数据降维算法总结(LDA&PCA)
目录
- LDA
-
- 概述
- 数学基础知识
- 二类LDA原理
- 多类LDA原理
- LDA算法流程
- 优点
- 缺点
- PCA
-
- 概述
- 协方差和散度矩阵
- 特征值分解矩阵原理
- SVD分解矩阵原理
- PCA的两种实现方法
-
- 准则
- 优点
- 缺点
- 算法应用
- LDA vs PCA
- 参考
- 关于作者
LDA
概述
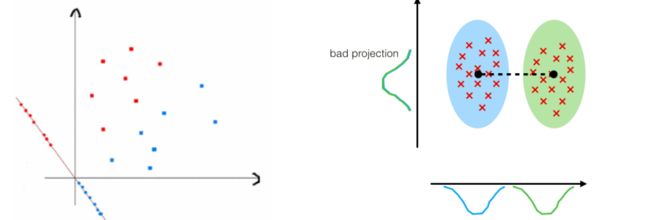
LDA(Linear Discriminant Analysis),线性判别分析。LDA是一种监督学习的降维技术。主要用于数据预处理中的降维、分类任务。LDA的目标是最大化类间区分度的坐标轴成分,将特征空间投影到一个维度更小的k维子空间中,同时保持区分类别的信息。简而言之,LDA投影后的数据类内方差最小,类间方差最大。
数学基础知识
瑞利商
定义: R ( A , x ) = x H A x x H x R(A,x) = \frac{x^HAx}{x^Hx} R(A,x)=xHxxHAx
其中,x是非零向量,A是n*n的Hermitan矩阵(自共轭矩阵,矩阵中每一个第i行第j列的元素都与第j行第i列的元素的共轭相等)
性质:瑞利商最大值等于矩阵A最大的特征值,最小值等于矩阵A的最小特征值
λ m i n ⩽ x H A x x H x ⩽ λ m a x \lambda_{min} \leqslant \frac{x^HAx}{x^Hx} \leqslant \lambda_{max} λmin⩽xHxxHAx⩽λmax
广义瑞利商
定义: R ( A , x ) = x H A x x H B x R(A,x) = \frac{x^HAx}{x^HBx} R(A,x)=xHBxxHAx
其中,x是非零向量,而A,B为n*n的Hermitan矩阵。B为正定矩阵
最大值为矩阵 B − 1 2 A B − 1 2 B^{-\frac{1}{2}}AB^{\frac{-1}{2}} B−21AB2−1的最大特征值,或者说矩阵 B − 1 A B^{-1}A B−1A的最大特征值,最小值是其最小特征值
二类LDA原理
假设数据集 D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . . . . , ( x m , y m ) D={(x_1,y_1),(x_2,y_2),......,(x_m,y_m)} D=(x1,y1),(x2,y2),......,(xm,ym),其中任意 x i x_i xi为n维向量
第j类样本的均值向量: μ j = 1 n j ∑ x ( j = 0 , 1 ) \mu_j = \frac{1}{n_j}\sum x(j=0,1) μj=nj1∑x(j=0,1)
第j类样本的协方差矩阵: Σ j = ∑ ( x − μ j ) ( x − μ j ) T ( j = 0 , 1 ) \Sigma_j = \sum (x-\mu_j)(x-\mu_j)^T (j=0,1) Σj=∑(x−μj)(x−μj)T(j=0,1)
假设投影直线是向量 ω \omega ω,则对任意一个样本本xi,它在直线 ω \omega ω的投影为 ω T x i \omega^Tx_i ωTxi,对于我们的两个类别的中心点 μ 0 , μ 1 \mu_0,\mu_1 μ0,μ1,在在直线 ω \omega ω的投影为 ω T μ 0 \omega^T\mu_0 ωTμ0, ω T μ 1 \omega^T\mu_1 ωTμ1。由于LDA需要让不同类别的数据的类别中心之间的距离尽可能的大,也就是我们要最大化 ∣ ∣ ω T μ 0 − ω T μ 1 ∣ ∣ 2 2 ||\omega^T\mu_0−\omega^T\mu_1||_2^2 ∣∣ωTμ0−ωTμ1∣∣22,同时我们希望同一种类别数据的投影点尽可能的接近,也就是要同类样本投影点的协方差 ω T Σ 0 ω \omega^T\Sigma_0\omega ωTΣ0ω和 ω T Σ 1 ω \omega^T\Sigma_1\omega ωTΣ1ω尽可能的小,即最小化 ω T Σ 0 ω + ω T Σ 1 ω \omega^T\Sigma_0\omega+\omega^T\Sigma_1\omega ωTΣ0ω+ωTΣ1ω。综上所述,我们的优化目标为:
a r g m a x J ( ω ) = ∣ ∣ ω T μ 0 − ω T μ 1 ∣ ∣ 2 2 ω T Σ 0 ω + ω T Σ 1 ω = ω T ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T ω ω T ( Σ 0 + Σ 1 ) ω arg max J(\omega) = \frac{||\omega^T\mu_0-\omega^T\mu_1||_2^2}{\omega^T\Sigma_0\omega+\omega^T\Sigma_1\omega} = \frac{\omega^T(\mu_0-\mu_1)(\mu_0-\mu_1)^T\omega}{\omega^T(\Sigma_0+\Sigma_1)\omega} argmaxJ(ω)=ωTΣ0ω+ωTΣ1ω∣∣ωTμ0−ωTμ1∣∣22=ωT(Σ0+Σ1)ωωT(μ0−μ1)(μ0−μ1)Tω
类内散度矩阵 S ω S_\omega Sω为:
S ω = Σ 0 + Σ 1 = ∑ ( x − μ 0 ) ( x − μ 0 ) T + ∑ ( x − μ 1 ) ( x − μ 1 ) T S_\omega = \Sigma_0 + \Sigma_1 = \sum(x-\mu_0)(x-\mu_0)^T+ \sum(x-\mu_1)(x-\mu_1)^T Sω=Σ0+Σ1=∑(x−μ0)(x−μ0)T+∑(x−μ1)(x−μ1)T
类间散度矩阵 S b S_b Sb为:
S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T S_b = (\mu_0-\mu_1)(\mu_0-\mu_1)^T Sb=(μ0−μ1)(μ0−μ1)T
优化目标重新定义:
a r g m a x J ( ω ) = ω T S b ω ω T S ω ω argmax J(\omega) = \frac{\omega^TS_b\omega}{\omega^TS_\omega\omega} argmaxJ(ω)=ωTSωωωTSbω
这就是广义瑞利商,最大值就是 S ω − 1 S b S_\omega^{-1}S_b Sω−1Sb的最大特征值
多类LDA原理
优化目标:
a r g m a x J ( ω ) = ∏ ω T S b ω ∏ ω T S ω ω = ∏ ω T S b ω ω T S ω ω argmax J(\omega) = \frac{\prod \omega^TS_b\omega}{\prod \omega^TS_\omega\omega} = \prod \frac{\omega^TS_b\omega}{\omega^TS_\omega\omega} argmaxJ(ω)=∏ωTSωω∏ωTSbω=∏ωTSωωωTSbω
特征向量最多有k-1个
LDA算法流程
- 计算类内散度矩阵 S ω S_\omega Sω
- 计算类间散度矩阵 S b S_b Sb
- 计算矩阵 S ω − 1 S b S_\omega^{-1}S_b Sω−1Sb
- 计算 S ω − 1 S b S_\omega^{-1}S_b Sω−1Sb的最大的d个特征值和对应的d个特征向量 ( ω 1 , ω 2 , . . . . . . , ω d ) (\omega_1,\omega_2,......,\omega_d) (ω1,ω2,......,ωd)得到投影矩阵W
- 对样本集中的每一个样本特征 x i x_i xi,转为新的样本 z i = ω T x i z_i=\omega^Tx_i zi=ωTxi
- 得到输出样本集 D ′ = ( z 1 , y 1 ) , ( z 2 , y 2 ) , . . . . . . ( z m , y m ) D' = {(z_1,y_1),(z_2,y_2),......(z_m,y_m)} D′=(z1,y1),(z2,y2),......(zm,ym)
优点
- 在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
- LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
缺点
- LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
- LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
- LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
- LDA可能过度拟合数据。
PCA
概述
PCA(principal component analysis),主成分分析。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。
PCA的工作就是从原始的空间中顺序的找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大,第三个轴是与第1、2个轴正交的平面中方差最大的。以此类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
计算数据矩阵的协方差矩阵,得到协方差矩阵的特征值特征向量,选择特征值最大(方差最大)的k个特征所对应的特征向量组成的矩阵。
由于得到协方差矩阵的特征值特征向量有两种方法:特征值分解协方差矩阵、奇异值分解协方差矩阵
协方差和散度矩阵
协方差
C o v ( X , Y ) = E [ ( X − E ( x ) ) ( Y − E ( Y ) ) ] = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) Cov(X,Y) = E[(X-E(x))(Y-E(Y))] = \frac{1}{n-1}\sum_{i=1}^{n}(x_i-\bar x)(y_i-\bar y) Cov(X,Y)=E[(X−E(x))(Y−E(Y))]=n−11i=1∑n(xi−xˉ)(yi−yˉ)
协方差矩阵

散度矩阵
S = ∑ k = 1 n ( x k − x ˉ ) ( x k − y ˉ ) T S = \sum_{k=1}^{n}(x_k-\bar x)(x_k-\bar y)^T S=k=1∑n(xk−xˉ)(xk−yˉ)T
对于数据X的散度矩阵 X X T XX^T XXT。
特征值分解矩阵原理
- 计算特征值和特征向量
- 计算特征值分解矩阵

SVD分解矩阵原理
奇异值分解是一个能适用于任意矩阵的一种分解方法,对于任意矩阵A总是存在一个奇异值分解:
A = U Σ V T A = U\Sigma V^T A=UΣVT
假设A是一个mn的矩阵,那么U是一个mm的方针,U里面的正交向量被称为左奇异向量。 Σ \Sigma Σ是一个mn的矩阵, Σ \Sigma Σ除了对角线其他元素都是0,对角线上的元素称为奇异值。 V T V^T VT是V的转置矩阵,是一个nn的矩阵,它里面的正交向量被称为右奇异值向量。而且一般来讲,我们会将 Σ \Sigma Σ上的值按从大到小的顺序排列。
SVD分解矩阵A的步骤:
- 求 A A T AA^T AAT的特征值和特征向量,用单位化的特征向量构成U
- 求 A T A A^TA ATA的特征值和特征向量,用单位化的特征向量构成V
- 将 A A T AA^T AAT或者 A T A A^TA ATA的特征值求平方根,然后构成 Σ \Sigma Σ
PCA的两种实现方法
输入数据集 X = x 1 , x 2 , . . . . . . , x n X = {x_1,x_2,......,x_n} X=x1,x2,......,xn,需要降到k维
- 去平均化(去中心化),即每一位特征减去各自的平均值
- 计算协方差矩阵
- 用特征值分解方法求协方差矩阵的特征值和特征向量
- 用特征值从大到小排序,选择其中最大的k个,然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵P
- 将数据转换到k个特征向量构建的新空间中,即Y=PX
准则
- 最近重构性:样本集中所有点,重构后的点距离原来的点的误差之和最小
- 最大可分性:样本在低维空间的投影尽可能分开
优点
- 使得数据集更易使用
- 降低算法的计算开销
- 去除噪声
- 使结果容易理解
- 完全无参数限制
缺点
- 如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期效果,效率也不高
- 特征值分解有一定的的局限性,比如变换的矩阵必须是方阵
- 在非高斯分布情况下,PCA方法得到的主元可能并不是最优的
算法应用
- 高维数据集的探索和可视化
- 数据压缩
- 数据预处理
- 图像、语音、通信的分析处理
- 降维,取出数据冗余与噪声
LDA vs PCA
- 两者均可以对数据进行降维。
- 两者在降维时均使用了矩阵特征分解的思想。
- 两者都假设数据符合高斯分布。
- LDA是有监督的降维方法,而PCA是无监督的降维方法
- LDA降维最多降到类别数k-1的维数,而PCA没有这个限制。
- LDA除了可以用于降维,还可以用于分类。
- LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。
参考
https://www.cnblogs.com/pinard/p/6244265.html
https://blog.csdn.net/program_developer/article/details/80632779
关于作者
知乎