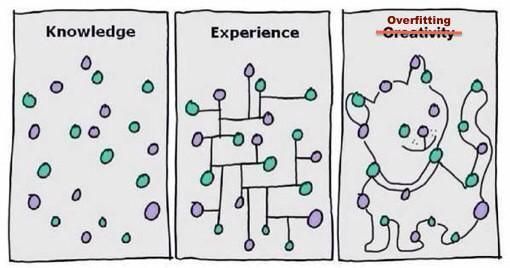
决策树过拟合现象_过拟合
 img
img
本文从模型训练的过拟合概念入手,通过两个实际的模型训练(LSTM和LightGBM)展示了在训练过程中出现的过拟合现象,之后通过修正参数来展示模型中参数对于过拟合结果的影响。全文分成如下几个部分:
模型训练中的过拟合和欠拟合
过拟合训练例子1:用Keras包创建LSTM模型拟合线性数据
过拟合训练例子2:用lightgbm拟合随机生成的数据
控制模型参数对过拟合的影响
总结
一 模型训练中的过拟合和欠拟合
模型其实就是对数据的一种解释,数据之间关系的提炼与总结,在如今的AI应用中,数据的复杂度和量级都超出了人可以直观理解甚至借助程序验证的射程,唯有借助数据本身得出的规律。模型的训练与选择,就是这样一个过程。AI模型训练出来的过程,就像小学生上学一样,需要接受老师的教育,因材施教,每种算法都有自己本身的特质,也需要对应的教练来指导,哪里做得好,哪里做得不够好,需要有一个即时的反馈,这老师就是优化器,而老师评判学生是否学好了的标准就是损失函数。就像现实中学生分学霸学渣一样,模型也有优劣之分。衡量模型效果最典型、最重要的,就是对数据的拟合程度,包括训练过程和测试、应用的效果:
欠拟合:这是上课没听懂、考试没通过的部分模型,老师教的还远远没有学会。(对现有的数据不能很好地地拟合)
过拟合:把上课学的东西都背下来了,看似很强大,实际却学成了书呆子,只会照本宣科,老师教过的都是圣旨,老师没教过的一律不会,考试的时候题型做了点变化就考不好,工作中没教过的就做错,这就是过拟合的模型。(对训练中的数据拟合效果好,但到了测试、实际应用的时候实际表现比训练过程中差)
介于欠拟合和过拟合之间的部分,真正做到融会贯通,上课也听懂了,考试也能考好,这就是比较好的模型,如下图所示:
 img
img
如下图所示,用多项式函数去拟合cosin函数的局部片段,合适的模型很重要,低阶多项式(1次)的模型过于简单,不能很好地贴合数据,这是欠拟合。而过高阶的模型(15次)则过度复杂,虽然总体误差更小,但与实际情况反而差距较大,属于对训练数据的过度解读。 接下来,我们举两个实际的例子来看看过拟合在实际的训练过程中是怎么实现现的。
接下来,我们举两个实际的例子来看看过拟合在实际的训练过程中是怎么实现现的。
二 过拟合训练例子1:使用Keras包拟合
举一个简单的例子,使用Keras包 对进行预测(这里选用的是LSTM模型,不了解也没关系,用任何模型都可以构造出过拟合的现象)
# 引入keras、画图包和numpy(基础数学工具包)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# 训练数据集
def get_train():
seq= [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq= array(seq)
X,y = seq[:, 0], seq[:, 1]
X= X.reshape((5, 1, 1))
returnX, y
# 验证集
def get_val():
seq= [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq= array(seq)
X,y = seq[:, 0], seq[:, 1]
X= X.reshape((len(X), 1, 1))
returnX, y
# 选取模型
model = Sequential()
model.add(LSTM(10,input_shape=(1,1)))
model.add(Dense(1,activation='linear'))
# 编译模型,使用mse作为损失函数,adam优化器进行迭代优化
model.compile(loss='mse',optimizer='adam')
# 训练模型
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=1200, validation_data=(valX, valY), shuffle=False)
# 画出损失函数和迭代轮数关系的曲线图
pyplot.plot(history.history['loss'][500:])
pyplot.plot(history.history['val_loss'][500:])
pyplot.title('modeltrain vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train','validation'], loc='upper right')
pyplot.show()
下图中,横轴是训练迭代的轮数,纵轴是训练误差和验证误差,从第1轮到第1200轮,乍一看训练误差和测试误差都在不断缩小:
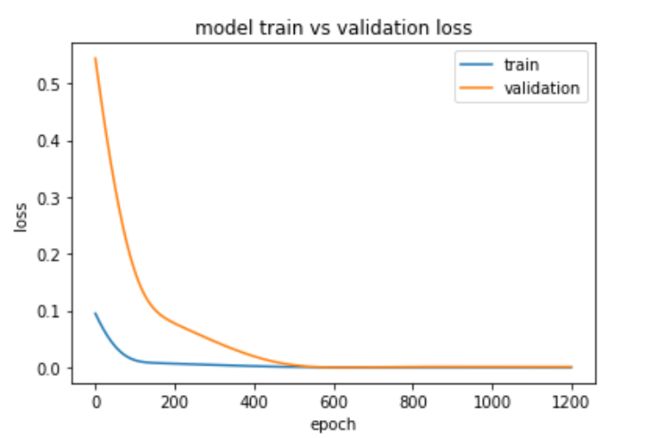 img
img
实际上,如果将细节部分进行放大,在500轮以后,出现了过拟合(下图是从500轮开始的情况,对应的500~1200轮中的训练误差和测试误差)
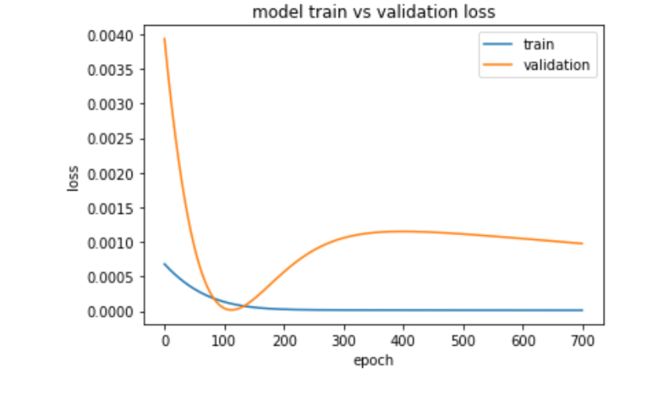 img
img
三 过拟合训练例子2:用lightgbm拟合随机生成的数据集
# 用sklearn来生成分类数据
import sklearn
from sklearn import datasets
import matplotlib.pyplot as plt
# 使用lightgbm进行拟合
import lightgbm as lgb
n_classes= 5 # 生成样本的参数:样本分为多少个类别
X, y =sklearn.datasets.make_classification(
n_samples=1000, # 生成多少样本
n_features=30, # 总共有多少特征
n_informative=4, # 其中有多少个是有用的
n_redundant=5, # 有多少冗余的特征(其他特征的线性组合)
n_repeated=0, # 有多少重复的特征
n_classes=n_classes, # 样本分为多少个类别
n_clusters_per_class=1, # 每个class有多少个团
flip_y=0.01, # 加入噪音(是否翻转部分y值?),指定翻转的比例
class_sep=1.0,
hypercube=True,
shift=0.0,
scale=1.0,
shuffle=True,
random_state=None
)
from sklearn.model_selection import train_test_split
X_train, X_test,y_train, y_test = train_test_split(X, y, test_size=0.80, random_state=42)
print("Traindata length:",len(X_train));
print("Testdata length:",len(X_test));
# 根据给定的lightgbm参数进行一次训练
def run(params):
evals_result = {} #记录训练结果所用
# 导入到lightgbm矩阵
train_data = lgb.Dataset(X_train, y_train)
test_data = lgb.Dataset(X_test, y_test,reference=train_data) # reference参数用于标记验证集和训练集的关系
model = lgb.train(param,
train_data,
valid_sets=[train_data,test_data],
evals_result=evals_result, # 记录每一轮的损失函数计算值等,非常重要的参数,一定要设置
verbose_eval=False, # 多少轮输出一次训练成绩,True/False/number
verbose_eval=10,
)
# 输出运行时使用的参数
print(params)
# 利用记录下来的损失函数值绘制损失曲线
lgb.plot_metric(evals_result, metric='multi_logloss') #metric的值与之前的params里面的值对应
plt.show() # 立刻显示图像
param = {
'num_leaves': 500, # 多少个叶子节点
'objective': 'multiclass',
'num_boost_round': 100,
'max_depth': 3,
'metric':('multi_logloss','multi_error'),
'num_class':n_classes
}
run(param)
# 加入早停控制和树的深度控制
param.update({
'early_stopping_rounds':10,'max_depth':1})
run(param)
四 控制模型参数对过拟合的影响
lightgbm是以决策树模型为基础的,关于决策树和lightgbm,可以参考 决策树算法--ID3、决策树剪枝、LightGBM算法初探等Argo往期文章。这里,通过控制树的深度和早停轮数(EarlyStopping,早停是控制训练结束条件的,比如早停轮数=10,代表如果有连续10轮训练迭代训练误差没有更新,认为模型已经无法改进,训练结束)来做两次实验:
第一轮:最大树深度3,没有早停控制
第二轮:最大树深度1,早停轮数10
两轮的训练曲线如下
 img
img
这两轮迭代的区别在于模型的参数,树的深度是决策树模型特有的,这类模型参数是需要特事特办的,每种模型的工作原理、参数设置都不同,甚至同一种模型在不同的实现方式下调参的效果也会变化,所以调优方式都不尽相同。比如lightgbm基于决策树,因而可以通过调整树的深度、叶子节点的数量来控制模型的复杂度和拟合效果,但同样基于树模型的xgboost因一些实现上的差异导致两者本身就有一些特质上的区别,调参的方式也有所不同。所以说炼丹不易,调参师不是那么好当的。
但像早停轮数这样的参数却是通用的,这个就便宜大碗省时省力了。除了早停外,还有两个很普遍的方法来预防过拟合,思路也很简单:过拟合源于模型对数据的过度解读,说明模型的复杂度超出了解读数据需要的复杂度,那么对应的,可以增加数据的数量、复杂度,从而匹配上模型的复杂度,或者降低模型的复杂度,使其匹配数据的复杂度。对应的两种方法就是:增加测试样本集,在损失函数中加入正则化因子。正则化因子用模型的参数来表示模型的复杂度,模型的参数越多、数值越大,则认为模型越复杂,参数越少,数值越小,则认为模型越简单(关于正则化的部分,可以参考Argo往期文章专家观点:L1正则稀疏?),这里先留个坑,请等我们更新下一篇。
总结
a 过拟合是什么?
模型在训练阶段表现出色,但对训练样本过度解读,无法应对数据的变化,测试误差反而大,导致测试和实际应用中效果比预期差。
b 通用的解决办法是什么?使用早停参数防止过度训练
使用正则化参数控制模型复杂度
增加训练集
c lightgbm等决策树模型如何防止过拟合?
控制树的深度、叶子节点的数量等(也就是控制模型复杂度)
好了,这篇过拟合的文章就说到这里了。这篇文章我们结合实战描述了过拟合现象。机器学习这一年在招聘岗位上已经开始急剧减少,但是这种蕴含数据科学精神的学科,却值得我们一直关注,其对我们的生活决策有会很有帮助。谢谢大家关注我们的公众号,欢迎大家加入我们,与我们一起学习~
