Matlab入门4 机器学习基础算法
赞赏码 & 联系方式 & 个人闲话
配套课件可访问https://github.com/BIMK/MATLAB下载,是安徽大学Matlab本科教学课件,逻辑清晰,简洁明了,颇为实用,用来入门再好不过(机器学习方向)。
本系列博文是课后练习的个人解答,通过几个小实验展示matlab基本语法和技巧。接触Matlab也有几年了,略有心得,分享给大家。
【实验名称】机器学习基础算法
【实验目的】
1. 熟悉matlab机器学习的基础算法
2. 掌握基本的分类算法
3. 掌握基本的聚类算法
【实验内容】
1. 学习并实现简单的分类和聚类算法
2. 分类:给定训练集,其中每个训练样本包含一个特征向量x和一个类别标签y;训练一个模型,使之能够根据一个未知的特征向量x'来判断其类别标签y'
3. 聚类:给定数据集,其中每个样本仅包含一个特征向量x,根据高内聚低耦合的原则来计算每个样本的类别标签y
k-近邻算法代码(详见注释)
function task4_1() % 10行代码 k-近邻算法
X = rand(100,2)*2-1; % 每行一个训练样本,每列一个特征
Y = sum(X,2)>randn(100,1)/10; % 每行一个标签
k = 3; % k近邻参数
[p1,p2] = meshgrid(-1:0.01:1); % 用于绘制分类面的测试样本
[~,B] = sort(pdist2([reshape(p1,size(p1,1)^2,1), reshape(p2,size(p2,1)^2,1)],X),2); % 确定离每个测试样本最近的训练样本
Y2 = sum(reshape(Y(B(:,1:k),1),size(B,1),k),2) > k/2;% 确定标签
hold on; box on; % 绘制训练样本分类面
plot(X(Y,1),X(Y,2),'ok','MarkerFaceColor','b');
plot(X(~Y,1),X(~Y, 2),'ok' ,'MarkerFaceColor','r');
contour (p1,p2,reshape(Y2,size(p1)),1,'LineWidth',2);
end
运行结果




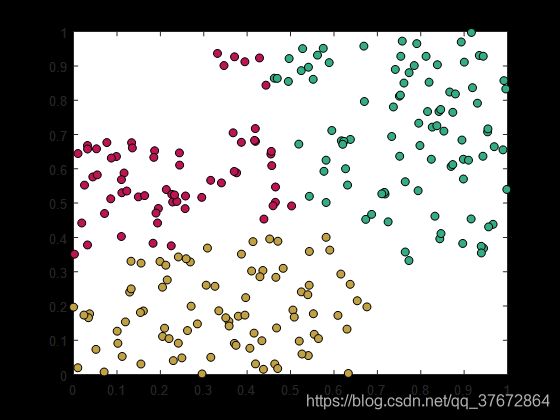
k-means算法代码(详见注释)
function task4_2() % 10行代码 k-means算法
X = rand(300,2); % 每行一个样本,每列一个特征
X(sum(X.^2,2)>0.5&sum((1-X).^2,2)>0.5,:) = [];
k=5; % k-means参数
C = X(randperm(end,k),:); % 初始中心点
for i = 1:100 % 重复迭代100次
[~,Y] = min(pdist2(X,C),[],2);
C = reshape(cell2mat(arrayfun(@(j)[mean(X(Y==j,1)) mean(X(Y==j,2))],1:k,'UniformOutput',false)),2,k)';
end
hold on; box on; % 绘制聚类结果
arrayfun(@(j)plot(X(Y==j,1),X(Y==j,2),'ok','MarkerFaceColor',rand(1,3)),1:k);
end
运行结果



总结
实验难度总体不大,只用10行代码写的话会复杂些,需仔细斟酌一下逻辑。k-近邻算法中k不能是偶数的原因是,防止出现k个邻近点中不同类别的训练样本数量相同,从而无法分类的情况。