https://www.jianshu.com/p/4140be00d4e3
- 题目描述
- 建模方法
- 特征工程
- 我的几次提升方法
- 从其他队伍那里学习到的提升方法
- 总结和感想
- 神经网络方法的一点思考
- 大数据量与分布式计算的一点思考
- 参加比赛和学习知识的对比
- 最后的感受
- 趣事
写在前面
我是一个之前PhD做分布式计算、虚拟机调度,毕业之后年初才转ML的家伙,自恃有点学习开发能力和混迹ICPC竞赛的底子,对数据还有些敏感度,有那么几个可以跟着学习的人,斗胆在5月底开始利用业余时间玩一玩。
最后的成绩是预赛58名,队名robust(预赛结束前一周还混迹在前15名之内的一个队名),滴滴官方在剔除掉前50名的作弊参赛队之后,出乎我意料的没有“扩充”名额,仅41队参加决赛(这和官网上挂出的“50队探索科学边界”的标语形成鲜明对(da)比(lian))。
就是说我的最终排名应该在49名(最差)。所以如果参加了决赛,再让我学习一个月,结果可能还真未尝可知。详情请翻到本文最后“趣(tu)事(cao)”篇。
言归正传,以下介绍题目、方法(包括我知道的一些其他队伍的方法),然后说说我的总结和感想,最后还有一些趣(tu)事(cao)。
因为我最后没进决赛,所以我的总结和感想中会带着很多和我自己方法的对比,以及会着重写一写我自己后来觉得值得学习和改进的东西。大牛们可能会觉得比较弱,可以自行跳过。总体上感觉应该还是比较适合入门级选手。
本文部分图是借用其他队伍的答辩PPT(会注明)。
文中会产生一些不专业不严格的名词等等,还请大家批评指正。
更新:20160929,补充了一大批PPT报告的截屏图片,丰富了一下内容。
更新:20170101,补充了一些关于神经网络方法的想法。从滴滴比赛结束之后我一直在做机器视觉方面的工作,比较集中关注目标检测以及目标检测问题在移动设备上的实时性问题,欢迎感兴趣的同学讨论交流。
可能还会时不时的更新我新学到的东西。
题目
http://research.xiaojukeji.com/competition/detail.action?competitionId=DiTech2016
数据:
- 某市一段时间内(20+天,决赛时更换了数据连同预赛数据一起有40+天的数据)的打车订单日志,包含乘客,司机,时间,价格,起始区域。司机为空代表该单没有被满足。数据量有上千万条。
- 各时段天气信息、交通拥堵信息
- 每个区域POI信息,即该地区的基础设施信息
- test数据集中有被预测时间片的前30分钟订单、天气、交通等信息

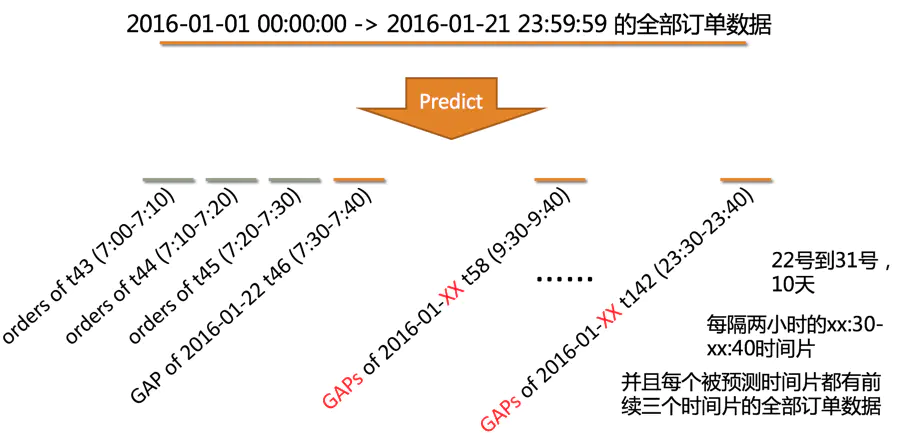
目标:
预测未来某时间(一般是未来十天)区域内打车供需差:即该时间片该区域中总的订单数减去被满足的订单数量。后文会称其为gap值。
猜测动机:
得到供需关系,为合理调度快车司机提供数据支撑。
评测指标:
预赛 MAPE(Mean Absolute Precise Error)
每个时间片每个地区的预测值和真实值差值的绝对值/真实值,最后求总的平均值
决赛 MAE(Mean Absolute Error)
每个时间片每个地区的预测值和真实值差值的绝对值,最后求总的平均值
所有时间片所有地区,取平均时权重相等。

基本解决方法:
预测问题,回归方法
简单评价:
- 我觉得地理信息给的有点少。
- 或许涉及商业秘密。区域间的邻接关系我想还是有些影响。并且考虑交通拥堵信息时,只有起始区域,没有途径区域?
- 区域太大啦,估计有几公里甚至十几公里一个,一个区域内都会经常出现上百块钱的价格。或者说重要区域和非重要区域一样大。即便是预测出来了,指派度是否太过于粗糙?重要区域如果可以分割成更小的区域最好了。
- 评价指标,尤其是预赛的,匪夷所思。
- 预赛的标准是MAPE,在真实值较小的时候预测值变动的影响要远大于真实值较大时候。比如,真实值是10的时候,如果你预测为50,错了40,mape贡献4,但是如果真实值是100的时候,你预测为140,同样是错了40,但是mape只贡献0.4。
这个为什么说匪夷所思呢,因为做比赛时,你难免会去想一些用途方面的问题。如果是这样,那滴滴应该更加在意小gap时的预测?这合理吗?应该是很大的gap预测出来调度大批量的车过去才make sense啊。 - 决赛时,明显官方注意到了这个问题,特征为MEA,因为有绝对值,二阶不可导,倒是考验了一下各位选手,在使用XGBoost的时候该如何处理这个问题。
建模方法
需要设计的无外乎样本,标签,以及验证集。
样本构造的“标准方法”,即被训练时间片的前30分钟(或者20分钟)的特征作为该时间片的样本,而这个样本对应的标签即接下来的10分钟的gap值。
其代表的物理含义是根据趋势进行预测,而不是根据历史进行预测。
后文都将对此方法称为30:10,或者20:10,即代表30分钟样本数据对应10分钟标签数据。
造成这个方法成为“标准方法”的根本原因是因为,只有几十天的数据,如果训练样本中需要用到跨天甚至垮周的数据,势必造成训练样本数量减少,并且没有直接证据可以证明用了跨天或者跨周数据会带来非常好的提升。所以几乎所有取得好成绩的队伍都是使用的该方案。
换言之,从这个数据集的角度出发,我们可以下这样的结论:影响供需的主要因素就是这个时间片前面的20到30分钟的种种特征。
所以最后如果每天有144个时间片,每个时间片都有前20-30分钟的样本,在不扩充样本的情况下每个区域拥有144*21(+24)=3024(6480)个样本,括号代表决赛。

不管是30:10还是20:10,这里面能做的文章还有很多。因为订单信息是精确到秒的,但交通和天气信息大体是按10分钟一个时间片来划分的,所以直观的,就是使用10,10,10:10(就是三个10分钟的综合特征对应10分钟的标签)这样的样本。之所以说他直观,是因为我就是用的这个方法,相当的naive,当时使用的样本数量大概为21w个。
其实,可以做的文章有很多:
- 相对复杂的特征组合:30,25,20,15,10,5:10,20,10,5,3,2,1:10等等。当然,这里的30是包含后边的25的。还有,5,5,5,5,5,5:10,2,2,2,...,2:10等等,这个可以随意组合。
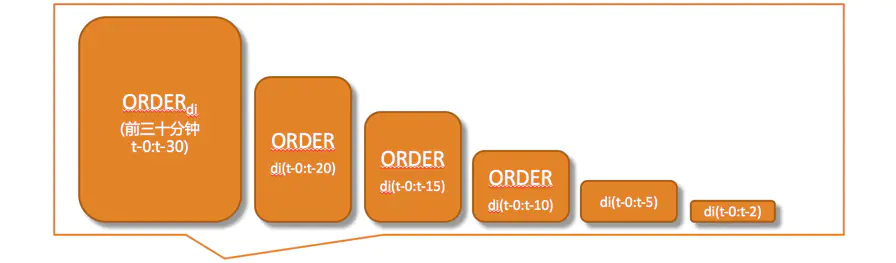
- 滑动窗口:打破10分钟时间片的起始时间,不再拘泥于测试集的整10分钟开始。比如可以是11点7分-27分样本对应27-37分的gap值。滑窗的间隔可以自己选,1分钟,5分钟,这都有人用。但是毕竟滑窗数据存在overlap,使得滑窗格子间存在一定的相关性,同时天气和交通数据需要拟合,都导致滑窗过小效果并不一定好。这个需要谨慎对待。

- 如果使用(<20):10的方案,test集的前三十分钟的数据,配合滑窗,还能做出几个训练样本。不过这个的意义不是特别大。
验证集构造方法常见的有两种
- 使用训练集最后一周的数据
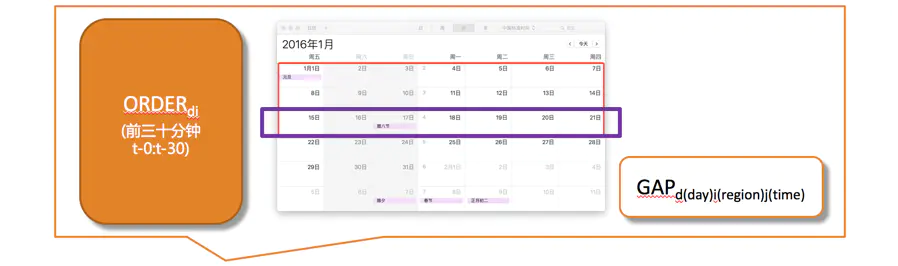
- 使用测试集的最后十分钟数据

事实证明第二种略优一点。虽然使用第二种的代价是训练样本时间从30:10变为20:10,但是事实证明,缩减掉的前30分钟数据对结果影响并不大;相比之下使用训练集最后一周数据则因为不同天反应出的不同特点严重影响验证集效果,造成本地验证效果无法体现在上传结果上。
我的方法在验证集构造上失误了,因为我一直用的第一种方法,略不同的是我选的还不完全是最后一周的数据,而是一个精心设计的验证集,简单说是三个不同训练-验证集交叉验证结果(这么做的原因是因为当时发现1月20号的数据极端诡异,缺数据,数据分布和6/13号两天不同),依旧抵不过使用第二种构造方法。造成我预赛最后几天因为本地验证集合线上测试集严重不匹配,又缺乏经验,各种抓狂,却又无计可施。
特征工程
这里简单描述一下常规的特征工程,复杂的、具有决定意义的特征工程放在下面提升方法中归纳总结时提出。
特征工程是和样本构造紧密相关的。
我的特征最后只有140维左右,加上POI的50维,最多的时候也只有190维左右。并且前140维大部分是前30分钟3个时间片的重复特征。基本的特征大概是50维左右。
- 交通信息,直接对应到样本的每个10分钟时间片中。
- 天气信息,类型按one hot feature,01化之后作为几维特征,温度和PM2.5直接对应到时间片中。
- 订单信息,我的特征相对较少,主要集中在前3个时间片的需求总量、供给总量、司机个数(接单/空单)、乘客个数(接单/空单)、目的地个数(接单/空单)、价格总和(接单/空单),以及该区域作为目标区域对应的一些个数信息等等。这些特征简单说都是低阶特征。
这里的经验教训是这样的,通过查资料和跟别人学习探讨,我当时的确是已经已经知道了要使用高阶特征的。但是由于已经体现出的成绩相对还好,同时还有很多可以优化的地方,增加高阶人工特征就被拖后了很多,这是经验问题。并且,单个特征的增加,往往没有什么太多助益,但上百维特征组合起来对结果的助益才很大,当时并没有意识到,这就使得继续增加特征的动力变得比较小。
相对扩展的特征以及我后来学到的特征会在后边几节详细介绍。
我的几次提升方法
- 目标函数映射
因为预赛的评价指标是MAPE,而我用的XGBoost的目标函数是线性的(小声说,其实一开始我还不知道要去修改目标函数,后来知道了也不知道怎么自定义目标函数。不过还好,现在都学会了),所以想了一种映射方法,即把标签取log,然后预测完之后把结果取power。
这个改进非常有效果。其物理含义是重新拉伸了目标值域的数据分布,增加了小数据预测时的敏感程度,放松了大预测值的精度。我前面有讲,因为MAPE本身对小数据敏感,这个改进那是相当的make sense。
直观上,决赛修改成MAE之后貌似是不需要再修改映射关系了,但是据说有的队在决赛时候同样通过这个映射完成了提升。我猜测是因为gap值本身成指数分布,对小值预测敏感一些就合理了。
-
样本集构造方法改造
一开始我使用的样本不是前文所谓的“标准方法”,而是使用了跨天垮周的数据,即一开始我认为,可能上一个星期同一天,也就是七天前的相同时间片,会对被预测时间片产生影响。因为样本数据量太少,最终放弃。放弃之后效果飙升。 -
对地理区域进行聚类后分开模型训练
其实这应该是一个有效的方法,如果能对区域进行有效分区的话。因为不同区域用户行为、基础设施、拥堵情况的差异巨大。如果能找到有效的聚类方法,是一个不错的提升途径。例如,最终第三名队伍blitz给出了一张非常形象描述区域时间-订单数量pattern的图片,并大胆猜测了这几个区域的属性。
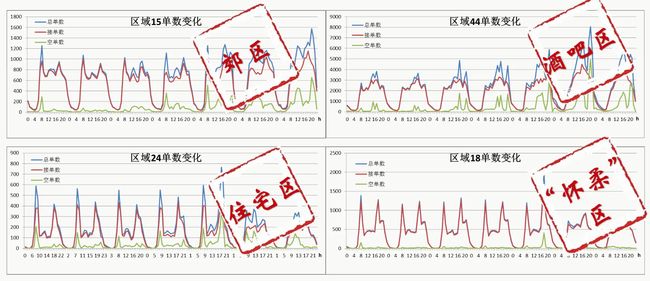 blitz队提供的不同区域订单情况的数据可视化图
blitz队提供的不同区域订单情况的数据可视化图我预赛set1的时候,我使用了区域聚类的方法,但是具体的聚类方法应该是碰巧了,而这个方法在预赛更换数据set2之后失效了。
另外,因为区域太大,这造成区域聚类时,拥有共同特征的区域就会比较少,如果区域还可以细分,效果会更好。 -
我所使用的具体的聚类方法是:
简而言之,对特定的特征集,根据XGBoost输出的importance score,进行KMeans聚类。即特定特征集下表现相似的区域放在一起再重新训练。
存在的问题是,因为特征维度比较高,聚类时,每一维特征的权重却被设置为相同,导致比较强的特征对聚类结果影响没有被突出。 -
事后考虑:分区域聚类是个正确的方向,前提分开之后的区域,样本量要足够大。而对区域进行聚类的指标也是一项独立的特征工程,比如区域的拓扑关系,区域流向关系,区域的POI信息,区域在不同时间的活跃程度。
-
特征工程
-
价格因素。因为原始数据提供的价格信息中加入了滴滴策略,例如优惠劵、用户加价等,而最后仅保留了一个最终的落地价格。所以道理上不能通过简单的价格来作为特征,不过因为我没有怎么使用高阶特征,我直接使用的价格特征在XGBoost的importance中比重还比较高。
这里讨论一下价格因素的可能使用方法:1)可以分析区域间的相对距离关系;2)用来粗略估算订单完成时间,从而获得司机的空单时间的统计信息;3)用户价格偏好。 -
后来去掉POI信息在我这里也是一次提升。
POI信息真的不知道该怎么搞,或许可以用在对地理区域进行聚类上面。 -
XGBoost的importance分析。
发现importance的高低只是代表这个一维特征在学习过程中对XGBoost结果的影响程度,但是这种影响有可能是正的,也可能是负的。所以会交叉验证importance比较高的特征,如果发现是毒特征,就直接去除。 -
比较遗憾,我没有想到时间片结束时空单量这个重要的影响因素。我现在觉得这可能是一个直接影响成败的特征。回看自己的方法,其实我的特征有一维,代表刚刚过去的10分钟中的空单量。这个量太过于简单了,因为我没有区分这10分钟结束时的已经被满足和仍未被满足这两者。
以blitz队的数据分析来说,blitz队通过数据分析发现,一般空单之后两分钟会重新发单,如果还没有被响应,再次发单的时间会在五分钟。这与滴滴打车APP的策略相关。滴滴叫车之后2分钟才可以再次发单而再次发单的单优先级高因此,(t:t-2)的空单数,是一个和GAP高度相关的参数。
所以,用前10分钟的空单数作为一个特征,在这样的数据分析下就显得实在是太过于粗糙了。
 blitz队提供的空单再满足数据可视化图
blitz队提供的空单再满足数据可视化图 -
数据后处理
数据后处理是建立在对自己方法得到结果的分析前提下的。
例如,分析数据时我发现,周一到周五的第94号时间片,即工作日的下午15点半,预测值一直偏大。如图表示我的方法对1月11号星期一(左图)和1月13号星期三(右图)的预测结果。横轴表示时间片(4代表第5个即94号时间片),纵轴代表区域。红色代表我预测的结果比真实值大,蓝色代表我的预测小。圆大小代表相比真实值的比例,黑色代表真实值大小。所以94号时间片就显得非常奇葩。
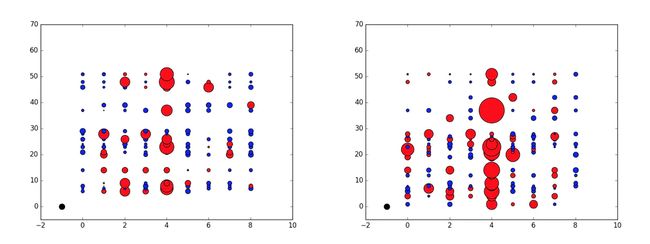
最后我使用的方法是人工对周一至周五的94号时间片的预测值除以一个经验值。该经验值是统计结果,最后我取了4。
并且这里我还想讨论一下这种后处理的方法。总觉得是一种没有道理,又比较low的方法,
我在这个时间片上花了很长时间,这就是经验问题了,其实应该把有限的时间用来加强模型和特征,而不是一个单一的畸变数据上。 -
还存在代码写错了,但是结果又提升的情况。这个因为觉得是bug,没记笔记,忘了是什么了。其实搞不好还有的挖。
其他工作:
- 验证集预测结果分析。也就是前文的5. 数据后处理,还有一些其他的繁琐的分析,主要集中在和真实结果的比对上,我并没有统计出什么太多规律出来。
- 极端天气影响。因为事先分析了天气气温对应的城市信息,知道比赛选择的城市是杭州,所以对杭州1月份的极端天气进行了了解,不过比较不幸的是,极端天气正好都发生在test集的几天。所以并没有什么太大的帮助。
- 预测需求-预测满足率的双模型,但是这个是很快就被抛弃的一个改进,因为会造成误差累积,这个比较基础了,没啥好说的。
这个领域,不经意的一个小改动可以大幅提升效果,而费尽心思的一个很大的改动可能并不能起到什么效果,甚至是负效果。但是你不尝试不知道,甚至有可能有理论或者感觉可以支持一个改动,但是有可能实现完还是会没有用或者负作用。尤其是在特征工程中,只提取几个简单特征可能会带来一定的提升,当继续增加特征时,效果可能越来越不明显。但是这时,可能最有效的提升就是由一点又一点的特征积累得到的,尤其是越来越难以想到的,隐含的越来越深的,那些高阶特征。
是的,这是一个磨炼耐心的过程,一个“修行”的过程。
从其他队伍那里学习到的几个提升方法
以下的方法都不是我自己实践的,结合通过各种渠道获得的信息,加上自己的理解,先把干货抛出来,希望可以和大家共同讨论。
- 特征统计属性
从最终比赛成绩来看,仅使用XGBoost+特征工程确实可以做到前几名。但是这样做做的最好的队伍,在特征中融合了大量的统计特征,这与他们拥有坚实的经济学、统计学理论背景是有分不开的关系的。
- 高阶特征的建立技巧,比如用最小二乘拟合统计信息。
高阶特征可以被认为是一种超越单一视角的特征。
对特征的详细分类,以及对每类特征物理含义的深入理解。会有助于寻找更多的特征。 - 对于赛题,常见的分类方法一般是实时特征、历史特征、趋势特征、临近特征,等等?这些名词是借用的其他队的说法,对特征的一种粗略的分类吧。另外我觉得主要还是统计信息,或者是统计信息的统计信息,或者是多个不同维度统计信息的交叉统计信息。
- 实时特征好理解,就是某个时刻当下的特征,特征值可以直接作为一维特征使用。个人认为,实时特征即简单特征,而其他三种特征则是高阶特征。
- 历史特征,是指某个时间之前的某个信息维度上的信息统计量。由于这个问题的样本建立方式,使得历史特征也只能在预测时间之前30分钟或者20分钟中进行提取,这使得历史特征这个词变得不是很名副其实。
- 趋势特征,是指根据多个历史特征获得的变化速率信息。例如,我们通常会直接使用level=x (x=1->4)的拥堵路段的数量作为特征,如果是用了本时间段level=x和上一个时间段level=x数量差的话,这个数量差就是一个趋势特征。
- 临近特征,我觉得可能是趋势特征的一个临近特例。这儿我理解的不太到位。
- 样本扩充
通过滑动窗口获得更多的信息量。这里我其实是有一些疑问的,就是10分钟的区间,用1分钟或者5分钟的滑动窗口去滑动,存在多大的线性相关性的问题。这取决于统计性特征的特点,如果统计性特征统计的是这10分钟的总和或者是变化曲线,或许5分钟的滑动窗口的效果会比1分钟的好,因为1分钟可能重复了太多的冗余信息。 - 详尽的数据分析和可视化分析
这个就不展开讲了,总之很重要,是帮助做出下一步决策的重要辅助手段。 - 必要的数据清洗
需要花费很大的精力去找出“毒样本”,或许和意外情况有关系,或许和特殊情况有关系,或许和社会新闻事件有关系。
比如前文所言的极端天气。再比如当时我猜测是否与杭州当地大学、大专院校放寒假时间有关系?那么,放寒假究竟是特殊情况,还是深层规律并不差别的普通情况,或者还是可以挖掘出一个新的特征维度?我觉得需要把这部分数据单独进行处理,隔离实验,并进行对比实验,分析和回答以上的问题。比赛时间有限,没法对这些问题逐个验证,并且我觉得我还没有完全掌握处理这些数据的经验吧。 - 目标函数的重要性,这个和下面一个问题合在一起说。
- 对XGBoost或者其他树模型、以及神经网络等分类回归器本身深入理解并修改模型方法
XGBoost是一个被广泛接受的工具,唯一的美中不足是目标函数必须二阶可导,如果目标函数二阶不可导,就必须使用近似函数,这势必影响最后的精度。
那么解决方法就集中在,改进XGBoost,或者换成其他回归器。
其实,XGBoost并不是万能的,改进开发新的决策树模型,找到一个最适应问题本身的模型,确实是王道。
其他回归器的重要candidate,就必须是神经网络了。
我自己的总结和感想
- 用来实现回归的方法主要还是:决策树和神经网络两大类。
-
决策树大多使用XGBoost,而神经网络的方法则比较丰富多彩。神经网络又分为人工特征+神经网络做回归和神经网络自动提取特征两类。
-
决策树方法本身的结构、学习方法、性能特点,对结果的影响还是比较大的,我个人觉得取得第一名的inferrr的核心提升能力在其自身提出并开发的决策树模型上面。如果可以深入了解和理解XGBoost本身,再针对问题作出相应的调整,是可以有效提高预测方法的能力。(10月18日更新:inferrr团队成员的开源GBDT/GBRT/GBM/MART框架,但是我并不确定这就是用在比赛中的方法哦。 https://github.com/Microsoft/LightGBM )
-
可以用来解决的方法有很多,MLP、one-shot memory network、dnn、feedforward neural network,等等。
-
从时间消耗和能源消耗的角度来说,并且限定在滴滴比赛的量级下,XGBoost比神经网络拥有非常大的优势。
-
两个东西都用,然后模型融合其实是个不错的选择。
-
人工特征还是影响方法效果的基石 @:
(@标的几点在前面介绍方法时进行了展开说明) -
数据可视化对人工特征的提取贡献很大。
-
关键特征和问题紧密结合的。比如时间片中的最后一个空单数量,是极容易影响结果的gap值的。这个特征几乎所有取得好成绩的队伍都用到了。
-
高阶特征提取。而高阶特征中的统计特征提取,是很重要的一类特征。统计量的选取也很有学问。
-
one-hot特征的使用。
-
目标函数的重要性 @:
-
一般的,目标函数直接作为分类回归器的目标函数,构造end-to-end的训练方法。XGBoost因为引入了二阶导数,因此需要损失函数必须二阶可导,一般强行使用XGBoost时需要使用近似函数。
-
而如果自己设计回归器,就可以做到end-to-end。
-
根据label的数据分布修正目标函数,例如比赛中,可以对label取log(预测结果取power)的方法,修正目标函数。这个修正方法简单说对MAPE有重大修正作用,同时对MAE也有一定修正作用。
-
样本构造、验证集构造的方法和技巧 @:
-
利用滑动窗口增加样本
-
选择不同的验证集方案和交叉验证方法
-
Domain Knowledge的重要性 @:
-
专业领域的知识,对构建更加贴合实际应用的特征有非常大的帮助。
-
不同队的方法差异真的非常的大,除去大的样本构造、验证集构造等大的方面,方法细节上、特征工程、神经网络的网络结构都各自不同。同时,各自认为提高成绩的关键因素也不一样,对各自方法优势的理解也不尽相同。
-
排名靠前的队伍在比赛结果上其实还是差不太多,而大多数又难以突破最终的一个极限。
-
不知道决定这个极限的原因是什么,是数据的信息量,还是方法的限制?
-
而以上前几点所提到的方法,对前面几名的结果的贡献,往往是方方面面的,可能是MAPE的1e-3,也可能只是MAE的1e-1。甚至,有些改进方法在某些大方法下有可能是相反的贡献。
-
参赛团队的组建和分工,以及团队头脑风暴的重要性。
-
团队协作这个事情,这次没什么发言权。本来拉了几个师弟和同事一起,结果因为各种原因,后边就是我一个人再弄了。一个很明显的感觉就是因为是一边做一边学,也没有经验,就没法去分配给别人任务。但这显然是个短板。
-
人工特征提取是一件很容易掉到牛角尖里面去出不来的过程,可能事后看,就是一个很简单的东西啊,为什么我当时没想到呢?而解决这个问题的方法就是头脑风暴,对应回机器学习的方法,相当于增加一些随机梯度,让人可以从局部极值中震荡出来,再回头去看看有没有全局极值。
-
方法框架的灵活性。
-
决定着新想法付诸实施的速度。因为有的时候你的想法可能对于你之前的框架是颠覆性的。有可能是样本集验证集构造框架,有可能是数据结构框架,也有可能模型框架。如果每次都要改很久或者很麻烦,有可能会降低你修改方法的积极性,很可能就错过了一次重要的优化。
-
在比赛有限时间内,或者说有限的时间内有效的解决一个实际问题时,经验是很重要的,对做出正确决策是很有帮助的。
-
比赛最终的前几名都是有着各类大数据比赛丰富经验的,比如在阿里天池、kaggle等比赛都取得了很好的成绩。
-
在线的大数据比赛一般时间周期比较长,如何协调有限的业余时间,在决策时间做出相对较优的决策,都需要经验来判定当前面临的主要问题究竟是什么。不然只能选择相信自己的直觉,庆幸的是我自认为直觉还可以,仅仅可以而已。这或许就是大牛们所说的对数据的“嗅觉”吧。
-
代码实现快也是一项优势。因为又有工作时不时的还要出差,所以有了想法快速实现并且保证每天都有新鲜东西并能在线上测试集中跑一把,代码实现上就绝不能有所耽误。
-
我自己值得检讨的是,因为python的不少很优良的数据处理库,比如pandas等等不熟,初始代码时没有使用,导致后边迭代成本越来越高,有的改动需要对数据架构进行重构时,确实明显体会到一直因为改起来麻烦改完收益不明确的无力感和惰性。
神经网络方法的一点思考
我的感觉是大部分人使用神经网络还是作为一个替代决策树的回归器,真正使用神经网络来提取特征的队伍少之又少,能掌握这项技术的人也不多。
另外我的感受是,神经网络的效果还是很不错的,但是在这个问题本身看,其单位功耗创造的价值则远小于决策树模型。
这个问题同时存在于非图像语音自然语言处理等数据挖掘领域,即便是在这几个神经网络大放异彩的领域,传统方法在移动计算等方向上,因为计算成本的要求,依旧有着巨大的生命力。
当然,这不代表神经网络不重要,或许某一天,随着硬件成本的下降,算法能力的提升,这些问题就不再是问题了。
----170102更新分割线----
滴滴比赛结束也有小半年时间了,这段时间做了不少神经网络方面的工作。简单总结一下,以CNN为首的这一波深度学习大潮,我认为核心带来的应该是简单特征的非线性组合关系和对有用特征的筛选能力上。
如果我们处理的是图像,那么像素值就是简单特征,那么多层卷积层之后得到的特征,就是简单特征的非线性组合。简单特征相对比提取后的特征,虽然特征表达能力不行,但是保留了最多的信息量。同时,神经网络对简单特征的非线性组合关系是多层的,非线性叠加非线性,从使反向传播机制获得的特征,其所能表达的事物和描述的能力,都是人工特征所无法比拟的。由于无用特征往往在训练过程中因为权重调整已经被“过滤”掉了,因此,由非线性组合出来的高层/深层特征,也使得后续分类/回归器再整个模型训练过程中变得较传统方法没有那么重了。
回到滴滴比赛,以及类似的有已经较为抽象的特征(订单信息、时间信息、天气信息、交通信息等等)的问题上,神经网络依旧可以发挥其对简单特征的非线性组合能力。不同的是,第一,这类问题的简单特征本身已经不再简单,换言之,这类特征是已经被组合过一次了的,因为他们可能本身就已经是统计性的信息,丢失一些只有简单特征才有的信息,类比图像里面像素级的信息;第二,在这些特征中组合出来的更加复杂的高维特征,因为维度较高,其可解释性较差,很难加入领域相关的先验知识进去,而组合过程的盲目性较大,导致真正有用的高维特征难以被筛选出来。反而是传统人工特征方法在比赛这样的数据量级下面并不输给神经网络。
另外,由于本届滴滴比赛里面人为刻意略掉了地理位置信息,相当于扔掉了一块很大的空间信息,而卷积神经网络本身是强在处理空间数据的,这也是传统特征工程可以不输于神经网络的一个重要原因。
----170102更新end----
利用深度学习来进行时空数据挖掘,这个领域也是由来已久。如果我们把一个城市平面当成是一张图,而把时间序列看做是多张图组成的一个视频,那么就可以相应对交通拥堵、流量预测、订单预测等问题进行建模了。
这里推荐两篇文章:
讲堂|郑宇:多源数据融合与时空数据挖掘(上)
讲堂|郑宇:多源数据融合与时空数据挖掘(下)
----170426更新end----
大数据量与分布式计算的一点思考
因为比赛只提供了预赛21天,决赛24天,单个城市(某一线城市)一共45天。相比滴滴公司的日常数据量,因为没关注商务方面,所以简单猜测全国大小城市应该都覆盖过去了,应该有相当于至少一百个一线城市的量(不负责的猜测),每年产生365天的数据。
相比比赛的数据,一年的数据就相差了至少3个数量级,同时还是增量的,流式的,这很可怕。
同时,这个比赛的供需问题,仅仅是滴滴日常面临的问题中,可能还是相对比较不紧迫的问题,之一。因为不同问题对数据的需求不一定相同,用到全部数据的方法不一定比例特别高,但是完全可以猜测,这么大的数据量,同时去处理这么多的问题,真的是世界级的难题。当然我这么猜测的主要原因主要还是因为坊间分布式架构大牛的跳槽。
参加比赛和学习知识的对比
参加比赛时间紧,有压迫性,好玩有趣,因此有动力去搞。但是往往目标单一,一切需要掌握的东西都围绕着比赛目标出发,在整个知识体系中,是一条线而不是网络和体系。
这种方法是从实际问题出发的,会去找到问题本身的特性,针对其给出方法和优化,重点是把掌握的知识和实际问题相结合。
这种方式进行学习,适合初学入门的人快速切入,但是随着比赛次数的增加,你每次能从比赛中学到的东西会相对越来越少。即便运气好,你也几乎不可能完全通过比赛来完善自己的知识体系。
而日常学习知识则正好相反,时间宽裕,但是往往需要自己编织知识网络,因为经常要深入一些看起来没有用的小知识点,必然枯燥无味,容易懈怠,会混沌会茫然会停滞不前。
这种方法的研究手段也不一样,往往从一篇paper或者是已有模型/算法,通过理论或者推导,找到其不足的地方,再去优化。处理的往往是一个泛化的问题,从解决一个具体的问题升华到了解决一类问题上面去。
这种方式,学到的知识相对系统,完整。日后随时随地用起来的时候引经据典,信手拈来,驾轻就熟,讨论起来的时候拍案惊奇,舌战群儒,滴水不漏。不过也容易走过头变成纸上谈兵。
所以,两者相结合也是极好的。通过比赛发现问题,通过问题作为切入点展开学习,最后再通过比赛查漏补缺。
所谓学而不思则罔思而不学则殆是也。(这里学代表学习知识,思代表动手实践得到第一手资料)
最后的感受
从一点不会,到一步步分析问题,分析数据特点,思考解法,设计模型,学习算法,编写代码,加进新想法,分析结果,尝试不同的方法,提交,等待结果时的紧张和兴奋,与其他人交流时的倾听与学习,看到了一次又一次突破性方法带来的成绩提升,也曾为了能突破11名进入第一页苦苦拼搏。
我的比赛其实在6月20号就结束了,细看看,从5月26号下载数据开始的一个月很充实,吃饭在想,睡觉在想,出差在想,崴了脚还在想。时间过得很快,有一种沉浸其中的感觉,我想这是我很久以来没有找到的一种感觉了,一种当年参加ACM竞赛时的投入感,第一次实际把学到的机器学习的东西付诸实践,也算是去尝试解决一个实际的问题。很久没有实际解决真实问题了,确实很兴奋。
趣事
我是一个之前PhD做分布式计算、虚拟机调度年初才转ML的家伙,自恃有点学习和开发能力,有点对数据的敏感度,有几个可以跟着学习的人,斗胆在5月底下载了滴滴比赛的数据,因为一开始先拿到了师弟天池比赛预测的方法和一些基础代码,所以决定利用业余时间好好学习一下这个领域。
一开始并没有太多想法,但是随着几次比较大的优化,比如重建样本集和映射目标函数两个大的优化,大概在6月3日左右就爬到了33名,当时着实被惊到了,真的是没有想到。其实我觉得真实原因必须是因为我的队名起的好,因为我用了早年参加ACM WF时的队名robust,如果实在不是那就一定是因为那天是我家崽崽一周岁生日的原因。
反正,总之,这个时候自己的学习热情已经全部被激发了起来。6月8号报名截止时一口气冲到11名。12号test数据切换完之后,一度掉到30+名,但是简单调整之后14号又重新回到13名,这时候觉得进复赛应该是没问题了。
因为毕竟可以多一件衣服,想到自己最近正好没钱买T恤衫了,想想还是非常非常有价值的。可能是被免费衣服搞兴奋了,结果15号去南京农大踢球的时候被人一个飞腿铲崴了脚,然后在南京某酒店床上躺了十天,最后竟然是坐轮椅在机场辗转回到长沙家里。
短暂恢复两天之后,在酒店床上完成了最后几天的比赛。但是这时候出现了比较严重的问题,应该是验证集选的不好,导致本地优化完全体现不到线上去,成绩一直没有超越过14号的成绩,需要大家脑补一下的曲线是这样的:14号13名,15号16名,16号22名,17号33名,18号58名。

如果非要说这个曲线是正常的,杀进去的人都在最后时刻实力爆发,作为从中学就开始参加信息学竞赛、ACM退役之后又当了N年教练、组织过不知道多少比赛的我,是断然不会相信的。更何况这次决赛仅取前50名,而刚刚好又是我自己跨越了这个门槛。但是当时天真的我竟然相信一定会有个好的答复,衣服啊。
按照组织比赛的经验,网赛结束前一般都会出现诡异现象,其实是人性使然,也无可厚非。网赛作弊一是代码拷贝(或者小号),二是思路分享。第一种好检查,比对代码即可;第二种没办法。但是一般网赛后边都是现场赛,一般是适当按照相对公平的标准,在现场赛能容忍的前提下扩大一定的范围,你先进来,但是现场赛真刀真枪不会再任你胡作非为。
当然,肯定不能拿ACM竞赛来简单对比这种实际的比赛,毕竟大公司比赛的题目更加实际、比赛时间更长、赛事保障更加复杂。每个队的方法都不一样,单单代码复现这件事就意味着需要有大量人工投入进来,对于一个迅猛发展起来的大公司,嗯,也许大概的确可能还是有点紧张吧。
只对比几个能对比的吧,小号,代码拷贝,模型分享,思路分享。当然官方也意识到了这些问题,前一百名都被要求提交文档,没提交的肯定就是前三种,而第四种一样的没办法。
当然,我就寄希望于他们宁可放过一千也不愿错杀一个,毕竟办比赛的真实目的是为了扩大公司的影响力和招人,迫切需要解决的问题也一定不会通过比赛来解决。但是,多放进些人来,是一定可以扩大愿者上钩的范围的。哎,我替它考虑这干什么,还不是为了那件衣服。
万万没想到
滴滴官方最后的做法是这样的:预赛的实际排名前50名卡死,再去除小号,最后只剩41名。

顿时有一种说不出话的感觉。
不难受是不可能的。
用大脚趾头想都能想到,递补9个,无论我前面还有没有小号,我都可以进决赛啊。
然而
没有递补
没有递补,就没有衣服了啊。。
不过,
组委会后来终于在我的追问下告诉我说,衣服还是照送的,提交了文档的都有。哎,就是嘛,就当是给打车乘客的补贴嘛,小场面小场面。一颗悬着的心终于落地了,目的达成。
截止发稿,已经收到滴滴寄来的参赛纪念衫。
感谢wyz、gxz、lmn、xtt、qz等队友。
感谢一剑风吼,threshold等队提供的算法交流。
感谢Blitz队,提供的数据和丰富的图表。
感谢帮助过我的人们。
感谢滴滴。http://research.xiaojukeji.com/competition/main.action?competitionId=DiTech2016
很多人留言问数据:
链接: http://pan.baidu.com/s/1nv2aY5z 密码: 7ce4
只是不知道有没有侵权,如果有请告知我删除。
To be continued when 我什么时候再想到点什么的吧
作者:刀刀宁
链接:https://www.jianshu.com/p/4140be00d4e3
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。