1.准备工作:
这段时间一直在看jvm调优的内容,苦于没有环境让自己练手,周三下午测试人员说测试后台过于慢,之前一直以为是数据库压力太大的问题,后来连上测试环境,发现xmn=150m,新生代只分配了150m,而整个堆最大为2g,然后和运维同事沟通了,建议设置成1G,项目再打包,后台页面基本都秒开,虽然是个测试环境小小的调优,还是比较开心的哈.
测试环境毕竟是测试环境,因为开发没有权限,有东西想改还是要和运维沟通,这几天拿idea试试手,把idea调优下.先说下我的配置,E5 2660 ,8核16线程,16G内存,120G ssd,cpu虽然线程数比较多,但是主频比较低,只有2.2g,idea在我电脑上启动大概需要20s左右.其实前几天就着手做这个事情,但是一直没有办法统计出idea具体的启动时间,周志明大佬在深入jvm一书中是用的eclipse调优,eclipse插件似乎把启动时间写入到全局变量中了,idea我找了半天没找到,今天下午突然发现,其实idea在启动的时候会把启动信息写入到日志中,我的位置是在C:\Users\Administrator.IntelliJIdea2018.1\system\log\idea.log,这里面记录了idea启动都做了哪些事情

image
然后我就以app initialzation took作为时间的标准,后面这个13745ms我不知道它咋算出来的,启动时间到这个点输出一个是11667这个时间才对,然后我就以11667作为idea的启动时间来判断.如果是用linux来截取这个时间的话awk命令就够了,做两次管道
grep 'App initialization took' idea.log | awk '{print $4}'|awk -F ']' '{print $1}'
我是windows上跑的这个,然后就开了个pycharm,用python来处理这个时间,为了能够在idea启动的瞬间,就记录这些信息,我把idea配置在了环境变量里,然后用python启动,就是下面的openIdeaAndTools方法,这里顺便吐槽下pycharm,我配完环境变量,idea死活起不来,然后电脑重启下突然就好了,估计它的terminal缓存了系统的环境变量,不知道算不算bug.
#!/usr/bin/env python
# -*- coding=utf-8 -*-
import fileinput
import os
import threading
import time
class MyThread(threading.Thread):
def __init__(self, arg):
super(MyThread, self).__init__()
self.arg = arg
def run(self):
os.system(self.arg)
def getIdeaStartTime(logPath):
# 获取idea的启动时间
for line in fileinput.input(logPath):
if 'App initialization took' in line:
print(line.split('[')[-1].split(']')[0])
def openIdeaAndTools():
# 这里调用命令是阻塞执行,所以开启线程异步执行
t1 = MyThread('idea64.exe ')
t1.start()
# 防止idea未启动先执行了下面的代码
time.sleep(0.1)
try:
# 调用jps命令
pid = os.popen("jps")
for l in pid:
# 因为idea启动后,jps输出的只有一个vmid,后面没有类名,以此来判断该进程是idea的
id = l.split(' ')[0]
info = l.split(' ')[1]
# 我这台机器上还跑了pycharm,pycharm后面同样没有类名,就把pycharm的vmid去掉
if not info.strip() and int(id) != 1200:
print("idea的Id为" + id)
# 调用jstat
t4 = MyThread('jstat -gcutil ' + id + ' 1000 3')
t4.start()
# 调用jconsole
t2 = MyThread('jconsole ' + id)
# 调用jvisualvm
t3 = MyThread('jvisualvm')
t3.start()
t2.start()
finally:
pid.close()
if __name__ == "__main__":
# getIdeaStartTime(logPath = "C:\\Users\\Administrator\\.IntelliJIdea2018.1\\system\\log\\idea.log")
openIdeaAndTools()
2.未优化前:
首先说下idea的默认配置,在help-edit custom vm options可以看到,配置如下:
-Xms128m //最小堆128
-Xmx750m //最大750
-XX:ReservedCodeCacheSize=240m //代码缓存
-XX:+UseConcMarkSweepGC //使用parnew+cms垃圾回收
-XX:SoftRefLRUPolicyMSPerMB=50 //和soft引用有关
-ea
-Dsun.io.useCanonCaches=false
-Djava.net.preferIPv4Stack=true
-XX:+HeapDumpOnOutOfMemoryError //内存溢出dump出快照
-XX:-OmitStackTraceInFastThrow //抛出堆栈异常
整个的设置还是比较少的,经过多次测试,idea的启动时间大概在18s左右,jstat信息如下(只截取了最后一次测试的前18s)
idea的Id为4440
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 100.00 63.01 1.64 94.90 83.95 1 0.011 0 0.000 0.011
0.00 100.00 61.75 16.45 95.42 83.95 3 0.067 0 0.000 0.067
100.00 0.00 28.84 22.12 94.73 83.02 4 0.106 0 0.000 0.106
100.00 0.00 68.97 22.12 94.73 83.02 4 0.106 0 0.000 0.106
0.00 100.00 30.26 31.35 96.83 93.83 5 0.117 1 0.005 0.122
100.00 0.00 0.00 35.89 97.20 94.96 6 0.131 2 0.027 0.158
90.56 0.00 10.54 38.82 97.53 95.00 8 0.141 2 0.027 0.168
100.00 0.00 68.57 46.48 97.53 95.04 10 0.165 2 0.027 0.192
0.00 97.85 22.65 51.15 97.05 92.71 11 0.175 2 0.027 0.202
0.00 100.00 73.74 60.28 97.18 94.92 13 0.225 2 0.027 0.252
0.00 100.00 91.61 60.28 97.18 94.92 13 0.225 2 0.027 0.252
100.00 0.00 4.12 64.82 97.41 93.94 14 0.235 2 0.027 0.262
100.00 0.00 12.22 64.82 97.41 93.94 14 0.235 2 0.027 0.262
100.00 0.00 71.19 64.82 97.41 93.94 14 0.235 2 0.027 0.262
0.00 100.00 43.52 78.72 96.97 92.43 17 0.315 3 0.029 0.343
0.00 100.00 6.02 74.14 95.99 91.92 19 0.341 5 0.053 0.395
100.00 0.00 35.30 67.15 95.24 90.23 20 0.370 6 0.092 0.462
100.00 0.00 35.64 78.42 94.32 87.14 22 0.419 7 0.094 0.512
这18s中可以看出YGC(也就是minor gc)发生了22次,共耗时0.419s,而FGC总共发生了7次,总耗时0.094s,ygc平均每次时间为0.019s,而fgc每次为0.013.
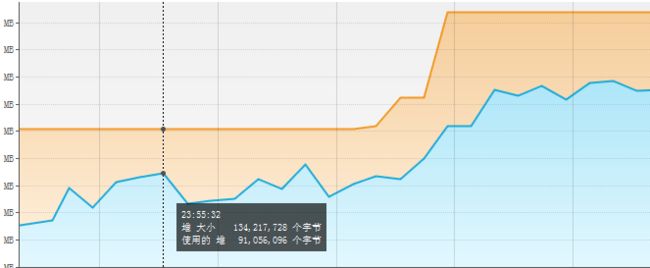
image
从这张图中我们可以看出整个堆的大小先是平稳,后随着使用堆大小的增加逐步变大,而使用堆频繁gc,gc日志如下(前23s,比较长,就直接放服务器了):GC日志:
在0.942s的时候第一次出现了Allocation Failure,分配内存失败,这会导致新生代触发gc,这主要的原因是因为初始堆的大小设置成了128m.好了,有了解决思路,第一步要做的就是先禁掉插件,哈哈,人生就是需要皮一下,idea的log反应出插件的加载似乎是占用了很长一段时间,为了达到优化的效果,先把插件禁掉,在来对gc进行调优.
3.开工:
3.1禁插件
禁掉插件的效果非常明显,测试了三次,时间分别为9296,10034,10363,而最后一次jstat的信息如下:
idea的Id为6512
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 100.00 91.18 1.63 94.81 83.95 2 0.028 0 0.000 0.028
0.00 100.00 49.32 16.38 95.35 83.95 3 0.068 0 0.000 0.068
0.00 100.00 50.65 16.38 95.35 83.95 3 0.068 0 0.000 0.068
100.00 0.00 29.37 21.33 94.72 85.34 4 0.089 0 0.000 0.089
100.00 0.00 49.98 21.33 94.72 85.34 4 0.089 0 0.000 0.089
100.00 0.00 90.62 21.33 94.72 85.34 4 0.089 1 0.009 0.099
0.00 100.00 45.10 32.07 97.56 94.05 5 0.112 1 0.009 0.121
100.00 0.00 79.42 36.54 97.22 95.07 6 0.128 2 0.035 0.163
90.65 0.00 92.93 39.97 97.63 95.09 9 0.169 2 0.035 0.204
100.00 0.00 62.49 47.90 97.69 95.15 10 0.195 2 0.035 0.230
10s内发生了10次ygc,2次fgc,其实说实话,这样的性能完全很好了,但是本着这是一篇调优的文章,有点参数还是要改改,看看效果,首先调整的就是整个堆的大小.
3.2调整堆的大小
启动的时候频繁出现了allocation failure,这是因为堆的初始大小过小,导致新生代的内存过小,所以,先设置了以下参数:
-Xms2048m
-Xmx2048m
-Xmn1600m
堆的大小不在动态调整,而是固定在了2g,而新生代则直接分配了1600m,这一次,启动时间为7s,jstat信息如下,前12s:
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 16.00 0.00 17.24 19.25 0 0.000 0 0.000 0.000
0.00 0.00 24.00 0.00 17.24 19.25 0 0.000 0 0.000 0.000
0.00 0.00 32.00 0.00 17.24 19.25 0 0.000 0 0.000 0.000
0.00 0.00 36.00 0.00 17.24 19.25 0 0.000 1 0.101 0.101
0.00 0.00 46.00 0.00 17.24 19.25 0 0.000 1 0.101 0.101
0.00 0.00 54.00 0.00 17.24 19.25 0 0.000 1 0.101 0.101
0.00 0.00 66.00 0.00 17.24 19.25 0 0.000 1 0.101 0.101
0.00 0.00 70.00 0.00 17.24 19.25 0 0.000 1 0.101 0.101
0.00 0.00 78.00 0.00 17.24 19.25 0 0.000 2 0.101 0.101
0.00 0.00 90.00 0.00 17.24 19.25 0 0.000 2 0.258 0.258
0.00 0.00 96.00 0.00 17.24 19.25 0 0.000 2 0.258 0.258
0.00 41.29 20.32 0.00 96.90 94.00 1 0.054 3 0.267 0.321
一直到12s的时候,新生代才出现首次gc,gc日志异常的少,前面一直是cms在做初始标记-并发标记等工作,是在处理老年代内存,前7s只出现了一次老年代的回收,这也说明了大内存对程序的运行帮助那是相当大.
4.246: [GC (CMS Initial Mark) [1 CMS-initial-mark: 0K(458752K)] 471859K(1933312K), 0.1010486 secs] [Times: user=0.16 sys=0.00, real=0.10 secs]
4.347: [CMS-concurrent-mark-start]
4.347: [CMS-concurrent-mark: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
4.347: [CMS-concurrent-preclean-start]
4.349: [CMS-concurrent-preclean: 0.002/0.002 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
4.349: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 9.362: [CMS-concurrent-abortable-preclean: 0.256/5.013 secs] [Times: user=13.81 sys=2.18, real=5.01 secs]
9.362: [GC (CMS Final Remark) [YG occupancy: 1022364 K (1474560 K)]9.362: [Rescan (parallel) , 0.1397593 secs]9.502: [weak refs processing, 0.0000532 secs]9.502: [class unloading, 0.0081261 secs]9.510: [scrub symbol table, 0.0068646 secs]9.517: [scrub string table, 0.0007781 secs][1 CMS-remark: 0K(458752K)] 1022364K(1933312K), 0.1575112 secs] [Times: user=1.06 sys=0.00, real=0.16 secs]
9.520: [CMS-concurrent-sweep-start]
9.520: [CMS-concurrent-sweep: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
9.520: [CMS-concurrent-reset-start]
9.523: [CMS-concurrent-reset: 0.003/0.003 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
12.028: [GC (Allocation Failure) 12.028: [ParNew: 1310720K->67643K(1474560K), 0.0544422 secs] 1310720K->67643K(1933312K), 0.0545925 secs] [Times: user=0.51 sys=0.06, real=0.06 secs]
12.083: [GC (CMS Initial Mark) [1 CMS-initial-mark: 0K(458752K)] 106973K(1933312K), 0.0083509 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
12.091: [CMS-concurrent-mark-start]
12.091: [CMS-concurrent-mark: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
12.091: [CMS-concurrent-preclean-start]
12.094: [CMS-concurrent-preclean: 0.003/0.003 secs] [Times: user=0.16 sys=0.01, real=0.00 secs]
12.095: [CMS-concurrent-abortable-preclean-start]
16.748: [CMS-concurrent-abortable-preclean: 4.303/4.653 secs] [Times: user=32.20 sys=1.31, real=4.65 secs]
16.748: [GC (CMS Final Remark) [YG occupancy: 737368 K (1474560 K)]16.748: [Rescan (parallel) , 0.0331714 secs]16.782: [weak refs processing, 0.0000574 secs]16.782: [class unloading, 0.0177730 secs]16.800: [scrub symbol table, 0.0229479 secs]16.823: [scrub string table, 0.0011784 secs][1 CMS-remark: 0K(458752K)] 737368K(1933312K), 0.0792557 secs] [Times: user=0.48 sys=0.00, real=0.08 secs]
16.828: [CMS-concurrent-sweep-start]
16.828: [CMS-concurrent-sweep: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
16.828: [CMS-concurrent-reset-start]
16.829: [CMS-concurrent-reset: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
21.380: [GC (Allocation Failure) 21.380: [ParNew: 1378363K->124879K(1474560K), 0.0719474 secs] 1378363K->124879K(1933312K), 0.0721093 secs] [Times: user=0.53 sys=0.08, real=0.07 secs]
23.844: [GC (Allocation Failure) 23.845: [ParNew: 1435599K->78246K(1474560K), 0.2064758 secs] 1435599K->139746K(1933312K), 0.2066017 secs] [Times: user=1.06 sys=0.03, real=0.21 secs]
3.2 新生代调优
为了能够说明某些问题,我把参数又调回了初始参数,因为如果用上面的参数继续跑,基本没法调了,用原始参数对新生代进行调优,在此首先需要介绍下parnew收集器.
3.2.1 parnew介绍
parnew是作为新生代的垃圾回收器,当然也就采用了复制的算法,首先进行可达性分析,stop the world,然后再进行垃圾回收,将eden和s0的数据复制到s1当中去,它和serial的区别就在于parnew是多线的,然后关于parnew的文档,很可惜的是我在oracle官网上没有找到,全是介绍g1,cms和parallel scavenge的,但是官网给出的常见问题列表中有个问题比较有意思,地址, What is the Parallel Young Generation collector (-XX:+UseParNewGC)?官网的回复是parNew和parallel表现出来的东西很像,但是在内部实现上不一样,也就是说关于运行的机制大都差不多,毕竟都是并行的,但是在代码实现上差很多,还有一个不同点就是parnew是能和cms搭配使用的,而parallel不行.
3.2.2调优参数
然后我就用了初始的vm参数中又加了几个参数,(jvm的参数值介绍,官网地址)
第一个参数是-Xmn400m,分配给新生代400m的内存,另外固定住堆的大小为750M,防止因堆的大小不够用而频繁gc.
第二个是-XX:ParallelGCThreads,这个参数用于调整线程数,在我机器上默认是13个
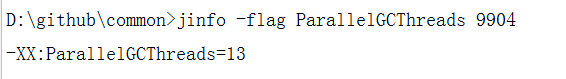
image
第三个是-XX:+ScavengeBeforeFullGC,minor gc优先于fgc,这样的好处就是往往会存在着新生代的对象持有老年代的引用(所以老年代的gc,通常会伴随着fgc),这样在fgc之前先清理掉一部分年轻代对象,会减少可达性分析的成本(在本次实验中,似乎没有展示出优势,fgc次数比较少).
-Xms750m
-Xmx750m
-Xmn400m
-XX:ParallelGCThreads=20
-XX:+ScavengeBeforeFullGC
3.2.3调优结果
这一次启动时间9s,然后看下前9s的jstat信息:
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 28.00 0.00 17.24 19.25 0 0.000 0 0.000 0.000
0.00 0.00 50.00 0.00 17.24 19.25 0 0.000 0 0.000 0.000
0.00 0.00 52.00 0.00 17.24 19.25 0 0.000 0 0.000 0.000
0.00 0.00 60.00 0.00 17.24 19.25 0 0.000 0 0.000 0.000
0.00 0.00 64.00 0.00 17.24 19.25 0 0.000 0 0.000 0.000
0.00 0.00 68.00 0.00 17.24 19.25 0 0.000 0 0.000 0.000
0.00 0.00 76.00 0.00 17.24 19.25 0 0.000 0 0.000 0.000
0.00 0.00 84.00 0.00 17.24 19.25 0 0.000 1 0.089 0.089
0.00 66.86 5.20 0.00 96.69 92.35 1 0.025 1 0.089 0.115
0.00 66.86 33.40 0.00 96.69 92.35 1 0.025 1 0.089 0.115
由上面结果可得知,9s中共发生1次ygc,这我觉得益于-Xms750m,-Xmx750m,-Xmn400m,将新生代的内存大小固定在了400m,而减少了频繁的gc.
3.2.4parnew gc日志解读
然后这里顺便解读下gc的日志,关于parnew的:
9.399: [GC (Allocation Failure) 9.399: [ParNew: 327680K->27386K(368640K), 0.0253901 secs] 327680K->27386K(727040K), 0.0255930 secs] [Times: user=0.06 sys=0.06, real=0.03 secs]
9.399代表项目启动时间,Allocation Failure代表gc的原因,因为内存分配失败,ParNew代表使用的ParNew算法,327680K->27386K(368640K)代表,新生代回收前->新生代回收后(整个新生代大小),327680K->27386K(727040K)代表,整个堆回收前->整个堆回收后(整个堆的大小),0.0255930s代表此次垃圾回收的时间,[Times: user=0.06 sys=0.06, real=0.03 secs] 代表用户线程执行的时间,系统线程执行的时间,总共耗时,因为用户线程和系统线程并行执行,所以总耗时往往比user+sys时间要小.
3.3 老年代调优
3.3.1 cms介绍
老年代主要用的是cms垃圾回收器,使用的是标记-清除算法,正如之前所说的,major gc时因为存在老年代持有新生代的引用,所以会扫描整个堆而发生fgc,另外,因为标记-清除算法会产生碎片,当老年代的内存足够分配一个对象,却因内存不连续时,这时往往也会发生fgc,下面就简单介绍下cms文章原文地址,CMS官方介绍
cms整个工作过程总共分为这几个步骤:
1.初始标记,这一阶段主要是通过gc root进行可达性分析,找到直接关联的对象,这是需要stw.
2.并发标记,由第一阶段标记出的gc信息出发,追踪整个堆的对象信息,将所有活着的对象进行标记,因为是并发执行,所以没有太多的开销
3.并发预清理,此阶段主要是为了减少重标记的时间,标记新生代晋升的对象,新分配到老年代的对象以及在并发阶段被修改的对象,重新标记需要全量扫描整个堆大小(存在年轻代关联老年代的引用,所以需要扫描整个堆),但是如果在并发预清理之后,重标记之前做一次minor gc(也就是类似于之前ScavengeBeforeFullGC)的功能,则能降低重标记的时间.所以它有个子阶段.
3.1 可中断的并发预清理,这一阶段主要的工作就是能够在remark阶段之前产生一次minor gc,由两个参数控制CMSScheduleRemarkEdenSizeThreshold,CMSScheduleRemarkEdenPenetration,默认值分别是2M,50%,第一个代表当预清理完成之后,eden区域大于这个值时,开启可中断的预清理,直到eden空间使用率达到50%则中断,并发预清理期间执行时长 由CMSMaxAbortablePrecleanTime = 5s 这个参数控制,意为并发预清理执行时长如果有5s了,那无论有无minor gc,有无达到50%,都停止并发预清理,进入重标记阶段,如果没有发生minor gc,则可由CMSScavengeBeforeRemark参数,使并发预清理后,remark之前强制执行一次minor gc(这会造成重标记时间减短,但minor gc是需要stw.所以使用还是要权衡)
4.重标记:会扫描新生代和老年代,日志中提现为Rescan(多线程),这个因为前面做了很多工作,所以停顿时间较少
5.并发清理:并发清理无效对象
6.重置:cms清除内部状态.为下次回收准备
整个流程大致如此,这其中有几个点需要说明下:
cms是如何识别老年代对象引用的?这里需要介绍下card table,card table其实就是一个数组,每个位置存储的是一个byte,cms将老年代空间分为512bytes的快,card table每个元素对应一个块,并发标记时.如果某个对象的引用发生了变化,就标记该对象所在的快为 dirty card,并发预清理会重新扫描该块.将该对象引用的对象标记为可达,如图所示:
初始状态:
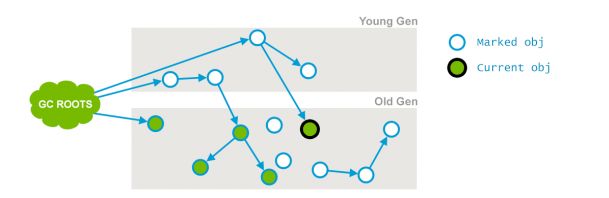
image
随后老年代引用发生变化,对应的块变为dirty card:
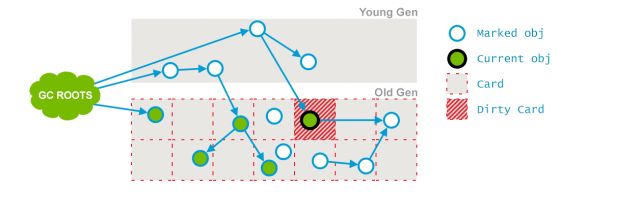
image
紧接着并发预清理,重新扫描修改后的引用,将其设置为可达:
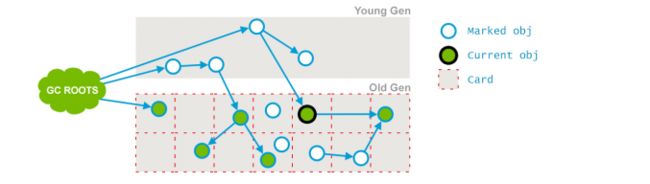
image
对于老年代持有新生代的引用,minor gc是如何识别的?当有老年代引用新生代,对应的card table 被标识为相应的中(就是card table里面byte的8位,约定好每一位的含义,以此来区分)所以minor gc通过扫描card table就可以识别老年代引用新生代.
何为浮动垃圾?当并发预清理之时,用户线程还在跑着,此时产生的垃圾只能下次回收,这一部分垃圾叫浮动垃圾.CMSInitiatingOccupancyFraction=n这个参数控制着老年代使用的比例达到n时,才开始垃圾回收,设置过低会造成老年代频繁的垃圾回收,设置过高会导致无法分配内存空间,会出现Concurrent Mode Failure,从而导致cms使用备份serial old算法清除老年代,从而产生更长的stw.
何为动态检查机制?UseCMSInitiatingOccupancyOnly,cms根据历史,预测老年代需要多久填满以及进行一次回收,老年代使用完之前,cms会根据预测进行gc.
cms如何碎片整理?UseCMSCompactAtFullCollection这个参数,就是进行fgc时,进行碎片整理,但是会造成stw时间变长,CMSFullGCsBeforeCompaction这个参数就是用于设置多少次不压缩的fgc,紧接着来一次碎片整理.
以上算是对cms的一个总结,cms主要是为了解决两个问题,一个是减少stw时间,另一个是减少空间碎片,所以性能性对于其他的一些老年代垃圾回收还是比较优秀的.
3.3.2 cms调优
不知道大家注意到没有,第一次jstat信息老年代的使用空间几乎没有怎么使用,但是依旧是发生了fgc,用jstat -gccause可以看到gc原因,如下:
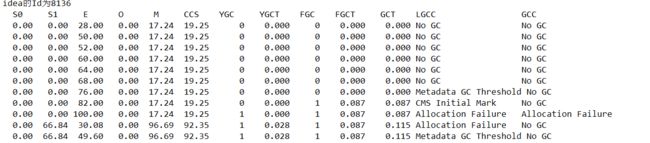
image
我们可以看到出现了Meradata GC threshold,jdk1.8取消了永久代,而是用堆外内存meta space来存放这些信息,而meta回收的及其繁琐,尤其是类信息,需要判断整个堆当中是否还有再用的该类的实例,所以这一阶段触发了fgc,而idea默认的MetaspaceSize大小为21M,所以此次对于老年代的调优,先是调大MetaspaceSize=128大小.
3.3.3 调优结果
这一次的效果非常明显,一直到35s才第一次出现fgc,这一次idea的启动时间还是11s,但是从gc信息中,我还是比较满意的,这11s当中只出现了一次ygc,没有出现fgc.
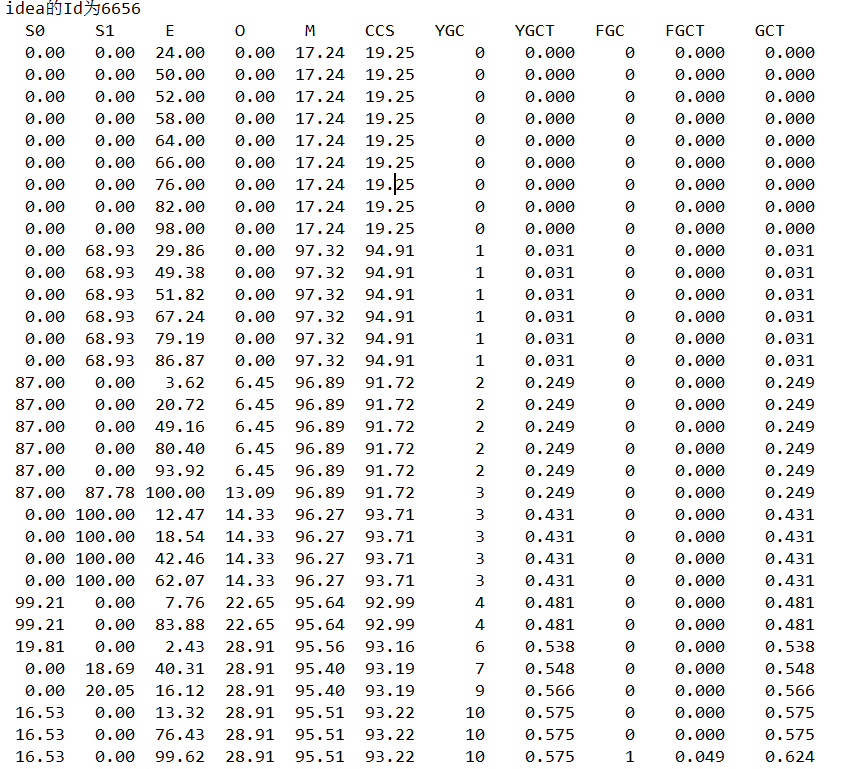
image
3.3.4 cms日志解读
这边主要是以如何分析cms日志为主,截取了一段gc日志:
4.407: [GC (CMS Initial Mark) [1 CMS-initial-mark: 19337K(87424K)] 50969K(126720K), 0.0049123 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
4.407s时初始标记开始,19337k(87424K)->老年代已使用(老年代大小) 50969K(126720K)->整个堆已使用(整个堆大小),0.0049123s共耗时多久,这一阶段是需要stw的.
4.412: [CMS-concurrent-mark-start]
4.425: [CMS-concurrent-mark: 0.012/0.012 secs] [Times: user=0.11 sys=0.01, real=0.01 secs]
这一阶段是并发标记阶段,4.412并发标记开始的标志,4.425开始标记,0.012/0.012因为是并发执行,表示gc线程时间/用户线程时间
4.425: [CMS-concurrent-preclean-start]
4.428: [CMS-concurrent-preclean: 0.003/0.004 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
4.428: [CMS-concurrent-abortable-preclean-start]**
4.658: [GC (Allocation Failure) 4.659: [ParNew: 39296K->4352K(39296K), 0.0110973 secs] 58633K->31757K(126720K), 0.0112153 secs] [Times: user=0.22 sys=0.00, real=0.01 secs]
5.741: [CMS-concurrent-abortable-preclean: 0.925/1.312 secs] [Times: user=4.96 sys=0.20, real=1.31 secs]
这是并发预清理阶段,其中含有可中断的并发预清理,用以让年轻代发生minor gc,里面的信息和上面的类似,不在赘述.
5.741: [GC (CMS Final Remark) [YG occupancy: 23403 K (39296 K)]5.741: [Rescan (parallel) , 0.0075331 secs]5.749: [weak refs processing, 0.0000928 secs]5.749: [class unloading, 0.0064751 secs]5.755: [scrub symbol table, 0.0063506 secs]5.762: [scrub string table, 0.0010179 secs][1 CMS-remark: 27405K(87424K)] 50808K(126720K), 0.0224856 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
这是重标记阶段,是需要stw的,扫描整个堆 YG occupancy: 23403 K (39296 K)表示年轻代当前使用的(年轻代总容量),rescan是其子阶段,开始重新扫描,耗时0.0075331,weak refs processing,第二个子阶段,处理弱引用,class unloading,第三个子阶段,卸载未使用的类,scrub symbol table,第四份子阶段,处理符号表,最后一个子阶段scrub string table,处理string池?(后面两个没太明白,找了下也没找到啥有用信息),CMS-remark: 27405K(87424K),在这个阶段之后老年代占有的内存大小和老年代的容量;
5.764: [CMS-concurrent-sweep-start]
5.787: [CMS-concurrent-sweep: 0.023/0.023 secs] [Times: user=0.09 sys=0.02, real=0.02 secs]
并发清理阶段
5.787: [CMS-concurrent-reset-start]
5.793: [CMS-concurrent-reset: 0.006/0.006 secs] [Times: user=0.08 sys=0.02, real=0.01 secs]
重置一些信息,以便下次垃圾回收.
4.最终的配置信息
-Xms750m
-Xmx750m
-Xmn400m
-XX:MetaspaceSize=128m
-XX:ParallelGCThreads=20
-XX:+ScavengeBeforeFullGC
-XX:ReservedCodeCacheSize=512m
-XX:+UseConcMarkSweepGC
-XX:SoftRefLRUPolicyMSPerMB=50
-XX:+PrintGCDetails
-Xloggc:d:\idea_gc.log
-XX:+PrintGCTimeStamps
-ea
-Dsun.io.useCanonCaches=false
-Djava.net.preferIPv4Stack=true
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow