一个实例掌握tensorflow版本 LSTM(持续更新)
基于LSTM的大规模资金流入流出的大数据预测实例
目录:
一:数据预处理
二:构建神经网络
三:训练神经网络(神经网络的保存)
四:使用LSTM算法进行预测(神经网络的恢复)
前言:
作为一名大二的学生,接触ML&DL的时间也还没超过一年,写下博客只是用于记录自己的学习成果,以方便日后查找、应用,水平及其有限,不讳言很多东西都是CTRL+C 、CTRL+V的,但我会尽量写下我在学习过程中遇到的难点或者说是困惑点吧,并记下我的解决方法。
阅读完本文后你将会掌握:
- 如何将原始数据转化为适合处理时序预测问题的数据格式;
- 如何准备数据并搭建LSTM来处理时序预测问题;
- 如何利用模型预测。
项目说明
【问题说明】
蚂蚁金服拥有上亿会员并且业务场景中每天都涉及大量的资金流入和流出,面对如此庞大的用户群,资金管理压力会非常大。在既保证资金流动性风险最小,又满足日常业务运转的情况下,精准地预测资金的流入流出情况变得尤为重要。通过对例如余额宝用户的申购赎回数据的把握,精准预测未来每日的资金流入流出情况。对货币基金而言,资金流入意味着申购行为,资金流出为赎回行为。命题中使用的数据主要包含四个部分,分别为用户基本信息数据 user_profile_table、用户申购赎回数据 user_balance_table、收益率表 mfd_day_share_interest 和银行间拆借利率表 mfd_bank_shibor。数据下载戳 ,提取码:79c2
【用户期望】
期望通过对例如余额宝用户的申购赎回数据的把握,精准预测未来每日的资金流入流出情况。对货币基金而言,资金流入意味着申购行为,资金流出为赎回行为。通过提交结果表 tc_comp_predict_table,对每一天对申购、赎回总额的预测值,金额数据,精确到分。【开发说明】
期望选手对未来 30 天内每一天申购和赎回的总量数据预测的越准越好,同时考虑到可能存在的多种情况。晾一张预测图(蓝色为真实值,红色为预测值)
bule:true dataset red:predict
为什么选择LSTM(Long short-term memory)?
- LSTM网络用来处理带“序列”(sequence)性质的数据。比如时间序列的数据,像每天的股价走势情况,机械振动信号的时域波形,以及类似于自然语言这种本身带有顺序性质的由有序单词组合的数据。
- LSTM本身不是一个独立存在的网络结构,只是整个神经网络的一部分,即由LSTM结构取代原始网络中的隐层单元部分。
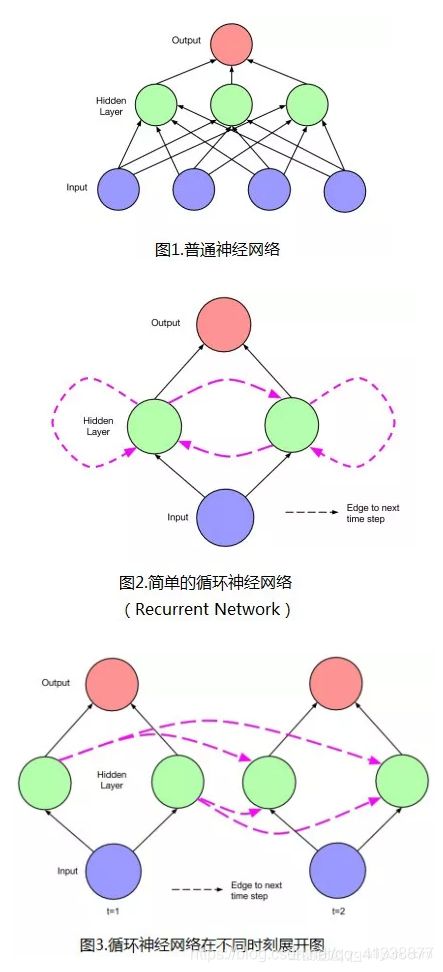
- LSTM网络具有“记忆性”。其原因在于不同“时间点”之间的网络存在连接,而不是单个时间点处的网络存在前馈或者反馈。如下图2中的LSTM单元(隐层单元)所示。图3是不同时刻情况下的网络展开图。图中虚线连接代表时刻,“本身的网络”结构连接用实线表示。LSTM网络最大的特点就是它有输入门、输出门、忘记门三个控制单元(“cell”),随着信息的进入该模型,LSTM中的cell会对该信息进行判断,符合规则的信息会被留下,不符合的信息会被遗忘,这使得它对时间序列的的数据有趋势“记忆”以及预测的能力,大量的训练数据可以使模型“记忆”每年、每月、每周的数据趋势,或者说具有周期性的趋势,这样可以提高时间序列数据预测的准确性。
如果您对LSTM原理还不太理解请戳:理解LSTM原理
一、数据预处理:
打开dataset你会发现有5个cvs表格
但是本例只用到一个表格,就是用户申购赎回数据(user_balance_table.csv)
列名
类型
含义
示例
user_id
bigint
用户 id
1234
report_date
string
日期
20140407
tBalance
bigint
今日余额
109004
yBalance
bigint
昨日余额
97389
total_purchase_amt
bigint
今日总购买量 = 直接购买 + 收益
21876
direct_purchase_amt
bigint
今日直接购买量
21863
purchase_bal_amt
bigint
今日支付宝余额购买量
0
purchase_bank_amt
bigint
今日银行卡购买量
21863
total_redeem_amt
bigint
今日总赎回量 = 消费 + 转出
10261
consume_amt
bigint
今日消费总量
0
transfer_amt
bigint
今日转出总量
10261
tftobal_amt
bigint
今日转出到支付宝余额总量
0
tftocard_amt
bigint
今日转出到银行卡总量
10261
share_amt
bigint
今日收益
13
category1
bigint
今日类目 1 消费总额
0
category2
bigint
今日类目 2 消费总额
0
category3
bigint
今日类目 3 消费总额
0
category4
bigint
今日类目 4 消费总额
0


1、原始数据集粗处理:先除去14个月总操作数记录低于5次或者总申购值和总赎回值低于10次的用户,
2、剔除无用数据和缺少值处理:检查是否存在缺失值(可以很容易发现这是上表是缺值的)
3、离散化、标准化和均衡化
分别对总申购值、总赎回值按天进行汇总,得到1个2x427维的数据集
在427天中选取一个连续的30天作为测试集(test-data),剩下的作为训练集(train-data)
需要对数据进行预处理,包括:噪音清洗、归一化、编码等
在本例中,作为一个小白,我先试用来,Keras的lstm直接建模,但是在反归一化的时候遇到了关于维度的问题,一时半会没能解决,所以曲线救国我尝试了tensorflow版本的LSTM,算是成了。废话不多说,开始吧!
第一步是将数据以日期整合到一起以便我们可以将日期用作Pandas的索引。
在数据集中还有几个分散的“NA”值;我们现在可以用0值标记它们。
code1: Load_Dataset
# Mingjoy/ 2019/4/20 # -*- coding:utf-8 -*- import matplotlib.pyplot as plt import pandas as pd # Load_dataset user_balance = pd.read_csv('user_balance_table.csv', parse_dates = ['report_date']) timeGroup = user_balance.groupby(['report_date']) # groupby()聚类函数,将数据日期整合 purchaseRedeemTotal = timeGroup['total_purchase_amt', 'total_redeem_amt'].sum() # 累加每一天的申购、赎回总值 purchaseRedeemTotal.plot() plt.show() # Save file purchaseRedeemTotal.to_csv('purchaseRedeemTotal.csv')
为了便于理解LSTM我们先使用一个特征输入,把每日 total_purchase_amt 作为输入特征[x],后一天的最高价最为标签[y]


#!/usr/bin/env python # -*- coding:utf-8 -*- import matplotlib.pyplot as plt import pandas as pd import math # load data(user_balance_table.csv) user_balance = pd.read_csv('user_balance_table.csv', parse_dates = ['report_date']) timeGroup = user_balance.groupby(['report_date']) # groupby()聚类函数 purchaseRedeemTotal = timeGroup['total_purchase_amt', 'total_redeem_amt'].sum() purchaseRedeemTotal.plot() plt.show() # save to file purchaseRedeemTotal.to_csv('purchaseRedeemTotal.csv')tensorflow.python.framework.errors_impl.
代码2
#!/usr/bin/env python # -*- coding:utf-8 -*- import numpy import matplotlib.pyplot as plt from math import sqrt from numpy import concatenate from matplotlib import pyplot from pandas import read_csv from pandas import DataFrame from pandas import concat from sklearn.preprocessing import LabelEncoder, MinMaxScaler from sklearn.metrics import mean_squared_error from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM import math # 将序列转换为监督学习问题 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols, names = list(), list() # input sequence (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)] # forecast sequence (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) if i == 0: names += [('var%d(t)' % (j + 1)) for j in range(n_vars)] else: names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)] # put it all togethe agg = concat(cols, axis=1) agg.columns = names # drop rows with NaN values if dropnan: agg.dropna(inplace=True) return agg # 加载数据集 dataset = read_csv('purchaseData.csv', header=0, index_col=0) dataset = dataset.fillna(value=0) values = dataset.values # 整数编码 encoder = LabelEncoder() values[:, 1] = encoder.fit_transform(values[:, 1]) # 确保所有数据是浮动的 values = values.astype('float32') # 归一化特征 scaler = MinMaxScaler(feature_range=(0, 1)) scaled = scaler.fit_transform(values) # 构建监督学习问题 reframed = series_to_supervised(scaled, 5, 5) print(reframed.shape) # output:(418,120) # 分为训练集和测试集 values = reframed.values n_train_days = 397 train = values[:n_train_days, :] # day1 to day397 test = values[n_train_days:, :] # day398 to day 427 # 分为输入和输出 train_X, train_y = train[:, :-1], train[:, -1] test_X, test_y = test[:, :-1], test[:, -1] print(train_X.shape, len(train_X), train_y.shape) # (397, 119) 397 (397,) # 重塑为3D形状 [samples, timesteps, features] train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1])) test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1])) print(train_X.shape, train_y.shape, test_X.shape, test_y.shape) #(397, 1, 119) (397,) (21, 1, 119) (21,) # 设计网络 model = Sequential() model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2]))) model.add(Dense(1)) model.compile(loss='mae', optimizer='adam') # 拟合神经网络模型 history = model.fit(train_X, train_y, epochs=50, batch_size=72, validation_data=(test_X, test_y), verbose=2, shuffle=False) # 绘制历史数据 pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() pyplot.show() print(test_X.shape) #(21, 1, 119) # 作出预测 yhat = model.predict(test_X) test_X = test_X.reshape((test_X.shape[0], test_X.shape[2])) print(yhat.shape) #(21, 1) print(test_X.shape) #(21, 119) # 反向缩放预测值 inv_yhat = concatenate((yhat, test_X[:, 1:]), axis=1) print(inv_yhat.shape)#(21, 119) # inv_yhat = inv_yhat.reshape((len(inv_yhat),12)) inv_yhat = inv_yhat.reshape((test_X.shape[0], test_X.shape[1])) inv_yhat = scaler.inverse_transform(inv_yhat) # X : array-like, shape [n_samples, n_features] inv_yhat = inv_yhat[:,0] # 反向缩放实际值 test_y = test_y.reshape((len(test_y), 1)) inv_y = concatenate((test_y, test_X[:, 1:]), axis=1) inv_y = scaler.inverse_transform(inv_y) # X : array-like, shape [n_samples, n_features] inv_y = inv_y[:,0] # 计算RMSE rmse = sqrt(mean_squared_error(inv_y, inv_yhat)) print('Test RMSE: %.3f' % rmse) plt.plot(inv_yhat) plt.plot(yhat) plt.show()


代码3
import pandas as pd import numpy as np import matplotlib.pyplot as plt import tensorflow as tf import csv import codecs #——————————————————导入数据—————————————————————— f=open('purchase.csv') df=pd.read_csv(f) data=np.array(df['total_purchase_amt']) #获取最高价序列 #以折线图展示data plt.figure() plt.plot(data) plt.show() normalize_data=(data-np.mean(data))/np.std(data) #标准化 normalize_data=normalize_data[:,np.newaxis] #增加维度 #生成训练集 #设置常量 time_step=20 #时间步 rnn_unit=10 #hidden layer units batch_size=60 #每一批次训练多少个样例 input_size=1 #输入层维度 output_size=1 #输出层维度 lr=0.0006 #学习率 train_x,train_y=[],[] #训练集 for i in range(len(normalize_data)-time_step-1): x=normalize_data[i:i+time_step] y=normalize_data[i+1:i+time_step+1] #后一天的total_purchase_amt最为标签[y] train_x.append(x.tolist()) train_y.append(y.tolist()) def data_write_csv(file_name, datas):#file_name为写入CSV文件的路径,datas为要写入数据列表 file_csv = codecs.open(file_name,'w+','utf-8')#追加 writer = csv.writer(file_csv, delimiter=' ', quotechar=' ', quoting=csv.QUOTE_MINIMAL) for data in datas: writer.writerow(data) print("保存文件成功,处理结束") #——————————————————定义神经网络变量—————————————————— X=tf.placeholder(tf.float32, [None,time_step,input_size]) #每批次输入网络的tensor Y=tf.placeholder(tf.float32, [None,time_step,output_size]) #每批次tensor对应的标签 #输入层、输出层权重、偏置 weights={ 'in':tf.Variable(tf.random_normal([input_size,rnn_unit])), 'out':tf.Variable(tf.random_normal([rnn_unit,1])) } biases={ 'in':tf.Variable(tf.constant(0.1,shape=[rnn_unit,])), 'out':tf.Variable(tf.constant(0.1,shape=[1,])) } #——————————————————定义神经网络变量—————————————————— def lstm(batch): #参数:输入网络批次数目 w_in=weights['in'] b_in=biases['in'] input=tf.reshape(X,[-1,input_size]) #需要将tensor转成2维进行计算,计算后的结果作为隐藏层的输入 input_rnn=tf.matmul(input,w_in)+b_in input_rnn=tf.reshape(input_rnn,[-1,time_step,rnn_unit]) #将tensor转成3维,作为lstm cell的输入 cell=tf.nn.rnn_cell.BasicLSTMCell(rnn_unit) init_state=cell.zero_state(batch,dtype=tf.float32) output_rnn,final_states=tf.nn.dynamic_rnn(cell, input_rnn,initial_state=init_state, dtype=tf.float32) #output_rnn是记录lstm每个输出节点的结果,final_states是最后一个cell的结果 output=tf.reshape(output_rnn,[-1,rnn_unit]) #作为输出层的输入 w_out=weights['out'] b_out=biases['out'] pred=tf.matmul(output,w_out)+b_out return pred,final_states #——————————————————训练模型—————————————————— def train_lstm(): global batch_size pred,_=lstm(batch_size) #损失函数 loss=tf.reduce_mean(tf.square(tf.reshape(pred,[-1])-tf.reshape(Y, [-1]))) train_op=tf.train.AdamOptimizer(lr).minimize(loss) saver=tf.train.Saver(tf.global_variables()) # 创建一个Saver对象 # base_path = r'C:\Users\mdz\Desktop\Forecast\lstm' with tf.Session() as sess: sess.run(tf.global_variables_initializer()) #重复训练10000次 for i in range(4000): step=0 start=0 end=start+batch_size while(end
Reference
《TensorFlow: 实战Google深度学习框架》 对于小白规范化自己的代码,增强代码的复用性很有必要看看
使用Keras进行LSTM实战
Tensorflow实例:利用LSTM预测股票每日最高价(一)
Tensorflow实例:利用LSTM预测股票每日最高价(二)