序列数据的利器——RNN及变体LSTM(tensorflow2.x实现写诗机实例)
文章目录
- 具有序列特征的数据
-
- 序列任务
- 为什么需要RNN
-
- RNN结构
- LSTM
-
- LSTM结构
- 使用LSTM实现一个写诗机
-
- 数据集
- 数据预处理
-
- 从txt中读出数据
- 为词嵌入做准备
- 模型设计
-
- 设计思路
- 模型搭建——前向计算
-
- 词嵌入
- LSTM层
- Output
- 模型搭建——反向传播
-
- 损失函数
- 训练
- 诗词生成
- 测试模型
具有序列特征的数据
文本是一种典型的序列数据,在计算机中往往以字符串的形式体现。想象一下我们阅读文字的步骤:一般是从左到右,过程中不断根据新的读入信息,修改自己的理解。例如有人说:“我今天买了苹果,可好吃了”。我们看到前半句“我今天买了苹果”,我们可能不会知道他买了水果还是手机,当看到“好吃”的时候,我们可以认为他买了水果。
序列任务
机器学习有两大任务类型——分类和回归。如果在序列数据内细分,以NLP为例,说明几个序列数据的任务类型:
- 序列标注
-
分词
机器学习/有/两大/任务/类型 -
词性标注
…
- 分类任务
- 情感分类
- 情感计算
- 主题分类
…
- 序列关系
- 序列相似度计算
- 实体关系判断
…
- 序列生成
- 机器翻译
- 问答系统
- 摘要生成
…
为什么需要RNN
我们可以选择将序列数据全部输入一个网络中,就像CNN处理图片那样。但是我们更希望网络能更好地处理序列中元素之间的相互影响关系,所以只能将序列中的元素按顺序地一步一步处理,并且将每一步的结果按某种方式关联起来。于是我们可以在全连接网络的基础上,在相邻的step之间对隐层添加线性运算,这就是RNN的基本思想。
RNN结构

-
这张图可以帮助我们理解S的每一步循环含义:

-
三维图可以帮助我们理解输入、输出和输出的形状:

LSTM
LSTM结构
LSTM在RNN的基础上,加入了许多“门”,这些门决定了神经元在处理每一个step时,可以根据新的输入来判断自己应该“遗忘”和“更新”哪些记忆。图中的h表示神经元的输出,c表示神经元的细胞状态cell_state。

使用LSTM实现一个写诗机
数据集
我们使用5.7万余首诗词作为数据集。所有诗词被放在名为poetryTang.txt的文本文件中。

数据预处理
从txt中读出数据
def load_file(filename):
raw_poems = []
try:
f = open(filename)
for each_line in f.readlines():
if len(each_line) > 128 or len(each_line) < 12:
continue
raw_poems.append('[' + each_line.split(':')[-1].strip('\n') + ']')
except Exception:
print('no such file found!')
return raw_poems
我们测试一下函数:
raw_data = load_file('poetryTang.txt')
print(raw_data[:2])

为词嵌入做准备
- 我们现在的数据是字符串形式的,虽然对于我们来说是易读的,但并不合适直接输入我们的模型。一般来说,我们需要将文本中所有的字(或词语)转化为数字ID,每个数字ID对应一个字符,我们输入模型的是这些ID。具体地:首先将文本按字/词拆分,再进行集合操作,形成字/词袋,然后为字/词袋中的每个元素分配一个ID,最后将文本中的字按照字-ID映射全部转换为ID。下面的代码是一个示例:
def get_dictionary(raw_poems):
dictionary = {
}
all_words = []
for each_poem in raw_poems:
all_words.extend(each_poem)
word_count = collections.Counter(all_words).most_common(all_words_size - 1)
words_set, _ = zip(*word_count)
words_set += (' ', )
dictionary = dict(zip(words_set, range(len(words_set))))
word_count.sort(key = lambda x : x[-1])
word_to_id_fun = lambda x : dictionary.get(x, len(words_set) - 2)
poems_vector = [([word_to_id_fun(word) for word in poem]) for poem in raw_poems]
return poems_vector, dictionary, words_set
我们为每个诗句的开头都加上"[",结尾加上"]",并加入训练。这样模型只要接收到"[",就知道是一个诗词的开始,需要结束写诗时就会输出"]"。测试一下函数:
poems_vector, dictionary, words_set = get_dictionary(raw_data)
print(poems_vector[0][:5])
print('凄: {}, [: {}'.format(dictionary['凄'], dictionary[r'[']))

- 同样的,我们从模型里拿到的输出是ID,所以还需要将ID转为字,我们可以创建一个匿名函数实现这个需求:
word_to_id_fun = lambda x : dictionary.get(x, all_words_size-2)
模型设计
设计思路
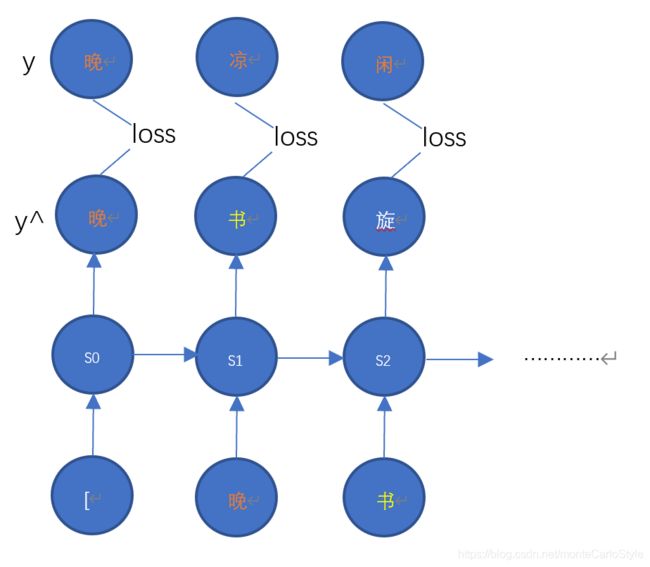
循环神经网络可以记忆前n个字符,并利用这n个字符来预测第n+1个字符。在训练阶段,可以将正确的诗句作为y来修正模型参数。以“晚凉闲步向江亭,默默看书旋旋行。”为例,预测与训练阶段的模型计算过程图如下:
-
预测阶段

-
训练阶段
模型搭建——前向计算
首先,我们将get_dictionary()和load_file()装入类中,这样我们每次只需要创建一个实例,就可以方便地拿到数据。这个过程中,将一些重要的变量设置为成员属性。
class PoetryMachine(tf.keras.Model):
def __init__(self, lr = 1e-2, num_words = 5000, embeddings_dim = 512, units_each_layer = 32):
super().__init__()
def load_file(self, filename = 'poetryTang.txt'):
raw_poems = []
try:
f = open(filename)
for each_line in f.readlines():
if len(each_line) > 128 or len(each_line) < 12:
continue
raw_poems.append('[' + each_line.split(':')[-1].strip('\n') + ']')
except Exception:
print('no such file found!')
self.raw_poems = raw_poems
def get_dictionary(self, raw_poems):
dictionary = {
}
all_words = []
for each_poem in raw_poems:
all_words.extend(each_poem)
word_count = collections.Counter(all_words).most_common(self.num_words - 1)
words_set, _ = zip(*word_count)
words_set += (' ', )
self.words_set = words_set
self.dictionary = dict(zip(words_set, range(len(words_set))))
word_count.sort(key = lambda x : x[-1])
self.word_to_id_fun = lambda x : self.dictionary.get(x, len(words_set) - 2)
self.poems_vector = [([self.word_to_id_fun(word) for word in poem]) for poem in raw_poems]
创建一个写诗机模型,加载数据
model = PoetryMachine()
model.load_file()
model.get_dictionary(model.raw_poems)
观察一下我们的诗句转化为ID之后的样子:
print(model.poems_vector[:2])

词嵌入
词嵌入就是将字符转化为向量嵌入到我们的网络中,从而可以参与计算。如果将一个字/词表示为向量,有一种one-hot方法:我们知道字/词的数字ID可以表示这个字/词在词袋中的位置,现在假设词袋中有N个词,某个词的数字ID是i,则该词会生成一个N维向量,只有第i个位置的元素为1,其余皆为0。例如,有词袋:{‘我’:0, ‘爱’:1, ‘NLP’:2},则“我”可以表示为[1, 0, 0],“爱”可以表示为[0, 1, 0]。当我们语料中的词语很多时,每个词向量的维度会非常大,这对于后续的计算来说是非常不友好的。所以,还有其他的词嵌入方法(如word2vec),可以将词语嵌入到一个低维度、连续型的向量空间中。例如将“我”转化为[0.12, 0.33]。
- 我们可以用如下代码完成一个简单的词嵌入:
model = PoetryMachine()
model.load_file('poetryTang.txt')
model.get_dictionary(model.raw_poems)
#定义词嵌入层,设置词袋大小为5000字符、词向量维度为128
embeddings = tf.keras.layers.Embedding(input_dim=5000, output_dim=128, embeddings_initializer='normal')
我们将第一首诗(66个字符)的数字ID列表输入到词嵌入层中,观察一下效果:
model.embeddings(np.array(model.poems_vector[0]))

输出为66个128维向量
LSTM层
- 有了诗句的所有词向量之后,我们就可以设计LSTM层了。写诗机使用3层LSTM:
lstm_layer_1 = tf.keras.layers.LSTMCell(units=64)
lstm_layer_2 = tf.keras.layers.LSTMCell(units=64)
lstm_layer_3 = tf.keras.layers.LSTMCell(units=64)
stacked_lstm = tf.keras.layers.StackedRNNCells(cells=[lstm_layer_1, lstm_layer_2, lstm_layer_3])
lstm_layer = tf.keras.layers.RNN(stacked_lstm, return_sequences=True, return_state=True)
我们可以观察第一首诗词经过embedding、lstm之后的结果:
outputs,state_0,state_1,state_2=lstm_layer(tf.expand_dims(model.embeddings(np.array(model.poems_vector[0])), axis=0))
print(outputs.shape)
print(state_0[0].shape, state_0[1].shape)

outputs是lstm最后一层所有step的输出,state_0为第一层最后一个step的输出和cell_state。
Output
模型的最后一层使用一个全连接层,输出维度为词袋大小。每一个step的输出都是一个词袋维度的向量,向量中的每个元素对应着词袋中每个字词的得分。我们将向量中最大元素的下标作为模型的预测输出。
- 定义所需的参数:
self.W_fc = tf.Variable(tf.random.normal(shape=[units_each_layer, self.num_words], dtype='float32'), trainable=True)
self.b_fc = tf.Variable(tf.random.normal(shape=[self.num_words], dtype='float32'), trainable=True)
- 组合我们的网络。后续实现写诗功能时需要我们一步一步地输入,此时需要保存、输入LSTM的细胞状态state:
def forward(self, input_x, initial_state=None):
embeddings = self.embeddings(input_x)
if initial_state is not None:
outputs, final_state_0, final_state_1, final_state_2 = self.lstm_layer(embeddings, initial_state=initial_state)
else:
outputs, final_state_0, final_state_1, final_state_2 = self.lstm_layer(embeddings)
hidden = tf.reshape(outputs, [-1, outputs.shape[-1]])
logits = tf.matmul(hidden, self.W_fc) + self.b_fc
return logits, [final_state_0[-1], final_state_1[-1], final_state_2[-1]]
模型搭建——反向传播
损失函数
信息量与KL散度
香侬熵(Shannon entropy)是经典信息理论的重要概念。香侬认为,信息是用来消除随机不确定性的东西。当一个随机变量越确定,那么它的信息量就越少。信息熵(香侬熵)可以用来描述一个随机变量的信息量,它是某个随机变量的信息量的数学期望。

若对于同一个随机变量X有两个单独的概率分布P(x)和Q(x),则使用KL散度衡量两个概率分布之间的差异。

KL散度越小,P(x)和Q(x)的分布越接近。
交叉熵损失
若对KL散度公式进行拆分,可得

若将样本的真实分布作为P(x),网络的输出分布作为Q(x)。因为当样本和真实分布确定之后,信息熵H是不变的,那么就可以使用

来度量网络预测的分布与真实分布之间的差异,这个度量值称为交叉熵。
在多分类任务中,由于神经网络输出多为样本的类别离散分布,使用交叉熵损失(Entropy Loss)来衡量网络的损失是比较合适的。损失函数是神经网络的重要组成部分,它既是神经网络的输出值与实际值的偏差,也是神经网络学习样本分布过程中必不可少的元素。
- 词袋中的每个词都作为一个类别,使用如下函数定义我们的交叉熵损失函数:
def loss(logits, input_y):
input_y = tf.reshape(input_y, [-1])
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=input_y, logits=logits)
return loss
训练
- 我们在训练模型之前,要按照预设的bath_size大小将输入input_x分块,并且生成对应的y。
def load_train_data(self, batch_size = 256):
print('loading train_data...')
self.batch_size = batch_size
self.X = []
self.Y = []
batch_num = (len(self.poems_vector) - 1) // self.batch_size
for i in range(batch_num):
#batch
batch = self.poems_vector[i * self.batch_size : (i + 1) * self.batch_size]
max_len = max([len(vector) for vector in batch])
temp = np.full((self.batch_size, max_len), self.word_to_id_fun(' '), np.int32)
for j in range(model.batch_size):
temp[j, :len(batch[j])] = batch[j]
self.X.append(temp)
temp2 = np.copy(temp)
temp2[:, :-1] = temp[:, 1:]
self.Y.append(temp2)
print('done, batch_size: {}, batch_num of each epoch: {}, count of poems: {}'.format(str(self.batch_size), str(batch_num), str(len(self.poems_vector))))
我们可以输入以下代码,查看第一个batch的第一个诗句的训练数据对:
model = PoetryMachine()
model.load_file()
model.get_dictionary(model.raw_poems)
model.load_train_data()
print(model.X[0][0], '\n', model.Y[0][0])

- 接下来,我们要完成训练函数的设计, 这里要留意tf.GradientTape()的作用、我们是如何根据loss计算梯度的,还有如何更新我们的权重:
def train(self, batch_size=256, epochs=10, input=None):
if input is not None:
pass
else:
self.load_train_data(batch_size=batch_size)
self.vars = self.get_variables()
self.restore_weights()
train_step = 0
batch_num = len(self.X)
for epoch in range(epochs):
for x, y in zip(self.X, self.Y):
with tf.GradientTape() as tape:
logits, states = self.forward(input_x=x)
loss = self.loss(logits=logits, input_y=y)
grads = tape.gradient(loss, self.vars)
self.optimizer.apply_gradients(grads_and_vars=zip(grads, self.vars))
train_step += 1
print('Episode {}: gloable_step {}, loss {:.3f}'.format(epoch, train_step, tf.reduce_sum(loss)/(self.batch_size*x[0].shape[0])))
if epoch%10 == 0:
self.save_my_weights()
self.save_my_weights()
def save_my_weights(self, path='./libai_weights'):
try:
self.save_weights(path)
print('weights saved: {}'.format(path))
except Exception as e:
print(e)
print('fail to save')
诗词生成
给模型第一个输入“[”,模型会给出第一个输出 y ^ 0 \hat{y}_0 y^0,根据 y ^ 0 \hat{y}_0 y^0来判断模型是否需要继续下一个step的预测。
当参数不变,cell_state、输入都相同,模型会给出相同的输出 y ^ \hat{y} y^,模型会始终预测同样的诗句。为了防止这种情况发生,我们要给输出一个随机的扰动。
def probs_to_word(self, weights, words):
t = np.cumsum(weights)
s = np.sum(weights)
coff = np.random.rand(1)
index = int(np.searchsorted(t, coff * s))
return words[index]
def write(self, generate_num = 10):
poems = []
for i in range(generate_num):
x = np.array([[self.word_to_id_fun('[')]])
prob1, state = self.forward(input_x=x)
prob1 = tf.nn.softmax(prob1, axis=-1)
word = self.probs_to_word(prob1, self.words_set)
poem = ''
loop = 0
while word != ']' and word != ' ':
loop += 1
poem += word
if word == '。':
poem += '\n'
x = np.array([[self.word_to_id_fun(word)]])
next_probs, state = self.forward(input_x=x, initial_state=state)
next_probs = tf.nn.softmax(next_probs, axis=-1)
word = self.probs_to_word(next_probs, self.words_set)
if loop > 100:
loop = 0
break
print(poem)
poems.append(poem)
return poems
测试模型
点击此处下载数据
- 完整的代码
import collections
import json
import numpy as np
import tensorflow as tf
class PoetryMachine(tf.keras.Model):
def __init__(self, lr = 1e-2, num_words = 5000, embeddings_dim = 128, units_each_layer = 128):
super().__init__()
self.num_words = num_words
self.batch_size = 256
self.embeddings = tf.keras.layers.Embedding(input_dim=num_words, output_dim=embeddings_dim,
embeddings_initializer='normal')
self.lstm_layer_1 = tf.keras.layers.LSTMCell(units=units_each_layer)
self.lstm_layer_2 = tf.keras.layers.LSTMCell(units=units_each_layer)
self.lstm_layer_3 = tf.keras.layers.LSTMCell(units=units_each_layer)
self.stacked_lstm = tf.keras.layers.StackedRNNCells(cells=[self.lstm_layer_1, self.lstm_layer_2, self.lstm_layer_3])
self.lstm_layer = tf.keras.layers.RNN(self.stacked_lstm, return_sequences=True, return_state=True)
self.W_fc = tf.Variable(tf.random.normal(shape=[units_each_layer, self.num_words], dtype='float32'), trainable=True)
self.b_fc = tf.Variable(tf.random.normal(shape=[self.num_words], dtype='float32'), trainable=True)
self.optimizer = tf.keras.optimizers.Adam(learning_rate=lr)
def load_file(self, filename = 'poetryTang.txt'):
raw_poems = []
try:
f = open(filename)
for each_line in f.readlines():
if len(each_line) > 128 or len(each_line) < 12:
continue
raw_poems.append('[' + each_line.split(':')[-1].strip('\n') + ']')
except Exception:
print('no such file found!')
self.raw_poems = raw_poems
def get_dictionary(self, raw_poems):
dictionary = {
}
all_words = []
for each_poem in raw_poems:
all_words.extend(each_poem)
word_count = collections.Counter(all_words).most_common(self.num_words - 1)
words_set, _ = zip(*word_count)
words_set += (' ', )
self.words_set = words_set
self.dictionary = dict(zip(words_set, range(len(words_set))))
word_count.sort(key = lambda x : x[-1])
self.word_to_id_fun = lambda x : self.dictionary.get(x, len(words_set) - 2)
self.poems_vector = [([self.word_to_id_fun(word) for word in poem]) for poem in raw_poems]
def load_train_data(self, batch_size = 256):
print('loading train_data...')
self.batch_size = batch_size
self.X = []
self.Y = []
batch_num = (len(self.poems_vector) - 1) // self.batch_size
for i in range(batch_num):
#batch
batch = self.poems_vector[i * self.batch_size : (i + 1) * self.batch_size]
max_len = max([len(vector) for vector in batch])
temp = np.full((self.batch_size, max_len), self.word_to_id_fun(' '), np.int32)
for j in range(model.batch_size):
temp[j, :len(batch[j])] = batch[j]
self.X.append(temp)
temp2 = np.copy(temp)
temp2[:, :-1] = temp[:, 1:]
self.Y.append(temp2)
print('done, batch_size: {}, batch_num of each epoch: {}, count of poems: {}'.format(str(self.batch_size), str(batch_num), str(len(self.poems_vector))))
def forward(self, input_x, initial_state=None):
embeddings = self.embeddings(input_x)
if initial_state is not None:
outputs, final_state_0, final_state_1, final_state_2 = self.lstm_layer(embeddings, initial_state=initial_state)
else:
outputs, final_state_0, final_state_1, final_state_2 = self.lstm_layer(embeddings)
hidden = tf.reshape(outputs, [-1, outputs.shape[-1]])
logits = tf.matmul(hidden, self.W_fc) + self.b_fc
return logits, [final_state_0[-1], final_state_1[-1], final_state_2[-1]]
def loss(self, logits, input_y):
input_y = tf.reshape(input_y, [-1])
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=input_y, logits=logits)
return loss
def get_variables(self):
return self.trainable_variables
def train(self, batch_size=256, epochs=10, input=None):
if input is not None:
pass
else:
self.load_train_data(batch_size=batch_size)
self.vars = self.get_variables()
self.restore_weights()
train_step = 0
batch_num = len(self.X)
for epoch in range(epochs):
for x, y in zip(self.X, self.Y):
with tf.GradientTape() as tape:
logits, states = self.forward(input_x=x)
loss = self.loss(logits=logits, input_y=y)
grads = tape.gradient(loss, self.vars)
self.optimizer.apply_gradients(grads_and_vars=zip(grads, self.vars))
train_step += 1
print('Episode {}: gloable_step {}, loss {:.3f}'.format(epoch, train_step, tf.reduce_sum(loss)/(self.batch_size*x[0].shape[0])))
if epoch%10 == 0:
self.save_my_weights()
self.save_my_weights()
def save_my_weights(self, path='./libai_weights'):
try:
self.save_weights(path)
print('weights saved: {}'.format(path))
except Exception as e:
print(e)
print('fail to save')
def restore_weights(self, path='./libai_weights'):
try:
self.load_weights(path)
print('weights restored from {}'.format(path))
except:
print('model weights not found...')
def write(self, generate_num = 10):
poems = []
for i in range(generate_num):
x = np.array([[self.word_to_id_fun('[')]])
prob1, state = self.forward(input_x=x)
prob1 = tf.nn.softmax(prob1, axis=-1)
word = self.probs_to_word(prob1, self.words_set)
poem = ''
loop = 0
while word != ']' and word != ' ':
loop += 1
poem += word
if word == '。':
poem += '\n'
x = np.array([[self.word_to_id_fun(word)]])
next_probs, state = self.forward(input_x=x, initial_state=state)
next_probs = tf.nn.softmax(next_probs, axis=-1)
word = self.probs_to_word(next_probs, self.words_set)
if loop > 100:
loop = 0
break
print(poem)
poems.append(poem)
return poems
def probs_to_word(self, weights, words):
t = np.cumsum(weights)
s = np.sum(weights)
coff = np.random.rand(1)
index = int(np.searchsorted(t, coff * s))
return words[index]
- 创建一个写诗机实例,载入数据集
model = PoetryMachine()
model.load_file()
model.get_dictionary(model.raw_poems)
- 训练模型
model.train()
- 写诗
model.write()
