第七届工程训练比赛之智能垃圾分类
2021第七届工程训练综合能力竞赛之智能垃圾分类山西省赛区
前言
写在前面:第一次写博客,想把这半年的备赛经历记录下来分享分享给大家,如有错误欢迎大家指正。
比赛成绩:1分23秒(播放宣传片到满载结束)(山西省赛区)
基本配置:
1.硬件:STM32 双直流电机驱动 亚博K210开发板 maixK210淘宝链接 OV5640摄像头 显示屏 996(995)舵机 稳压模块
2.软件:yolov3 maixpyIDE kflash-gui(下载固件)
3人员:山西省太原工业学院大二本科生三人团队(两机械一电控)本人电控
比赛简介
山西省赛与4月26日开始,26日晚提交作品,27日上午9:30到11:30训练十种垃圾:小号矿泉水瓶,易拉罐,一号电池,二号电池,五号电池(全为南孚),棉签,烟头,碎瓷片,小西红柿,切割过的胡萝卜(片状)。比赛现场,两组一起进场地比赛,我们组成绩为1分23秒(播放宣传片到满载结束),时间排名第一,文档17分综合排名第二。观看了很多学校的垃圾分类装置,开发板顶配是英伟达,大部分是树莓派或openmv,还有的正点原子精英板。我们的垃圾桶包装也很到位,没有线外露,贴了壁纸,视觉效果还可以,附下图。


心路历程
接到这个项目的时候,刚比完校内赛。那会已经熟练掌握STM32f103。看完赛题之后,就是网上查阅资料,机器视觉,图像分类这些字眼第一次飘进我的大脑。因为没接触过,更是一脸懵。不过还好有电控学长带着,最初确定了方案是openmv+stm32。于是开始研究openmv,就此开启了python的学习之路。在花了两周左右搞出来垃圾识别的时候,发现openmv很烫手(烫手宝1号)而且引脚口很少,满足不了比赛要求。在四川省赛结束后,重新确定方案:树莓派(烫手宝2号)+ stm32。在确定树莓派这段时间,看到一篇博客,对我那会帮助很大。感谢这位博主,让我学会用opencv-python识别自定义物体。学会之后实践识别垃圾,发现根本达不到比赛要求,识别率特别低,基本识别不出来。所以接下来就去老老实实的学习tensorflow去了,顺便进入了树莓派安装各种依赖的时期。树莓派没搞多久,学校放假。带回家研究了几天,想着在树莓派上装pycharm运行代码识别垃圾,但是最终效果很卡很卡,在网上又查阅到用树莓派实现垃圾分类的博客1,也很有帮助。但是因为时间太紧,还有其他原因,最终没能按照这位博主所写的走下来就换了K210。亚博K210的资料很全面但是使用的是C语言,网上开源的关于图像识别的编程语言绝大部分都是python语言。某次不经意间看到B站上的视频,用的K210是maixpy,就想着把他这一套放在我都亚博的开发板上。感谢老天,我成功了!后来才知道两款K210芯片都一样所以可以使用。而且maix的开发板是基于openmv的,所有的资料教程以及maixIpyDE也是基于openmv的IDE。所以,在有之前的openmv基础,很快上手,每天都有大突破。一周左右就能识别自定义垃圾,识别率在80%左右。之后的事情就简单了,训练模型,提高识别率。
K210的使用相关参数
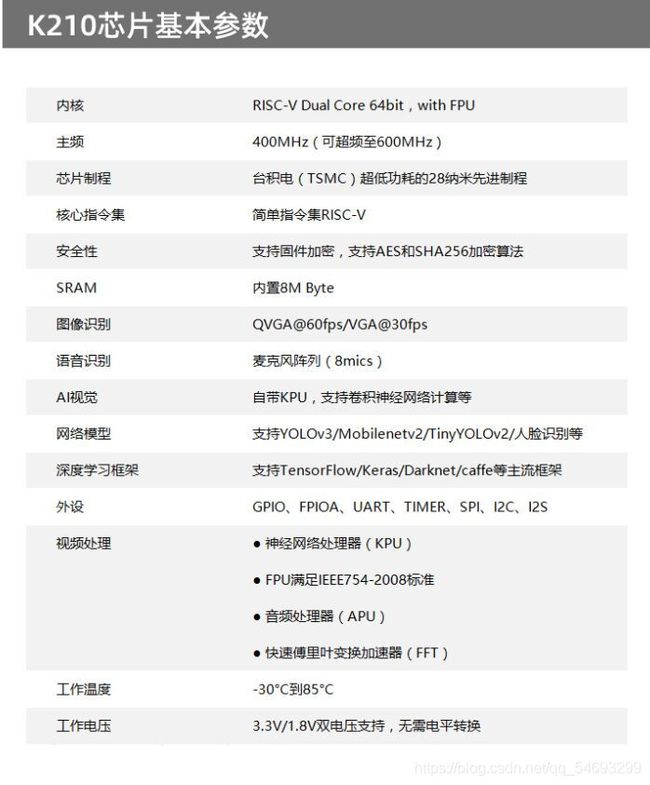


K210maixpy上手教程
K210的摄像头
K210的板载摄像头是ov2640,200万像素,识别视野小,识别倒是可以,但是为了比赛,为了识别小的垃圾,得更换更高像素的摄像头。这里的坑:不要找什么广角摄像头,个人觉得24P引脚的广角摄像头都有畸变,不建议使用,这里推荐使用ov5640摄像头,500万高像素,识别视野相比ov2640更大点。如图所示
ov2640  ov5640
ov5640 
K210数据采集
详情请看此教程
数据采集方法:1.手机拍照格式为1:1,224*224
2.开发板拍照:使用开发板采集数据,用此脚本收集图像(阅读图像收集用法以收集图像)
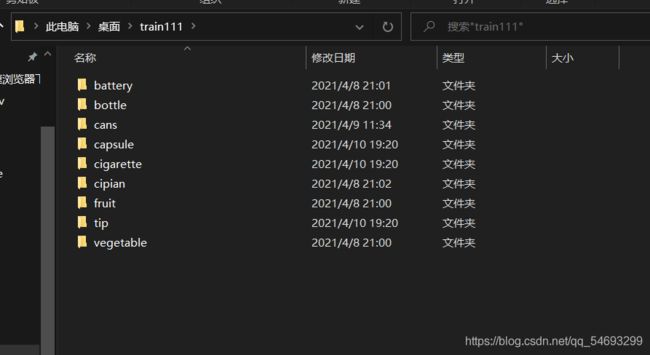
数据集采集文件格式如下:

K210的本地训练
maixpy基础文档写的特别详细,大家都能看懂,主要阐述一下我踩过的坑:
首先,需要一台有 Linux 系统的电脑 如果你的主力系统是 Windows, 你可以用以下系统环境:
- 使用虚拟机,
virtual box或者vmware都可以, 系统推荐安装Ubuntu20.04。 - 或者安装双系统,安装方法请自行搜索学习,或者看双系统安装(博主写的很详细)
- 这里必须说一点,虚拟机不能使用GPU,只能通过双系统使用GPU
- 建议新手先用网站训练:sipeed官网训练
我踩下的坑:装双系统训练模型,因安装Ubuntu20.4双系统找了教程没有跟着博主好好走下去,私自安装,导致覆盖安装了Ubuntu,把window系统抹掉了/(ㄒoㄒ)/~~又花了好多时间重装了window系统。这里感谢队友贡献他们的电脑(我在他们电脑上装的Ubuntu哈哈哈哈 鞠躬!)所以,装双系统一定要小心谨慎!建议先装vmware虚拟机上进行本地训练:VMware虚拟机安装教程 ,vmware安装Ubuntu20.04教程,建议给Ubuntu分40G内存! 亲测内存大训练快!(40G够够的)记得弄个共享文件夹方便。初次接触,建议先使用 CPU 进行训练,环境安装会简单很多, 文档教程中讲 CPU 训练的方法很详细我在这里不做赘述。接下来的使用方法摘抄于仓库的 README, 如果有出入, 以仓库的README为准,注意分辨。
CPU本地训练教程
如下是本地训练部分代码
import os
curr_dir = os.path.abspath(os.path.dirname(__file__))
# kmodel convert
# "/ncc/ncc" # download from https://github.com/kendryte/nncase/releases/tag/v0.1.0-rc5
ncc_kmodel_v3 = os.path.join(curr_dir, "..", "tools", "ncc", "ncc_v0.1/ncc")
sample_image_num = 20 # convert kmodel sample image (for quantizing)
# train
allow_cpu = True # True
# classifier
classifier_train_gpu_mem_require = 2*1024*1024*1024
classifier_train_epochs = 70
classifier_train_batch_size = 5
classifier_train_max_classes_num = 15
classifier_train_one_class_min_img_num = 40 # 一个类别中至少需要的样本数量
classifier_train_one_class_max_img_num = 2000 # 一个类别中最多需要的样本数量
classifier_result_file_name_prefix = "maixhub_classifier_result"
# detector
detector_train_gpu_mem_require = 2*1024*1024*1024
detector_train_epochs = 40
detector_train_batch_size = 5
detector_train_learn_rate = 1e-4
detector_train_max_classes_num = 15 # 最多能训练多少类
detector_train_one_class_min_img_num = 100 # 一个类别中至少需要的样本数量
detector_train_one_class_max_img_num = 2000 # 一个类别中最多需要的样本数量
detector_result_file_name_prefix = "maixhub_detector_result"以下为本地训练截图:

本地训练的好处:classifier_train_epochs = 70(迭代次数可以修改,网站上模型训练默认迭代40次)数据集训练压缩包没有20MB限制!这就很牛批,我最初担心的要是比赛十多种垃圾会不会因为数据集压缩包太大无法训练,如此看来是多余的。最主要的好处就是,不用排队,网站训练得排队等候服务器,每次只能一个用户训练,少则半小时四十分钟,多则一两小时,排队多了甚至一天都有可能。本地训练随时可以,我的数据集2000左右基本上训练时间在四十分钟左右(vmware虚拟机训练),这也是我搞本地训练的初衷。
K210训练注意事项
- 本地训练数据集虽然没有网站上那样要求小于20MB,但是数据集越多,训练时间越长。而且也不是训练时间久效果就越好,一般迭代次数在60左右,当loss降到0.1左右,accuracy为0.9左右时模型效果还算可以。
- 本地训练也要求每张数据集格式为224*224。
- 自定义物体识别本地训练时,要求各物体数据集差别明显,背景丰富,各物体数据集数量建议200+。
- 同一数据集每次训练出来的模型效果都不一样。
- 拍照采集数据集时,建议保证光亮环境。
K210的垃圾分类关键代码:
部分代码如下,如有需要源代码可评论区@我+qq邮箱
if plist.index(pmax)==4: #other 其他垃圾
if pmax >= 0.9: #准确率
if a == 3:
time.sleep_ms(10)
write_str = ('page ji') # 发送报警错误信号给显示屏 IO15
print("send = ", write_str)
uart_A.write(write_str)
uart_A.write(s)
a += 1
break;
Servo_2(S2,55) #舵机2转动
time.sleep_ms(200)
Servo_1(S1,55) #舵机1转动
write_str = ("t%d.txt=\"other rubbish 1 ok!\"" %(a)) #发送垃圾种类给显示屏
uart_A.write(write_str)
uart_A.write(s)
write_str = ("wav0.en=1")
uart_A.write(write_str)
uart_A.write(s)
a+=1
time.sleep_ms(440) #舵机归位
Servo_1(S1,-7)
Servo_2(S2,0)
time.sleep_ms(600)
break;
if plist.index(pmax)==3: #kitchen 厨余垃圾
if pmax >= 0.9:
if a == 3:
time.sleep_ms(10)
write_str = ('page ji') # 发送报警错误信号给显示屏 IO15
print("send = ", write_str)
uart_A.write(write_str)
uart_A.write(s)
a += 1
break;
Servo_1(S1,60)
write_str = ("t%d.txt=\"kitchen rubbish 1 ok!\"" %(a))
uart_A.write(write_str)
uart_A.write(s)
write_str = ("wav0.en=1")
uart_A.write(write_str)
uart_A.write(s)
a+=1
time.sleep_ms(450) #舵机归位
Servo_1(S1,-7)
time.sleep_ms(500)
break;
uart.deinit()
del uart
except Exception as e:
raise e
finally:
if not task is None:
kpu.deinit(task)
if __name__ == "__main__":
try :
labels = [ "Recyclable","background","harmful","kitchen","other"]
main(labels=labels, model_addr="/sd/m.kmodel")
except Exception as e:
sys.print_exception(e)
lcd_show_except(e)
finally:
gc.collect()总结
备赛期间,遇到很多困难,第一次搞图像分类,深度学习,也没有往届的学长的经验。一步步从stm32,到openmv,再到树莓派,以及最后确认的K210,一步步就像拓荒一样,不断发现,踩坑。但是还好有队友陪着,有队长们带着一起往前走,还有家人们的鼓励,一步步克服困难,最终成功登顶!这段日子里,不断的模型训练,无数的熬夜,遭遇瓶颈期,在最艰难的时候我没有放弃,选择迎难而上,即使与队友发生口角,也不会影响我们为比赛的最终目标。怀着一切为了比赛的信念而勇往直前。有些事情,不是看到希望才去坚持,而是坚持了才能看到希望!也谨以此博客致敬一直陪伴熬夜的兄弟们!最后,兄弟们我们国赛清华见!