《Expert .NET 2.0 IL Assembler》 第四章 托管可执行体文件的结构 4.2 CLR头(二)
重定位区段
映像文件的.reloc区段包括了Fixup表,它为映像文件中的所有修正保存了入口。RVA和.reloc区段的大小都由PE头的Base Relocation表目录定义。Fixup表由很多块修正组成,每一块将这些修正保存为一个4KB的页。这些块都是按4字节排列的。
每一个修正都描述了映像文件中特定地址的位置,以及当加载这个映像文件到内存的时候,OS加载器应该如何修改这个位置上的地址。
每一个修正块开始于两个4字节的无符号整数:这个页的RVA包括了要修正的地址和这个块的大小。这个页的入口的修正包括直接位于它的后面。每个入口都有16位的宽度,包含了重定位的类型所需要的4个最重要的字节。剩下的12位保存了这个页中重定位地址的偏移量。
为了重定位地址,OS的加载器计算出首选的基地址(PE头的ImageBase字段)和实际映像文件被加载的基地址之间的不同(delta)。这个delta接着根据重定位的类型被应用到地址上。一旦映像文件被加载到它首选的位置,就不会应用任何修正。
下面的重定位类型定义于Winnt.h中:
IMAGE_REL_BASED_ABSOLUTE (0):这个类型在映像文件中没有任何意义,修正在这里被跳过。
IMAGE_REL_BASED_HIGH (1):这个delta的16高位段被添加到偏移量上的16位字段上。
IMAGE_REL_BASED_LOW (2):这个delta的16低位段被添加到偏移量上的16位字段上。在这种情形中的16位字段是32位地址被重新部署的半数低位。
IMAGE_REL_BASED_HIGHLOW (3):这个delta被添加到偏移量上的32位字段上。对这个类型的重定位与IMAGE_REL_BASED_HIGH和IMAGE_REL_BASED_LOW这些重定位的位或运算是相等的,它是32位地址重定位的首选类型。
IMAGE_REL_BASED_HIGHADJ (4):这个delta的16高位段被添加到偏移量上的16位字段上。这个16位字段在这种情形中是重定位的32位地址的高位部分。这个地址的16低位存储在16位的在这个重定位之后的单词中。这个类型的修正占据了两个槽。
IMAGE_REL_BASED_MIPS_JMPADDR (5):
IMAGE_REL_BASED_SECTION (6):保留的。
IMAGE_REL_BASED_REL32 (7):保留的。
IMAGE_REL_BASED_MIPS_JMPADDR16 (9):这个修正应用到MIPS的jump方法。
IMAGE_REL_BASED_IA64_IMM64 (9):与IMAGE_REL_BASED_MIPS_JMPADDR16相同。
IMAGE_REL_BASED_DIR64 (10):这个delta在偏移量上被添加到64位字段。
IMAGE_REL_BASED_HIGH3ADJ (11):这个修正添加了这个delta的16高位段到偏移量上的16位字段上。这个16位字段是48高位地址的三分之一。这个地址的32位低位存储在32位两倍于这个单词中,紧跟在这个重定位中。这个类型的一个修正占据了3个槽。
唯一的修正类型是IMAGE_REL_BASED_HIGHLOW,由32位可执行体中的已有的托管编译器发布。在64位可执行体中,则是IMAGE_REL_BASED_DIR64
一个32位的纯净IL的PE文件,在.text区段中只包括一个修正。这样做是为了CLR开始的stub,在一个纯净的IL映像文件中本地代码的唯一片段。这个修正是为了映像文件的IAT,包括了一个唯一的入口:CLR入口点。
一个64位的纯净IL的PE文件,在X64体系中有1个修正,在Itanimu体系中有2个修正(额外的那个修正是为了全局指针)。
Windows XP或者更新的版本,作为一个CLR天生载体的操作系统,既不需要CLR的开始stub,也不需要IAT来调用CLR。因此,如果CLR头的标记指出映像文件只是IL(COMIMAGE_FLAGS_ILONLY),操作系统就会完全地忽略这个.reloc区段。
这种优化对由IL编译器生成的一些映像文件开了一个冷笑话,这将生成纯净的IL映像文件但却需要重定向被执行——如果有任何数据定位于TLS或定义了data on data。当映像文件在Windows XP下被加载时,为了让这些重定位得到执行,IL编译器被迫作弊并设置CLR头的标记就好像映像文件包括内嵌的本地代码(32位目标平台上为COMIMAGE_FLAGS_32BITREQUIRED,没有适用于64位目标平台的值)。
其他平台上并没有这些问题。生成了纯净IL映像文件的编译器(如C#或VB.NET)并没有定义基于TLS的数据或data-on-data。
正如VC++编译器和连接器生成混合代码的映像文件那样,这些映像文件的.reloc区段可以包括任意数量的重定位。但是混合代码的映像文件从来不携带仅有IL的CLR头标记,因此他们的重定位总是被执行。
文本区段
PE文件的文本区段是一个只读区段。在一个托管的PE文件中,它包括了元数据表、导出表、CLR头以及用于CLR的非托管的启动stub。在这个由IL编译器生成的映像文件中,这个区段还包括了托管资源、哈希强签名、调试数据以及非托管的导入型stub。
图4-3总结了由IL编译器生成的.text区段的通用结构。
IL编译器以一个特定的顺序发布数据到.text区段。当PE文件生成器在IL启动期间被初始化的时候,就会在.text区段为输入地址表(只携带一个单独的入口,作为CLR的入口点)和在本章前面章节描述的CLR头分配空间。
当IL编译器解析源代码并在内存中形成元数据和IL结构体的时候,.text区段得到一个临时性的断点;直到解析完成并且IL编译器做好PE文件发布的准备时,才会发布上去。
接下来是IL编译器,如果是这样被安排好的(通过在.assembly指令中指定公钥;参见第6章了解详细内容),为强签名在.text区段分配充分的空间。强签名是一个对主模块使用程序集发布者的私钥进行加密的哈希值。签名本身被发布到随后分配的空间中,作为主模块生成的最后一步。
接下来进行到方法体这一步,包括了方法头、IL代码以及托管异常处理表(参见第10章了解详细内容)。
图4-3 由IL编译器发布的.text区段的结构

在方法体被发布后,而且一旦你定制了包括调试信息的PDB文件的生成,IL编译器就发布调试目录入口以及包括了指向PDB文件路径的CodeReview-style头。
接下来是元数据,在那之后会被完全定义的,就被发布到.text区段,紧跟在后面的是托管资源(如果有的话)。元数据格式会在下一章详细描述,而托管资源将会在本章后面的“资源”章节讨论。
在元数据和托管资源之后,非托管导出stub发布为那些托管的方法——被暴露为非托管的导出。第18章描述了导出托管方法为非托管的客户端。
下一个发布到.text区段的项(如果存在),是本章前面描述的V-表的修正表。
最后一个发布到.text区段的项,是CLR的非托管起始stub,它的RVA被分配到PE头的AddressOfEntryPoint字段。
数据区段
由IL编译器生成的一个映像文件的数据区段(.sdata),是一个可读写的区段。它包括了数据常量、在“V-表”章节中描述的V-表、非托管导出表以及TLS的目录结构。声明为特定于线程的数据位于一个不同的区段,也就是.tls区段。
数据常量
数据常量这个术语,可能有一些误解。数据常量位于一个可读写的区段中,肯定可以被覆写,因此从技术上讲,很难称其为常量。然而这个词语,涉及的是数据的用法而不是数据的本性。数据常量代表了静态字段直接的映射,并通常包括被映射字段初始化了的数据。(第一章描述了字段映射的特性。)
字段映射是一个便捷的方式来初始化任何带有ANSI字符串、blob或结构的静态字段。一个可选择的初始化静态字段的方法——也是一个以CLR形式的更传统的方法——将会通过执行类的构造函数中的代码显示地对其操作,正如第九章讨论的那样。但是这种可选择性更加单调乏味,因此没有人真的去责备编译器借助字段映射来初始化。VC++编译器映射了所有的全局字段,而不管它们是否将会被初始化。
将静态字段映射到数据有其自身的需要注意的。映射到数据区段的字段,换句话说,就如同类型控制和垃圾收集那样,是CLR控制机制难以达到的,换句话说,对于自由访问和修改是广泛开放的。这就引起了加载器阻止特定的字段类型被映射;被映射的字段类型可能不包括指向对象、向量、数组或任何非公有的子结构的引用。如果类的构造函数被用为静态字段初始化,就不会有这样的问题发生。从哲学意义上讲,这是非常自然的:贯穿人类的历史,背离了正统,尽管是临时性的,也总是会带来一些不愉快的并发症。
V-表
纯托管代码模块中的V-表用于将托管方法暴露给非托管代码来调用。V-表是由一些入口条目组成,每个入口条目又是由一个或多个槽位组成。这些入口和V-表的槽都定义在V-表的修正中——在前面“VTableFixedup字段”章节讨论。每个修正详细指明了数量和在每个入口中这些槽的宽度(4或8字节)。每个V-表的槽包含了相应方法的元数据符号,这将在执行期间被方法本身的地址或提供了非托管的方法入口的一个封送了thunk的地址所取代。随着这些修正在运行期间被执行,这个由托管的PE文件组成的V-表必须位于一个可读写的区段中。IL编译器将这个V-表放在了.sdata区段中,不像VTFixup表,后者位于.text区段中。
非托管映像文件的V-表需要完全定义在链接期间,并只需要基本的由OS加载器执行的重定位修正。由于在执行期间没有生成对V-表的改变(正如用托管图像的地址代替方法符号),非托管的映像文件在只读区段中携带着它们的V-表。
非托管导出表
在非托管的映像文件中,这些非托管的导出表占据了一个独立的名为.edata区段。在由IL编译器生成的映像文件中,这些非托管导出表位于.sdata区段中,还附带上它所引用的V-表。
非托管的导出表包括了有关方法的信息——非托管导出文件能够遍历动态链接。非托管的导出表不是一个单独的表,而是一组连续的5个表:Export Directory表,Export Address表,Name Pointer表,Ordinal表和Export Name表。图4-4显示了YDD.DLL模块的导出表之间的联系,它的函数暴露为Yabba,Dabba和Doo。
图4-4 非托管表导出表的结构
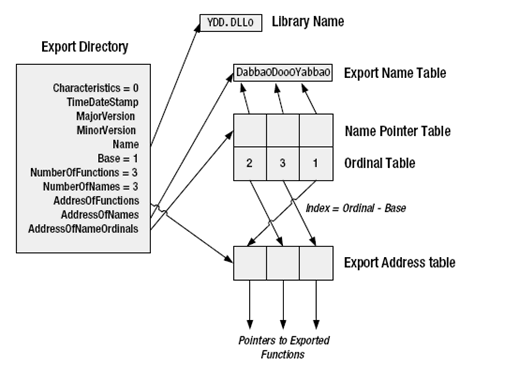
非托管的导出信息开始于Export Directory表,它描述了导出信息的剩余部分。这是只有一个元素的表,包括了位置和其他导出表的大小。这个Export Directory表的唯一一行的结构,定义在如下的Winnt.h中:
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name;
DWORD Base;
DWORD NumberOfFunctions;
DWORD NumberOfNames;
DWORD AddressOfFunctions;
DWORD AddressOfNames;
DWORD AddressOfNameOrdinals;
} IMAGE_EXPORT_DIRECTORY,
*PIMAGE_EXPORT_DIRECTORY;
简而言之,_IMAGE_EXPORT_DIRECTORY字段包括了以下部分:
Characteristics:保留的。这个字段应该被设置为0。
TimeDateStamp:导出数据生成的时间和日期。
MajorVersion:主版本号。这个字段和MinorVersion字段只用于信息;IL编译器并没有设置它们。
MinorVersion:次版本号。
Name:ASCII字符串的RVA,包括了导出模块的名称。
Base:顺序的基数(通常是1)。这是用来导出在映像文件表中的开始顺序的数字。
NumberOfFunctions:Export Address表中的入口数量。
NumberOfNames:Export Name表中的入口数量。
AddressOfFunctions:Export Address表中的RVA。
AddressOfNames:Export Name表中的RVA。
AddressOfNameOrdinals:Name Pointer表中的RVA。
Export Address表包含了被导出为入口点的RVA。一个进入点的导出序号定义为它的在Export Address表中的基于0的索引加上基本序号(IMAGE_EXPORT_DIRECTORY结构的Base字段值)。
在托管的文件中,Export Address表不仅包括了属于导出进入点(方法)自身的RVA,还有非托管导出stub——拥有对这些进入点的方法。(参见本章前面介绍的“文本区段”)。导出stub,按照顺序,包括了对相应的V-表的槽的引用。
在一个Export Address表中的RVA,可以是一个forwarder RVA,识别了一个重导出的进入点——就是说,一个指向这个模块的入口从一个模块导入并导出为其自身。在这种情形中,这个RVA指向了一个包括了导入名称的ASCII字符串。导入名称可能是一个DLL名称和这个导入点(SomeDLL.someFunc)的名称或一个DLL名称和在这个DLL(SomeDLL.#12)中导入入口的序号。
IL编译器并不允许重导出,因此由这个编译器生成的一个映像文件的Export Address表的入口,总是表示了非托管导出stub的RVA。
Export Name表包括了以0结尾的ASCII字符串,表示了由这个模块导出的方法导出名称。严格的讲,Export Name表不仅是一个表,还是一系列以0结尾的字符串。Export Name表中的导出名称按照字母顺序排序,从而使按照名称的二分查找法的入口点变得便利。导出名称可能不同于声明在模块中的方法下的名称。如果一个导出方法是只按照序号导出的,可能根本没有导出名称。在这种情形中,它的序号并不包括在Ordinal表中。IL编译器不允许未命名的导出。
Name Pointer表包括了来自Export Name表的由RVA组成的导出名称。
Ordinal表包括了对Export Address表的2个字节的索引。Name Pointer表和Ordinal表构成了两个类似的数组,并作为一个直接查找表来操作,重新排列了入口以至于它们可以从词法上按名称排序。当一个入口根据名称被识别时,这个二分查找法在Name Pointer表中被引导。如果在Name Pointer表中发现被找到的入口和地址数字N的名称相匹配,这个入口的序号会被从Ordinal表中的元素数字N取出。通过这个序号,这个入口的地址可以从Export Address中重新得到。
第18章检查了非托管的导出信息,以及将托管方法暴露为非托管导出的细节
TLS
ILAsm和VC++允许你定义属于TLS的数据常量并映射静态字段到数据常量上。TLS是一个特殊的存储类,在这里,一个数据对象不仅是一个栈变量仍然还是本地化到每个隔离的线程。从而,每个线程可以为每一个这样的变量维护一个不同的值。
TLS数据在TLS目录中描述,IL编译器将其放置于.sdata区段中。用于32位映像文件的TLS目录结构定义在如下的Winnt.h中:
ULONG StartAddressOfRawData;
ULONG EndAddressOfRawData;
ULONG AddressOfIndex;
ULONG AddressOfCallBacks;
ULONG SizeOfZeroFill;
ULONG Characteristics;
} IMAGE_TLS_DIRECTORY32;
用于64位映像(IMAGE_TLS_DIRECTORY64)的TLS目录的结构是类似的,除了开头的4个字段是8字节的无符号整数(ULONGLONG)取代了4字节的无符号整数(ULONG)。这个结构的字段如下:
StartAddressOfRawData:TLS数据常量的虚地址(是VA而不是RVA)的开始部分。TLS数据常量加上未初始化的TLS数据一起形成了TLS模板。每当一个线程创建的时候,操作系统就会制作一个对TLS模板的复制,从而提供了每个带有“私有”数据常量和字段映射的线程。
EndAddressOfRawData:TLS数据常量的VA的结束部分。TLS数据的结束部分(如果有的话)以0填充。IL编译器允许未初始化的TLS数据,假定TLS数据常量代表全部的TLS模板,因此不会留下什么被0填充。
AddressOfIndex:4字节TLS索引的VA,位于普通的数据区段。IL编译器将TLS索引放入.sdata区段,直接位于TLS目录结构和回调函数指针数组休止符的后面。
AddressOfCallBacks:TLS回调函数指针的一个以null结尾的数组的VA。这个数组以null结尾,而结果这个字段并不是null值并且如果没有指出回调函数的话,就指向一个全部为0的指针。IL编译器并不支持回调函数,因此TLS回调函数指针的整个数组包括了一个null休止符。这个null休止符在.sdata区段中的TLS目录结构之后。
SizeOfZeroFill:TLS模板的未初始化部分的大小,当TLS模板的一份复制被创建的时候,以0填充。IL编译器将这个字段设置为0。
Characteristics:保留的。这个字段应该被设置为0。
StartAddressOfRawData,EndAddressOfRawData,AddressOfIndex,AddressOfCallBacks字段保存了VA而不是RVA,因此你需要在.reloc区段为它们定义基本的重定位。
RVA和TLS目录结构的大小存储在PE头中的第10个数据目录(TLS)中。TLS数据常量,构成了TLS模板,位于映像文件的.tls区段中。
资源
你能够嵌入两种截然不同的资源到一个PE文件中:非托管的特定于平台的资源和托管的特定于CLR的资源。这两种资源,没有什么共同之处,位于托管映像文件的不同区段,并可以被不同组别的API访问。
非托管的资源
非托管资源位于映像文件的.rsrc区段中。开始部分的RVA和内嵌的非托管资源大小,都表示在PE头的资源数据目录中。
非托管资源是通过类型、名称和语言来索引的,它们是二进制的,以这三个特性以及上面的顺序进行分类。一系列资源目录表如下表示这个索引:每个目录表都紧跟着一个由目录入口组成的数组,它们包括了引用数字的整数(ID)或相应级别的名称(类型、名称和语言的级别)和下一级目录表的地址或数据描述(树的叶子节点)。由于使用了这三个索引特性,任何数据描述都可以通过分析至多三个目录表获取到。
在数据描述获取到之前,它的类型、名称和语言都可以从路径中得到,这个路径由搜索算法遍历以达到数据描述的位置。
.rsrc区段有以下结构:
资源目录表和入口:正如之前所描述的。
资源目录字符串:Unicode(UTF-16)字符串代表了通过目录入口寻址的字符串数据。这些字符串是以2字节排列的。每个字符串都在前面加上2-字节无符号整数以表示这个字符串的长度。
资源数据描述:一组由目录入口记录的地址,包括了这个实际资源数据的大小和位置。
资源数据:处于自然状态的undelimited资源数据,由独立的资源数据组成,其地址和大小定义在数据描述的记录中。
一个资源目录表的结构定义在如下的Winnt.h中:
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
WORD NumberOfNamedEntries;
WORD NumberOfIdEntries;
} IMAGE_RESOURCE_DIRECTORY, *PIMAGE_RESOURCE_DIRECTORY;
根据前面关于对非托管资源和资源目录表的构成的讨论,这些字段的角色应该是明显的。一个异常可能是Characteristic字段,这是受保护的并且应该被设置为0。
名称入口,使用字符串来识别类型、名称或语言,直接跟在资源目录表之后。在其之后,存储了ID入口。
资源目录入口(名称入口或ID入口)是一个8位的结构,包括了两个4位无符号整数,在Winnt.h中定义如下:
union {
struct {
DWORD NameOffset: 31 ;
DWORD NameIsString: 1 ;
};
DWORD Name;
WORD Id;
};
union {
DWORD OffsetToData;
struct {
DWORD OffsetToDirectory: 31 ;
DWORD DataIsDirectory: 1 ;
};
};
}IMAGE_RESOURCE_DIRECTORY_ENTRY, *PIMAGE_RESOURCE_DIRECTORY_ENTRY;
如果第一个4位的组件的开始位被设置了,入口就是一个名称入口,并且剩下的31位代表了名称字符串的偏移量;否则,这个入口就是一个ID入口,并且它的16个不重要的位保存了ID值。
如果第二个4位的组件的开始位被设置了,那么这个项,它的偏移量由剩下的31位所表示,是资源目录表的下一级别,否则它就是一个资源数据描述。
资源数据描述是一个定义在如下Winnt.h中的16位结构:
DWORD OffsetToData;
DWORD Size;
DWORD CodePage;
DWORD Reserved;
} IMAGE_RESOURCE_DATA_ENTRY, *PIMAGE_RESOURCE_DATA_ENTRY;
OffsetToData和Size字段刻画了资源数据相应的chunk的特征,这些chunk组成了一个独立的资源。OffsetToData被详细指明相对于资源目录的起始位置。CodePage代码页的ID,用于对元数据中的代码点的值进行解码。通常这是Unicode的代码页。最后,不要在这里感到惊讶,Reserved字段是受保护的并且必须被设置为0。
IL编译器创建了.rsrc区段并内嵌了来自相应的.res文件的非托管资源——如果这个文件文件被详细指定在命令行选项。编译器只可以为每个模块内嵌一个非托管的资源文件。
当IL反编译器分析一个托管的PE文件并找到这个.rsrc区段,它从这个这个区段中读取数据和它的结构,并发布包括了在PE文件中所有的非托管资源的.res文件。
托管资源
CLR头的Resource字段包括了RVA和内嵌在PE文件中的托管资源的大小。这并没有对PE头的Resource目录做些什么,但是它详细指定了RVA和非托管的特定于平台的资源的大小。
在由IL编译器创建的PE文件中,非托管资源位于映像文件的.rsrc区段中,反之托管资源位于.text区段中,和元数据、IL代码等等在一起。托管资源连续地存储在.text区段中。元数据携带着ManifestResource的记录,每一个对应着一个托管的资源,包括了托管资源的名称,以及在CLR头的Resource字段中详细指明的RVA的开始部分距离资源开始处的偏移量。在这个偏移量的位置上,一个4位的无符号整数指出了资源的字节长度。紧跟在后面的则是资源本身。
当IL反编译器处理一个托管的映像文件并找到内嵌的托管资源,它将每个资源写到一个独立的文件中,并根据资源的名称来命名。
当IL编译器创建一个PE文件时,它从文件中读取定义在源代码中的所有托管的内嵌的资源,根据资源的名称并将它们写到.text区段中,每一个都以它们特定的长度作为开始。
作为一个练习,我提议你使用IL反编译器打开任何托管的可执行体(比方说,一个简单的示例),并选择View/Headers菜单进入点。你将会看到所有的头和它们的“field”字段。