背景分支中的内容注释中获得。因此, 我们提出了一种新的方法来建立 FG 元素和 BG 内容之间的互补关系, 称为建议注意模块 (PAM)。如图3所示, 我们利用 RPN 分支中的上下文提示进行注意操作。在这里, 我们给出了这个过程的详细公式。给定输入要素图 Pi 属于 R Cr x W'' × H'' 从 i-th 比例 RPN 分支, 在 sigmoid 激活之前的 FG 加权映射 Mi 可以公式化为:

其中 f (·; ·) 表示卷积函数, 表示 ReLU 激活函数, Mi 2 R1×W 00×H00 表示生成的 FG 加权映射, wi;1 属于 R C'r x Cr×1×1和 wi;2 属于 R 1×C'r x1x1 表示卷积参数。
为了强调背景内容, 我们将注意加权图 Mi0 公式化为 1-sigmoid (Mi)。然后, i-th 比例激活的要素图 S’i 属于 R Cs x w'' × H'' 可以显示为:

在 [19] 的推动下, 设计了一个简单的背景reweight函数, 以在attention操作后downweight 无用的背景层。我们认为, 它可以改进, 但超出了这项工作的范围。重新加权的要素图 Si'' 属于 R Cs x w'' × H'' 可以生成为:
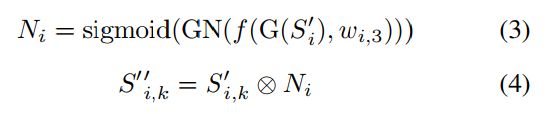
其中 G 和 GN 分别表示全局平均池化和群范数 [38], Ni 属于 R Cs×1×1表示重(chong)量化运算, wi;3 属于 R Cs×Cs×1×1表示卷积参数, S’ i; k 表示 S' i 中的 k-th 像素通道。
在上述 PAM 公式的基础上, 通过attention操作和BG reweight功能, 突出了feature map中的背景区域。它还通过在反向传播过程中增强激活的前景区域的权重来促进things的学习 (参见第4.2 节)
3.3.2 Mask Attention Module
随着 PAM引入上下文的线索, 背景分支更多地关注stuff的区域。然而, RPN 分支的预测粗糙区域缺乏足够的线索来表示精确的 BG。与 RPN 功能不同, 从前景分支生成的 mxm 固定形状掩码编码了更精细的 FG 布局。因此, 我们建议掩码注意模块 (MAM) 进一步建模关系, 如图5所示。因此, 与以前类似的注意操作需要1xw0xh0 形状的 FG 分割掩码。现在, 问题是: 如何从 mxm 掩码重现 W0xh0 形状的 FG 特征图?

Roiupsample: 为了解决大小不匹配问题, 我们提出了一个新的可微化层, 称为 Roiupsample。具体而言, Roiusample的设计类似于 Roialign [15] 的逆过程, 如图4所示。在 Roiupsample中, mxm 掩码 (m 等于14或28在掩码 R-NN) 首先被重塑为相同大小的 RoIs (从 RPN 生成)。然后, 我们利用设计的逆双线性插值计算每个掩码箱中四个定期采样位置 (与 Roialign相同) 的输出要素值, 然后将最终结果作为生成的掩模要素图求和。为了满足双线性插值 [21] 的要求, 在近点得到更多的贡献的情况下, 提出了逆双线性插值的操作:
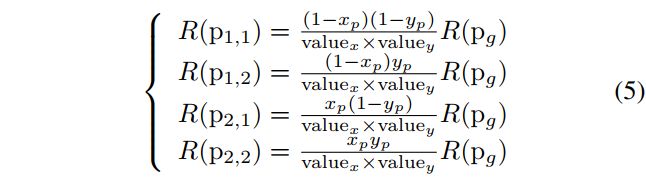
其中 R (pj; k) 表示点 pj; k 在逆双线性插值后的结果, R (pj) 在这里等于输入掩码中相应值的四分之一, 并且归一化权重值, 值定义为:

其中 xp 和 yp 分别表示两个轴上的网格点 pg 和生成的 p1;1 之间的距离, 如图 4(b) 所示。请注意, 使用公式5和 6, mxm 掩码也可以从生成的 w0xh0 特征图中恢复, 并具有正双线性插值
注意操作: 与传统的实例分割任务不同, 利用预测的 FG 掩码, 在像素级中为背景分支提供更多的上下文指导。我们首先使用 Roiupsample将它们聚合到 Cm xw0xh0 要素图中, 如图5所示。然后, 可以生产出更精细的1xw0xh0 激活的 BG 区域, 与 PAM 中的区域相似。随着注意力的引入, FG 掩码也受到语义丢失函数的监督, 这使得场景理解 (无论是对事物还是事物) 都能得到进一步的改善, 如第4.2 节所述。采用了类似的背景重量化函数来聚合有用的突出背景特征。因此, 我们用提出的 PAM 和 MAM 对 FG 事物和 BG 物质之间的互补关系进行了建模。

