lucene 添加扩展词需要重新索引_电商检索基础之Lucene
各位专栏的老朋友们,好久不见,别来无恙。
主要内容:
- 为什么需要Lucene?
- Lucene初印象
- Lucene是干嘛的?
- Lucene会很笨重吗?
- 我应该把Lucene/Solr放哪?
- Lucene如何实现全文检索
- 什么是全文检索
- 文档入库
- 分词
- 索引
- 从搜索框到索引库:一个关键词的冒险之旅
为什么需要Lucene?
任何一项技术的诞生,肯定是为了应对新需求的挑战。之所以有Lucene,简单来说就是在某些场景中,MySQL有点力不从心了。以我们每天都在用的淘宝京东等电商为例,它们的站内搜索就不适合用MySQL这种关系型数据库实现。
假设这样一个场景:现在你在一家小型电商公司做Java,老板想让你做站内搜索,要求输入关键词后能同时匹配3个字段(product_name, price, describe)。比如,用户输入“挪威的森林”,只要某条数据中这三个字段任意一个字段内容匹配,数据库就要返回该数据。
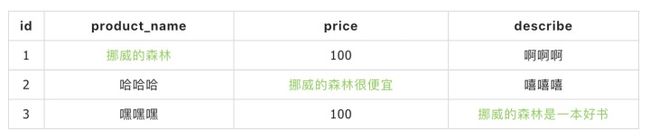
以MySQL为例,要实现上面的需求,可以写成下面这样:
select 但上面的SQL有至少以下两个弊端:
- 数据量很大时,like模糊搜索效率不高,不容易建立索引
- 前台传入的关键词,我们只能原原本本传给MySQL做全匹配搜索的,容错率很低。什么意思?假设用户记错了书名,把《挪威的森林》记成《挪威的树林》,但数据库中存的是”挪威的森林“,无法完全匹配,于是查询结果为0条。
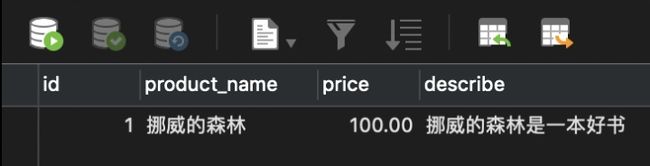
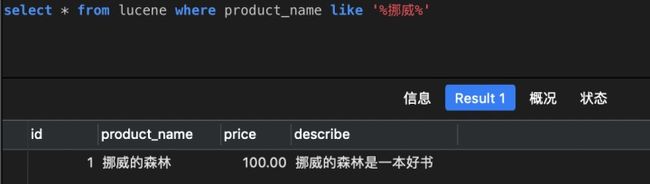
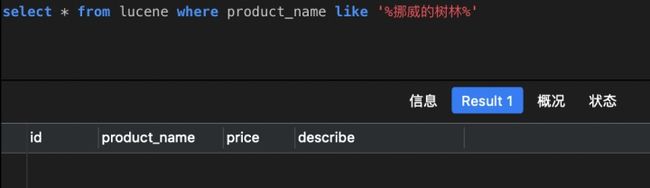
但淘宝京东这样的电商,即使你输入错误,还是会匹配到预期结果。
很明显,它们并不会笨到直接拿整个关键词去各个字段逐个匹配。
怎么做到的?
这时,Lucene就闪亮登场了。(其实无论Solr还是Elastic Search,底层都基于Lucene)
Lucene初印象
Lucene是干嘛的?
所谓编程,其实说穿了就两件事,拿数据,处理数据。而数据大致可以分为两类:结构化数据和非结构化数据。
- 结构化数据
- 定义:格式固定、长度固定、数据类型固定
- 代表:数据库中的数据
- 非结构化数据(文档)
- 定义:格式不固定、长度不固定、数据类型不固定
- 代表:word文档、pdf文档、邮件、html、txt
MySQL适合处理结构化数据,而Lucene则承担处理非结构化数据的重任。
我把Lucene的作用粗略概括为:
- 获取文档、构建文档对象、分析文档,从而建立与当前文档匹配的索引
- 利用索引快速查询文档内容

具体步骤我们后面再说。
Lucene会很笨重吗?
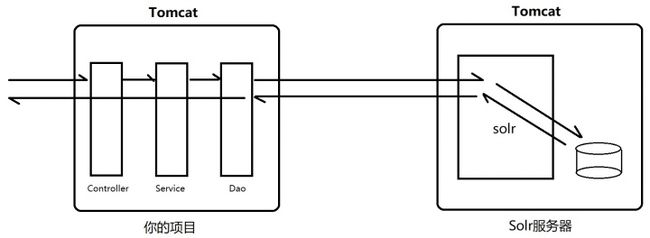
Lucene非常轻量级,它本质就是一个Java语言写的jar包。但这也意味着它无法被其他语言调用,于是有了后面的Solr。Solr内部其实也是基于Lucene开发,但对外暴露的是RESTful接口,因而实现了跨语言调用。
我应该把Lucene/Solr放哪?
使用Lucene时,直接导入它的jar包即可,除了需要指定索引库位置以外,使用上和工具类没啥区别。
相对于Lucene是一个jar包,Solr则是一个war包。使用Solr时,一般会把它部署为一个独立的war工程。具体使用步骤是,我们在Dao层通过HTTP请求Solr服务器,由Solr服务器去它索引库根据索引得到文档对象返回。
Lucene如何实现全文检索
什么是全文检索?
让我们考虑一下以下场景:假设你的D盘根目录有15个txt文档
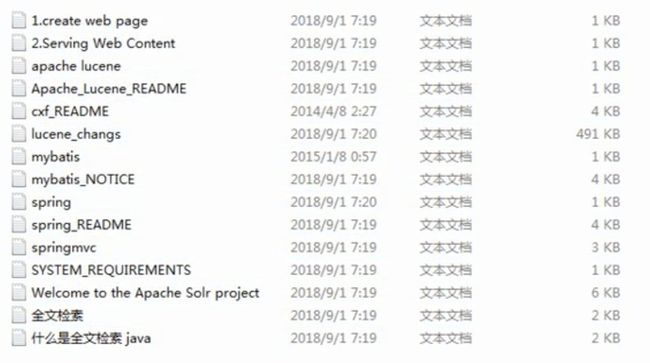
现在,我需要你找出所有标题或者内容带有"spring"单词的txt文档。
你最直观的想法肯定是:按顺序一个个看。
先看标题,再打开文件看内容。即使你能通过编程解决这个问题,思路还是这样,先IO读取文档,然后在程序中判断标题和内容是否包含"spring"。也就是所谓的顺序扫描法。
通常来说,针对非结构化数据的查询,有两种思路:
- 顺序扫描法
- 全文检索
所谓全文检索,不能单纯地把它等同于一种查询方式,它应该分为两步:
- 建立索引
- 查询
所谓建立索引,指的是将非结构化数据中的信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出来、重新组织的信息,我们称之为索引。(你看,最终非结构化数据还是被我们想办法变成了具备一定结构的数据,也从侧面说明了,我们其实无法真正对非结构化数据进行有效查询)
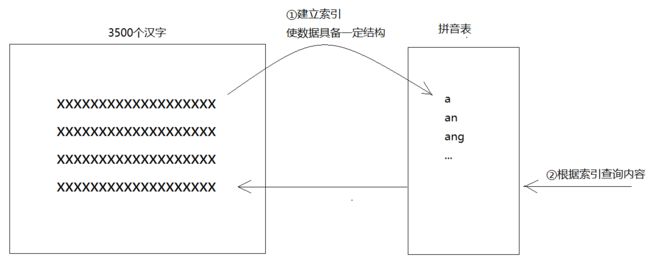
以字典为例。现代汉语中的常用字有2500个,次常用字有1000个,共计3500个汉字。这3500个汉字如果不加编排,直接放在一个txt文档中,是不是就是上面说的非结构化数据?此时无论让你找什么字,处境都很尴尬,因为你只能用顺序扫描法从头找到尾。
至于字典的解决方案,大家都已经知道啦,就是采用全文检索。字典的拼音表和部首检字表就相当于字典的索引。这些索引,是我们从成千上万个汉字中(非结构化数据)提取出来、重新组织的信息(索引)。比如,汉字的发音统一由声母和韵母组成,而其中符合发音规律的组合是有限的,可以一一列举,于是我们做出了拼音表方便读者根据拼音检索。(部首检字表同理)
文档入库
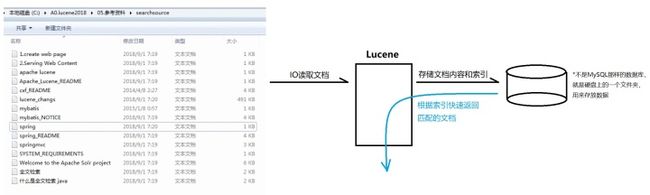
对任何数据库来说,并没有单独创建索引一说。索引肯定伴随着数据的存储,是存储数据时顺带的产物。还是以上面的15个txt文档为例。整体来说,Lucene建立索引的步骤就是开头出现的那张图:
落实到代码层面,是这样的:
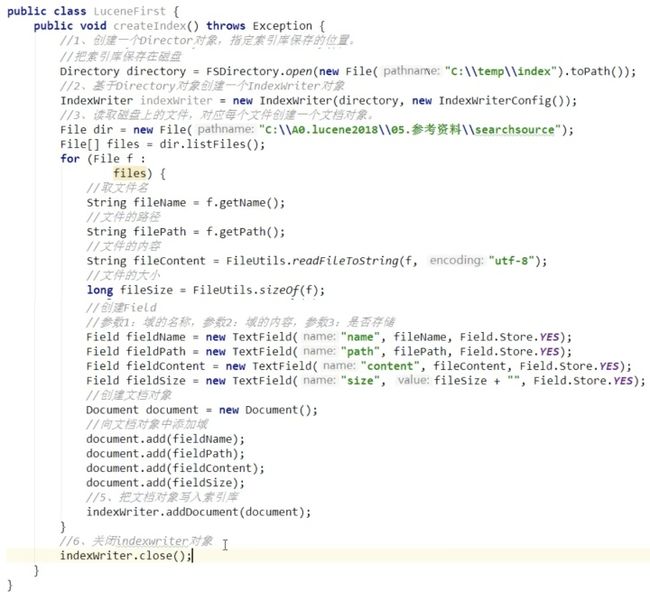
上面这段代码,头尾都能看懂,无非就是读取文档、写入文档。但中间那一堆写得啥玩意啊,啥叫域呀?这里,我建议大家就把Lucene的索引库类比成MySQL数据库。MySQL数据库的表字段不就是Field吗?所以,Lucene的域,其实就是Lucene索引库的字段。
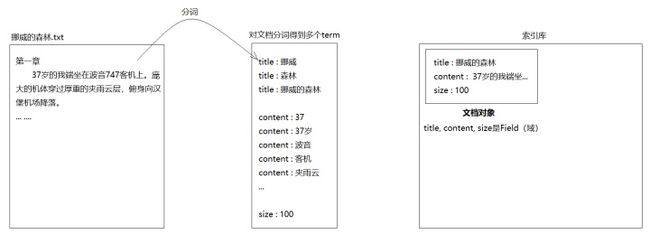
比如,全文检索.txt 这个文件,读取进内存创建Document对象时,我需要用几个字段去描述它:
- title(文件名)
- path(存储路径)
- content(内容)
- size(文件大小)
也就是说,经过Lucene解析,这个txt文件最终会变成一个包含4个域(Field)的文档对象,存储在Lucene指定的索引库中。

但是,如果你足够细心,你会发现创建索引的4个步骤中,我们并没有看到分析文档和创建索引的代码。
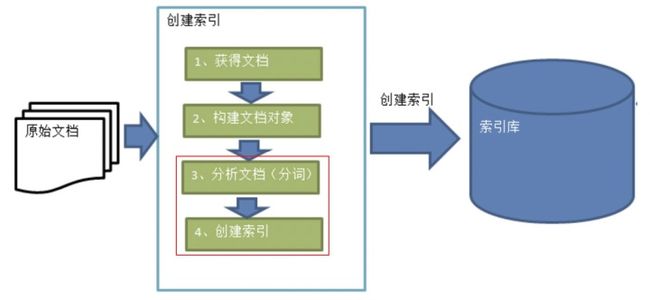
让我来给上面的代码打个聚光灯,大家一起来瞧瞧这块代码:
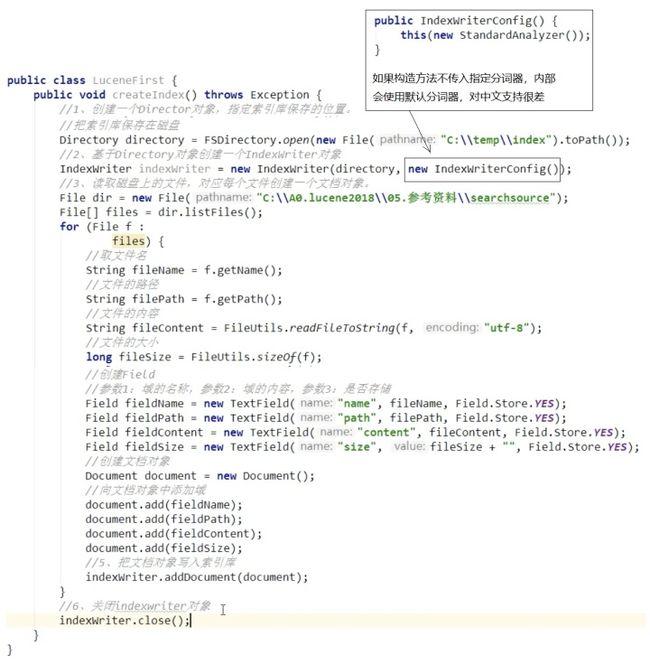
如果需要对中文进行分词,要使用对应的中文分词器,比如IK分词器。使用时导入一个第三方jar包即可。

所谓的“分析文档”,其实就是分词。比如某个txt文档叫“挪威的树林.txt”,Lucene在把它变成Document存入索引库时,会先对它进行分词处理。比如,标题“挪威的森林”,分词后可能是:
- 挪威
- 森林
- 挪威的森林
如此一来,前端页面在搜索“挪威的树林”时,就能根据“挪威”二字匹配到“挪威的森林”这本书。
分词
听到这,你会产生一个疑问,并且发现一个漏洞。
- 疑问:对标题分词后产生的几个碎片化词语是啥?原标题还在吗?
- 漏洞:不管你对文档怎么分词,拆成什么细粒度,我前端传来的还是“挪威的树林”,要全匹配呀...
先解释疑问。
其实,对文档内容分词得到的碎片化词汇,有个专门的称呼叫语汇单元,英文叫term。每个term是可以知道自己是从哪个域拆分出来的,所以你可以认为每个term包含一个词语和该词语所在的域。而文档原内容并没有被改动。
索引
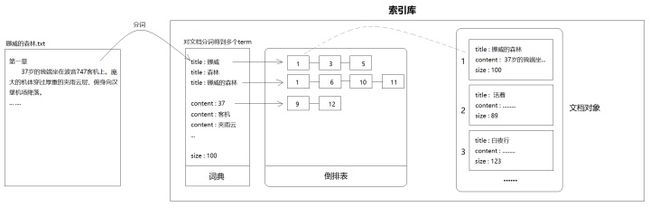
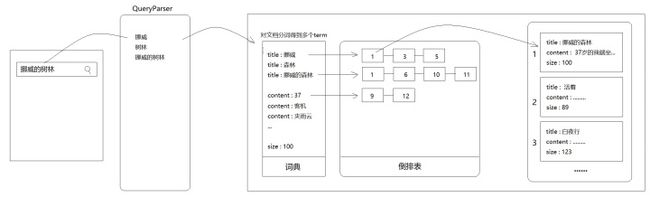
全文检索技术由来已久,绝大多数都基于倒排索引来做。倒排索引,顾名思义,它相反于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过。倒排索引由两部分组成——词典和倒排表。
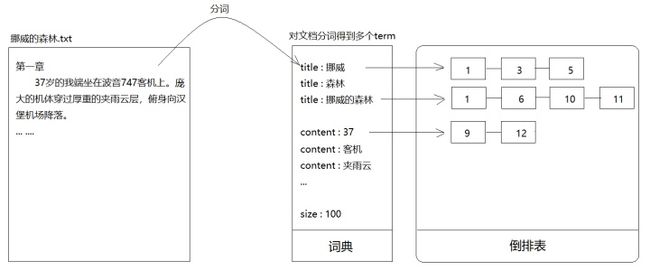
Lucene索引的词典正是来自于对文档分词得到的term,而倒排表里记录的则是出现这个term的文档id。以"title:挪威"为例,后面的1-3-5表示id为1、3、5的文档标题中出现了“挪威”两个字。又比如"content:客机"后面的1-6-10-11表示这些文档的内容中出现了“客机”两个字。
之前我们提过顺序扫描法,它的做法是根据文件找内容,然后逐一匹配。而倒排索引是反过来的,它根据内容匹配文档。一般来说文档的数据量要远大于索引,所以根据索引找文档绝大部分情况下要快得多。(建立索引还是比较费劲的,但很值得)
接触过MySQL索引的朋友都知道,MySQL的索引数据结构是B+树。那Lucene的索引是啥数据结构?
有兴趣请参考:https://www.cnblogs.com/sessionbest/articles/8689030.html。
从搜索框到索引库:一个关键词的冒险之旅
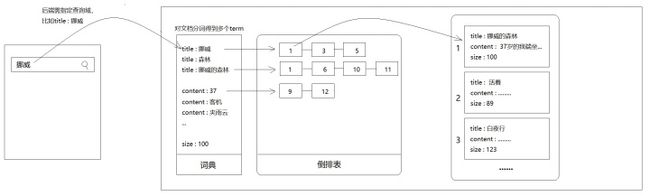
之前提到过,Lucene对文档进行分词、创建索引后用户就可以在前台输入“挪威的树林”查询到“挪威的森林”这本书了。其实是错的。因为到目前为止,我们的所有操作只是改进了数据存入数据库的方式,和用户查询入口没有任何关系。
假设,用户前台输入的关键词刚好匹配某个term,比如“挪威”、“森林”,确实可以利用索引快速查出数据。但是如果用户输入的是“挪威的树林”,或者“挪威的森林 村上春树”这样的句子,那刚刚创建的索引就无能为力了。

问题出在哪?
你说,你存入数据时做了分词,我查询时咋不也分一下词呢?
来,看一下Lucene的查询代码:
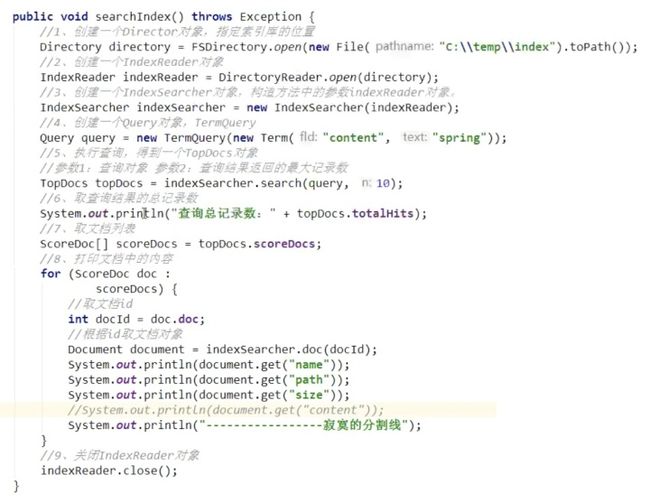
上面的代码中,我们只关心第4步对查询条件的封装(假设用户搜索 “挪威的树林”):
//4、创建一个Query对象:TermQuery
这句代码的意思是,拿着这个关键字去索引库匹配content域,看看词典里有没有content域包含这几个字,如果匹配,就把这个term对应的文档id返回。
(注意,不管从交互还是用户习惯上考虑,用户都不会、不应该指定查询域,所以后端要自己决定查询域)
但上面说过了,如果不对用户的查询文本也做分词,刚才的努力基本白费。怎么解决?
查询时对查询条件进行拆分!
需要导入Lucene为我们准备好的一个jar包lucene-queryparser以及IKAnalyzer(上面导过了)
然后在查询时不要直接使用TermQuery,而是用QueryParser.parse()解析得到Query对象。

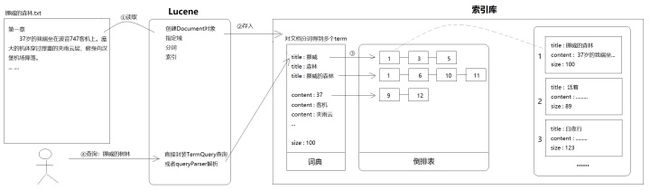
最后总结一下Lucene从创建索引到查询的整个流程:
看似应该完结了,但我们回头看看文章最开始的需求:

其实还有一些功能没实现 ,比如同时匹配多个字段,比如搜索结果中关键词高亮,再比如多词搜索。举个例子,用户搜索”苹果 手机“,一般想要的不是苹果或手机,而是iphone(苹果手机)。也就是说这两个词是and关系,而不是or。
下次有机会,讲Solr/Elastic Search时介绍。
没交代的一些概念:
- 动态域
- 默认域
- 复制域
- 高亮
- 句子的and与or关系
- MySQL数据导入Lucene
参考资料:黑马程序员 Lucene
2019-11-06 15:43:15