JDK中提供了几个非常有用的并发工具类,也就是这次要讲的四大天王:CountDownLatch,CyclicBarrier,Semaphore,Exchanger。
先来一张帅照
1.闭锁CountDownLatch(等待多线程完成)
我们常常在编程的时候遇到这样一种需求:开辟多个线程完成某个计算任务,然后等到所有线程计算完毕后汇总计算结果。对于这种需求,如果我们不适用CountDownLatch的话,可以使用Thread类中的join(()方法。join用于让当前线程等待join线程执行结束。其原理就是不停检查join线程是否存活,如果join线程存活则让当前线程永远等待。知道join线程终止后,线程的this.noeityAll()方法会被调用。
使用join的例子如下:
import java.util.Random;
public class Test {
public static void main(String[] args) {
int nThreads = 10;
Thread[] threads = new Thread[nThreads];
for(int i = 0;i < nThreads;i++){
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("I am "+Thread.currentThread().getName()+"and starts");
try {
//模拟计算任务耗时
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("I am "+Thread.currentThread().getName()+"and ends");
}
});
threads[i].start();
}
// 等待每个线程执行结束
for(int j = 0;j < nThreads;j++){
try {
threads[j].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 只有每个线程都执行结束了,这句话才会执行
System.out.println("ALL is over");
}
}
好了,join就到此为止吧,不能让主角等急了。下面就重点聊一下CountDownLatch。
老规矩先给一张应用CountDownLatch的帅照吧。
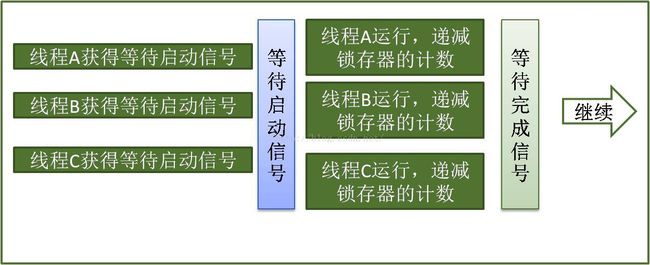
从上图可以看出,CountDownLatch就像是一扇门,在这上门门开启之前,所有的线程都在门外等待执行,当打开这扇门的时候,所有线程可以自由执行,但是这扇门将不会改变状态,因此这扇门永远保持打开状态。
下面我们介绍一种CountDwonLatch使用的最为经典的场景:起始门,结束门。
public class TestHarness {
public long timeTasks(int nThreads, final Runnable task)
throws InterruptedException {
// 起始门
final CountDownLatch startGate = new CountDownLatch(1);
// 结束门
final CountDownLatch endGate = new CountDownLatch(nThreads);
for (int i = 0; i < nThreads; i++) {
Thread t = new Thread() {
public void run() {
try {
//在起始门处等待,知道开启起始门,才会往下执行
startGate.await();
try {
task.run();
} finally {
//执行完后,结束门计数器减1
endGate.countDown();
}
} catch (InterruptedException ignored) {
}
}
};
t.start();
}
long start = System.nanoTime();
//打开起始门,让所有线程开始执行
startGate.countDown();
//在结束门上等待,只有所有线程都执行完毕后才会继续往下执行
endGate.await();
long end = System.nanoTime();
return end - start;
}
}
如上,使用两个门:起始门,结束门。起始门的计数器初始值为1,而结束门计数器的初始值为工作者线程的数量。每一个工作者线程首先要做的事就是在起始门上等待,从而确保所有线程就绪后才开始执行。而每一个线程要做的最后一件事情就是调用结束门的counDown方法减1,这能使主线程高效地等待直到所有工作者线程都执行完成,因此可以统计所消耗的时间。
为什么要使用起始门使得所有线程等待而不是线程创建后就立即启动呢?获取我们希望测试N个线程并发执行某个任务时需要的时间,如果在线程创建后就立即启动它们,那么先启动的线程将领先后启动的线程,并且活跃线程数量会随着时间的推移而增加或者是减少,竞争程度也在不断变化。启动门将使得主线程能够同时释放所有的工作者线程,而结束门则使主线程能够等待最后一个线程执行完成,而不是顺序地等待每一个线程执行完成
2.同步屏障CyclicBarrier(可循环使用)
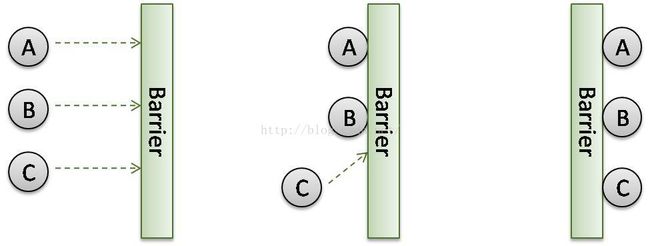
CountDownLacth是一次性对象,一旦进入终止状态,就不能被重置。CyclicBarrier与CountDwonLacth类似,它能阻塞一组线程知道某个事件发生。但是这两者有一个重要的区别:对于CyclicBarrier而言,所有线程必须同时到达屏障处才能继续执行,而对于CountDownLathc而言,所有线程必须等待某一件事件,当该事件发生时,线程才能执行。
老规矩,先来一张帅照
CyclicBarrier有两个构造方法:
/**
* @param parties 屏障拦截的线程数量
*/
public CyclicBarrier(int parties){...}
/**
* @param parties 屏障拦截的线程数量
* @param barrierAction 所有线程到达屏障时优先执行barrierAction
*/
public CyclicBarrier(int parties, Runnable barrierAction){...}
对于每一个线程,当调用了await方法就是告诉CyclicBarrier我已经到达了屏障,然后当前线程被阻塞。
下面举一个实际应用的例子(应用自<
import java.util.Map;
import java.util.Map.Entry;
import java.util.Random;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class BrankWaterService implements Runnable{
/**
* 穿件4个屏障,处理完之后执行当前类的run方法
*/
private CyclicBarrier c = new CyclicBarrier(4,this);
/**
* 假设只有4个sheet,所以启动4个线程
*/
private ExecutorService executor = Executors.newFixedThreadPool(4);
/**
* 保存每个sheet计算出来的银行流水线结果(使用ConcurrentHashMap保证线程安全)
*/
private Map sheetBankWaterCount = new ConcurrentHashMap();
private void count() {
for (int i = 0 ;i <4;i++){
executor.execute(new Runnable() {
@Override
public void run() {
// 计算当前sheet的银行流水线结果,计算过程忽视...
sheetBankWaterCount.put(Thread.currentThread().getName(), new Random().nextInt(10));
try {
//到达屏障
c.await();
} catch (BrokenBarrierException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
@Override
public void run() {
int result = 0;
//汇总每一个sheet计算的结果
for(Entry sheet : sheetBankWaterCount.entrySet()){
result += sheet.getValue();
}
System.out.println(result);
}
public static void main(String[] args) {
BrankWaterService brankWaterService = new BrankWaterService();
brankWaterService.count();
}
}
3.信号量Semaphore(控制访问资源的线程数)
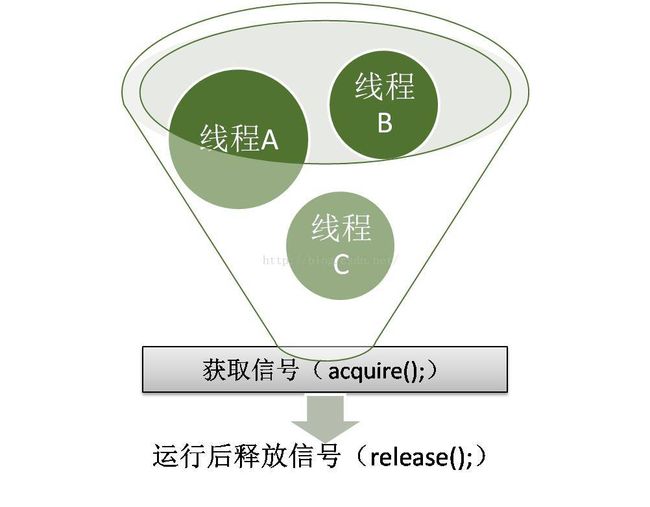
如图,信号量用于控制同时刻访问资源的线程数量。每一线程需要访问资源的时候就需要获得一个访问许可(如果还有的话),并在使用完之后释放许可,如果没有许可,那么acquire将阻塞知道有许可(或者知道被中断或者操作超时)。release方法将返回一个许可给信号量。
下面举一个例子(<
我们需要读取几万个日志文件,因为都是IO密集型任务,我么可以启动几十个线程并发地读取,但是读取到内存后,我们还需要存储到数据库中,而数据库的连接只有10个,这时我们必须控制只有10个线程同时获取数据库连接保存数据,否者就会报错无法获取数据库连接,这个时候就可以使用信号量来做流量控制。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
public class SemaphoreTest {
private static final int THREAD_cOUNT = 30;
private static ExecutorService pool = Executors.newFixedThreadPool(10);
private static Semaphore s = new Semaphore(10);
public static void main(String[] args) {
for(int i =0 ;i < THREAD_cOUNT;i++){
pool.execute(new Runnable() {
@Override
public void run() {
try {
s.acquire();
System.out.println("save data");
s.release();
} catch (InterruptedException e) {
}
}
});
}
pool.shutdown();
}
}
代码中虽然有30个线程,但是只允许10个并发执行。Semaphore的构造方法public Semaphore(int permits)接受一个整形的数字,表示可用的许可数量。 Semaphore(10)表示允许10个线程获取许可,那就是最大并发数是10。acquire方法获取一个许可,使用完之后使用release方法归还许可。Semaphore类中海油其他的一些方法可以使用,这里就不一一介绍了,大家有兴趣可以翻开一下JDK文档看一下或者直接看源代码。
4.交换者Exchanger(交换数据)
Exchanger是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换,它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过exchange方法交换数据,如果第一个线程先执行exchange方法,它会一直等待第二个线程也执行exchange方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程的数据传递给对方。
这个工具的应用场景其实不太好找,不过我们可以考虑这样一种应用场景:校对工作。比如,我们需要将纸质银行流水通过人工的方式录入成电子银行流水,为了避免错误,才用AB岗两人进行录入,录入到EXCEL后,系统需要加载这两个excel,并对两个excel数据进行校对,看看录入是否一致。
这里就不写出上述场景的具体的代码了,不过我写了一个测试程序用于让大家理解一下这个工具:
import java.util.Random;
import java.util.concurrent.Exchanger;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ExChangerTest {
public static void main(String[] args) {
Exchanger exchanger = new Exchanger();
int nThreads = 10;
ExecutorService pool = Executors.newFixedThreadPool(nThreads);
// 同时启动10个线程,每一个线程依次休息1,2,3,4...10秒,然后再交换数据
for (int i = 0; i < nThreads; i++) {
pool.execute(new Work(exchanger, (i + 1)));
}
pool.shutdown();
}
}
class Work implements Runnable {
// 同步器
private Exchanger exchanger;
// 休息的秒数
private int seconds;
public Work(Exchanger exchanger, int seconds) {
this.exchanger = exchanger;
this.seconds = seconds;
}
@Override
public void run() {
try {
Thread.sleep(seconds * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 从其他线程交换得来的的数据
Integer another = null;
// 本地产生的的数据
Integer localData = null;
//休息指定的时间后开始交换数据
try {
localData = new Random().nextInt(100);
another = exchanger.exchange(localData);//交换数据的同步点
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "-->>received data is:" + another);
System.out.println(Thread.currentThread().getName() + "-->>sended data is:" + localData);
}
}
这个程序制定的大致结果如下:
pool-1-thread-1-->>received data is:43
pool-1-thread-1-->>sended data is:42
pool-1-thread-2-->>received data is:42
pool-1-thread-2-->>sended data is:43
pool-1-thread-4-->>received data is:68
pool-1-thread-4-->>sended data is:8
pool-1-thread-3-->>received data is:8
pool-1-thread-3-->>sended data is:68
pool-1-thread-5-->>received data is:46
pool-1-thread-5-->>sended data is:80
pool-1-thread-6-->>received data is:80
pool-1-thread-6-->>sended data is:46
pool-1-thread-7-->>received data is:98
pool-1-thread-7-->>sended data is:39
pool-1-thread-8-->>received data is:39
pool-1-thread-8-->>sended data is:98
pool-1-thread-10-->>received data is:16
pool-1-thread-10-->>sended data is:56
pool-1-thread-9-->>received data is:56
pool-1-thread-9-->>sended data is:16
其结果可以看成是5部分:线程1,2为一部分,线程3,4为一部分...线程9,10为一部分。之所以是这样的结果,是因为当第一个线程执行后1s后,需要交换数据,但是由于其他线程还没有执行到同步点,所以线程1在同步点处阻塞,而此时线程2也已经等待了1s,在过1s后,线程2醒来,执行到同步点,这时同步器发现线程1和线程2都已经执行到了同步点,那么久开始交换数据,并继续执行线程中的其他部分(打印交换的数据)。由于其他线程还在睡眠中,还没有执行到同步点,所以只有线程1,2交换数据。同样地,线程2,3,...线程9,10也是同样的规律去执行。所以总的结果就是每隔2秒相邻的相个线程交换数据并执行完毕。