一、数据的分组与聚合
1.聚合函数
数组产生标量的过程,如mean()、count()等
常用于对分组后的数据进行计算,内置的聚合函数:
sum(), mean(), max(), min(), count(), size(), describe()
# 新建一个字典,构成DataFrame对象
>>>dict_obj = {'key1' : ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'data1': np.random.randint(1,10, 8),
'data2': np.random.randint(1,10, 8)}
>>> df_obj1=pd.DataFrame(dict_obj)
>>> df_obj1
data1 data2 key1 key2
0 4 3 a one
1 5 2 b one
2 5 9 a two
3 5 1 b three
4 4 5 a two
5 6 3 b two
6 5 7 a one
7 8 1 a three
>>> print(df_obj1.groupby("key1").sum()) # 求按照key1分组后的data1和data2各自的和
data1 data2
key1
a 26 25
b 16 6
>>> print(df_obj1.groupby("key1").mean()) # 平均值
data1 data2
key1
a 5.200000 5.0
b 5.333333 2.0
>>> print(df_obj1.groupby("key1").max()) # 最大值
data1 data2 key2
key1
a 8 9 two
b 6 3 two
>>> print(df_obj1.groupby("key1").min()) # 最小值
data1 data2 key2
key1
a 4 1 one
b 5 1 one
>>> print(df_obj1.groupby("key1").count()) # 个数
data1 data2 key2
key1
a 5 5 5
b 3 3 3
>>> print(df_obj1.groupby("key1").size()) # 尺寸
key1
a 5
b 3
dtype: int64
>>> print(df_obj1.groupby("key1").describe()) # 描述
data1 data2 \
count mean std min 25% 50% 75% max count mean std
key1
a 5.0 5.200000 1.643168 4.0 4.0 5.0 5.0 8.0 5.0 5.0 3.162278
b 3.0 5.333333 0.577350 5.0 5.0 5.0 5.5 6.0 3.0 2.0 1.000000
min 25% 50% 75% max
key1
a 1.0 3.0 5.0 7.0 9.0
b 1.0 1.5 2.0 2.5 3.0
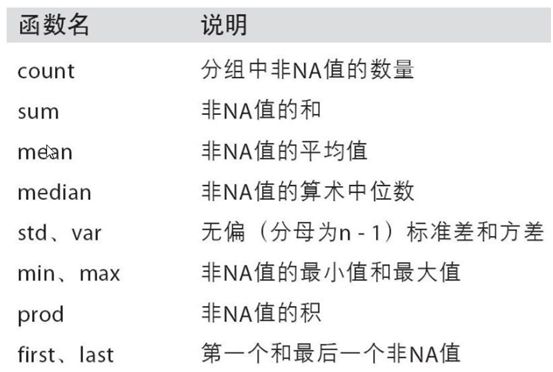
2.定义聚合函数func,使用agg(func)应用到DataFrame对象
grouped.agg(func)
func的参数为groupby索引对应的记录
>>>def func(num): #最大值和最小值的差
... return num.max() - num.min()
>>> print(df_obj1.groupby("key2").agg(func)) # 求df_obj1的key2分组的data1和data2的最大值和最小值的差
data1 data2
key2
one 1 5
three 3 0
two 2 6
# 效果同上,这里用的是匿名函数
>>> print(df_obj1.groupby("key2").agg(lambda df:df.max()-df.min()))
data1 data2
key2
one 1 5
three 3 0
two 2 6
3.调用多个聚合函数,agg()
使用列表将多个函数放在一起,内置函数用字符串表示,自定义函数直接用函数名称
>>> df_obj1.groupby("key1").agg(["sum","mean","max",func])
data1 data2
sum mean max func sum mean max func
key1
a 26 5.200000 8 4 25 5 9 8
b 16 5.333333 6 1 6 2 3 2
4.通过元组提供新的列名,对不同列使用不同聚合函数
# 以字典的形式,对不同的列,使用的不同的聚合函数
>>> dict_mapping={"data1":"mean","data2":"sum"}
# 使用DataFrame对象的agg函数,应用上面的字典
>>> print(df_obj1.groupby("key1").agg(dict_mapping))
data1 data2
key1
a 5.200000 25
b 5.333333 6
# 若想对指定的列定义多种聚合函数,可使用列表
>>> dict_mapping={"data1":"mean","data2":["sum","mean","max"]}
>>> print(df_obj1.groupby("key1").agg(dict_mapping))
data1 data2
mean sum mean max
key1
a 5.200000 25 5 9
b 5.333333 6 2 3
5.数据的分组运算,add_prefix()添加新的列名前缀
#按key2来分组,进行sum运算,并将计算后data1和data2添加新的列名前缀sum_
>>> df_sum=df_obj1.groupby("key2").sum()
>>> print(df_sum)
data1 data2
key2
one 14 12
three 13 2
two 15 17
>>> df_num=df_sum.add_prefix("sum_")
>>> print(df_num)
sum_data1 sum_data2
key2
one 14 12
three 13 2
two 15 17
6.groupby.apply(func)
func函数也可以在各分组上分别调用
# 需求:按星际争霸战队排名分组,降序排序,返回每个分组APM(每分钟操作的次数)top 3
>>>dataset_path = './starcraft.csv'
>>> df_data = pd.read_csv(dataset_path, usecols=['LeagueIndex', 'Age', 'HoursPerWeek','TotalHours', 'APM'])
>>> def top_n(df, n=3, column='APM'):
... #返回每个分组按 column 的 top n 数据
... return df.sort_values(by=column, ascending=False)[:n]
...
>>> print(df_data.groupby('LeagueIndex').apply(top_n))
LeagueIndex Age HoursPerWeek TotalHours APM
LeagueIndex
1 2214 1 20.0 12.0 730.0 172.9530
2246 1 27.0 8.0 250.0 141.6282
1753 1 20.0 28.0 100.0 139.6362
2 3062 2 20.0 6.0 100.0 179.6250
3229 2 16.0 24.0 110.0 156.7380
1520 2 29.0 6.0 250.0 151.6470
3 1557 3 22.0 6.0 200.0 226.6554
484 3 19.0 42.0 450.0 220.0692
2883 3 16.0 8.0 800.0 208.9500
4 2688 4 26.0 24.0 990.0 249.0210
1759 4 16.0 6.0 75.0 229.9122
2637 4 23.0 24.0 650.0 227.2272
5 3277 5 18.0 16.0 950.0 372.6426
93 5 17.0 36.0 720.0 335.4990
202 5 37.0 14.0 800.0 327.7218
6 734 6 16.0 28.0 730.0 389.8314
2746 6 16.0 28.0 4000.0 350.4114
1810 6 21.0 14.0 730.0 323.2506
7 3127 7 23.0 42.0 2000.0 298.7952
104 7 21.0 24.0 1000.0 286.4538
1654 7 18.0 98.0 700.0 236.0316
8 3393 8 NaN NaN NaN 375.8664
3373 8 NaN NaN NaN 364.8504
3372 8 NaN NaN NaN 355.3518
# apply函数接收的参数会传入自定义的函数中
>>> print(df_data.groupby('LeagueIndex').apply(top_n, n=2, column='Age'))
LeagueIndex Age HoursPerWeek TotalHours APM
LeagueIndex
1 3146 1 40.0 12.0 150.0 38.5590
3040 1 39.0 10.0 500.0 29.8764
2 920 2 43.0 10.0 730.0 86.0586
2437 2 41.0 4.0 200.0 54.2166
3 1258 3 41.0 14.0 800.0 77.6472
2972 3 40.0 10.0 500.0 60.5970
4 1696 4 44.0 6.0 500.0 89.5266
1729 4 39.0 8.0 500.0 86.7246
5 202 5 37.0 14.0 800.0 327.7218
2745 5 37.0 18.0 1000.0 123.4098
6 3069 6 31.0 8.0 800.0 133.1790
2706 6 31.0 8.0 700.0 66.9918
7 2813 7 26.0 36.0 1300.0 188.5512
1992 7 26.0 24.0 1000.0 219.6690
8 3340 8 NaN NaN NaN 189.7404
3341 8 NaN NaN NaN 287.8128
二、数据的清洗、合并、转化、重构
1.数据清洗:对数据进行重新审查和校验的过程
数据清洗是数据分析关键的一步,直接影响之后的处理工作,是一个迭代的过程,实际项目中可能需要不止一次地执行这些清洗操作
处理缺失数据:pd.fillna(),pd.dropna()
1-1.merge方法进行合并
merge将两张表合并,前提是必须有相同的外键
merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'),copy=True, indicator=False)
left:左边的数据,原始数据
right:右边的数据
how:指的是合并(连接)的方式有inner(内连接),left(左外连接),right(右外连接),outer(全外连接);默认为inner
on : 指的是用于连接的列索引名称。必须存在与左右两个DataFrame对象中,如果没有指定且其他参数也未指定则以两个DataFrame的列名交集做为连接键
left_on :左边数据表用作连接键的列名;这个参数中左右列名不相同,但代表的含义相同时非常有用。
right_on :右边数据表用作连接键的列名
left_index:使用左边DataFrame对象的行索引作为链接键
right_index:使用右边DataFrame对象的行索引作为链接键
一般情况下,外键和链接键的方向是相反的
sort:默认为True,将合并的数据进行排序。在大多数情况下设置为False可以提高性能
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为('_x','_y')
copy:默认为True,总是将数据复制到数据结构中;大多数情况下设置为False可以提高性能
indicator:在 0.17.0中还增加了一个显示合并数据中来源情况;如只来自己于左边(left_only)、两者(both)
根据单个或多个键将不同的dataframe的行连接起来,类似数据库的操作
# 范例
df_obj2 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1' : np.random.randint(0,10,7)})
df_obj3 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data2' : np.random.randint(0,10,3)})
# 默认将重叠列的列名作为“外键”进行连接
>>> print(df_obj1)
data1 data2 key1 key2
0 4 3 a one
1 5 2 b one
2 5 9 a two
3 5 1 b three
4 4 5 a two
5 6 3 b two
6 5 7 a one
7 8 1 a three
>>> print(df_obj2)
data1 key
0 5 b
1 6 b
2 2 a
3 9 c
4 3 a
5 2 a
6 1 b
>>> print(pd.merge(df_obj1, df_obj2))
data1 data2 key1 key2 key
0 5 2 b one b
1 5 9 a two b
2 5 1 b three b
3 5 7 a one b
4 6 3 b two b
说明:可以使用merge将多个表进行合并,如果没有指定外键,那么默认使用相同的列名作为外键,merge默认是內连接,结果是所有数据的交集
merge方法进行合并 - 范例
1-1-1.默认以重叠的列名当做连接键
>>> df1=pd.DataFrame({'key':['a','b','b'],'data1':range(3)})
>>> df2=pd.DataFrame({'key':['a','b','c'],'data2':range(3)})
>>> pd.merge(df1,df2) #没有指定连接键,默认用重叠列名,没有指定连接方式
data1 key data2
0 0 a 0
1 1 b 1
2 2 b 1
1-1-2.merge方法进行合并 - 范例 - 键名不同的连接
如果两个对象的列名不同,可以分别指定,可以使用lft_on 和right_on 来指定数据集的外键,left_on :指定左侧数据的外键,right_on:指定右边数据的外键
>>> df3=pd.DataFrame({'key1':['foo','foo','bar'],'key2':['one','two','one'],
'lval':[1,2,3]})
>>> df4=pd.DataFrame({'key3':['foo','foo','bar','bar'],'key4':['one','one','one',
'two'],'lval':[4,5,6,7]})
>>> pd.merge(df3,df4,left_on='key1',right_on='key3')
key1 key2 lval_x key3 key4 lval_y
0 foo one 1 foo one 4
1 foo one 1 foo one 5
2 foo two 2 foo one 4
3 foo two 2 foo one 5
4 bar one 3 bar one 6
5 bar one 3 bar two 7
1-1-3.默认做inner连接(取key的交集),制定连接方式:how
>>> pd.merge(df2,df1,how='outer')
data2 key data1
0 0 a 0.0
1 1 b 1.0
2 1 b 2.0
3 2 c NaN
*1-1-4.on显式指定外键
>>> print(pd.merge(df_obj2,df_obj3,on = "key"))
data1 key data2
0 5 b 2
1 6 b 2
2 1 b 2
3 2 a 3
4 3 a 3
5 2 a 3
1-1-5.交集和并集
交集:既属于集合A,又属于集合B的集合,称作A和B的交集
并集:所有属于集合A,或者所有属于集合B的集合,称为A和B的并集
>>> a = {3,4,5,6}
>>> b = {4,5,6,7}
>>> a & b # 交集
{4, 5, 6}
>>> a | b # 并集
{3, 4, 5, 6, 7}
指定连接方式
默认是“内连接”(inner),即结果中的键是交集, “外连接”(outer),结果中的键是并集
通过how参数指定连接方式
>>> print(df_obj2)
data1 key
0 5 b
1 6 b
2 2 a
3 9 c
4 3 a
5 2 a
6 1 b
>>> print(df_obj3)
data2 key
0 3 a
1 2 b
2 2 d
# 外连接
>>> print(pd.merge(df_obj2,df_obj3,how="outer"))
data1 key data2
0 5.0 b 2.0
1 6.0 b 2.0
2 1.0 b 2.0
3 2.0 a 3.0
4 3.0 a 3.0
5 2.0 a 3.0
6 9.0 c NaN
7 NaN d 2.0
# 左连接left
# left 无论右边数据是否得到匹配,都会把左边数据全部显示范例
>>> pd.merge(df_obj1,df_obj2,how="left")
data1 data2 key1 key2 key
0 4 3 a one NaN
1 5 2 b one b
2 5 9 a two b
3 5 1 b three b
4 4 5 a two NaN
5 6 3 b two b
6 5 7 a one b
7 8 1 a three NaN
# 右连接right
# right 无论左边数据是否得到匹配,都会把右边数据全部显示
>>> pd.merge(df_obj1,df_obj2,how="right")
data1 data2 key1 key2 key
0 5 2.0 b one b
1 5 9.0 a two b
2 5 1.0 b three b
3 5 7.0 a one b
4 6 3.0 b two b
5 2 NaN NaN NaN a
6 2 NaN NaN NaN a
7 9 NaN NaN NaN c
8 3 NaN NaN NaN a
9 1 NaN NaN NaN b
1-1-6.uffixes处理重复列名
如果两个数据的列名是相同的,那么指定一个外键,再将其它列名添加一个后缀,默认“_x””_y”
>>> df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'], 'data' : np.random.randint(0,10,7)})
>>> df_obj1
data key
0 4 b
1 3 b
2 8 a
3 1 c
4 6 a
5 1 a
6 6 b
>>> df_obj2 = pd.DataFrame({'key': ['a', 'b', 'd'], 'data' : np.random.randint(0,10,3)})
>>> df_obj2
data key
0 9 a
1 1 b
2 7 d
#suffixes若不指定,默认是_x,_y
>>> print(pd.merge(df_obj1, df_obj2, on='key'))
data_x key data_y
0 4 b 1
1 3 b 1
2 6 b 1
3 8 a 9
4 6 a 9
5 1 a 9
# 也可指定后面添加的是_left,_right
>>> print(pd.merge(df_obj1, df_obj2, on='key', suffixes=('_left', '_right')))
data_left key data_right
0 4 b 1
1 3 b 1
2 6 b 1
3 8 a 9
4 6 a 9
5 1 a 9
1-1-7按索引连接
left_index:使用左边DataFrame对象的行索引作为连接键
right_index:使用右边DataFrame对象的行索引作为连接键
>>> print(df_obj1)
data1 key
0 7 b
1 3 b
2 8 a
3 9 c
4 0 a
5 6 a
6 1 b
>>> print(df_obj2)
data2
a 6
b 4
d 9
>>> print(pd.merge(df_obj1, df_obj2, left_on='key', right_index=True))
data1 key data2
0 7 b 4
1 3 b 4
6 1 b 4
2 8 a 6
4 0 a 6
5 6 a 6
2.数据合并
沿轴方向将多个对象合并到一起,和连接不同,合并是多张表首尾连接合并到一块,而连接是按相同的列进行连接
2-1.numpy里面concatenate
axis参数 1轴方向是行,两个数据的行部分首尾连接
>>> arr1 = np.random.randint(0, 10, (3, 4))
>>> arr2 = np.random.randint(0, 10, (3, 4))
>>> print(arr1)
[[2 5 6 6]
[9 4 7 8]
[7 3 8 8]]
>>> print(arr2)
[[5 8 2 3]
[4 5 4 1]
[2 9 8 1]]
>>> print(np.concatenate([arr1, arr2])) #首尾连接 (6*3)
[[2 5 6 6]
[9 4 7 8]
[7 3 8 8]
[5 8 2 3]
[4 5 4 1]
[2 9 8 1]]
>>> print(np.concatenate([arr1, arr2], axis=1)) #行首尾连接 (3*6)
[[2 5 6 6 5 8 2 3]
[9 4 7 8 4 5 4 1]
[7 3 8 8 2 9 8 1]]
2-2.pd.concat
axis参数 1 轴方向是行,两个数据的行部分首尾连接
join指定合并方式,默认为outer
series行索引无重复
>>>ser_obj1 = pd.Series(np.random.randint(0, 10, 5), index=range(0,5))
>>>ser_obj2 = pd.Series(np.random.randint(0, 10, 4), index=range(5,9))
>>> ser_obj3 = pd.Series(np.random.randint(0, 10, 3), index=range(9,12))
>>> print(ser_obj1)
0 2
1 5
2 9
3 9
4 7
dtype: int32
>>> print(ser_obj2)
5 8
6 1
7 9
8 6
dtype: int32
>>> print(ser_obj3)
9 2
10 1
11 5
dtype: int32
#默认按列进行连接,同时是外连接
>>> print(pd.concat([ser_obj1, ser_obj2, ser_obj3]))
0 2
1 5
2 9
3 9
4 7
5 8
6 1
7 9
8 6
9 2
10 1
11 5
dtype: int32
#axis = 1 按行连接
>>> print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1))
0 1 2
0 2.0 NaN NaN
1 5.0 NaN NaN
2 9.0 NaN NaN
3 9.0 NaN NaN
4 7.0 NaN NaN
5 NaN 8.0 NaN
6 NaN 1.0 NaN
7 NaN 9.0 NaN
8 NaN 6.0 NaN
9 NaN NaN 2.0
10 NaN NaN 1.0
11 NaN NaN 5.0
#join默认outer外连接,"inner"內连接(数据是交集),如果没有交集数据,则去除NaN所在行/列
>>> print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1, join="inner"))
Empty DataFrame
Columns: [0, 1, 2]
Index: []
>>> print(pd.concat([ser_obj1, ser_obj2, ser_obj3], join="inner"))
0 2
1 5
2 9
3 9
4 7
5 8
6 1
7 9
8 6
9 2
10 1
11 5
dtype: int32
2-3.eries行索引有重复
ser_obj1 = pd.Series(np.random.randint(0, 10, 5), index=range(5))
ser_obj2 = pd.Series(np.random.randint(0, 10, 4), index=range(4))
ser_obj3 = pd.Series(np.random.randint(0, 10, 3), index=range(3))
# 默认按列进行连接,同时是外连接
>>> print(pd.concat([ser_obj1, ser_obj2, ser_obj3]))
0 6
1 6
2 9
3 7
4 6
0 8
1 5
2 0
3 1
0 7
1 4
2 5
dtype: int32
# axis = 1 按行连接
>>> print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1))
0 1 2
0 6 8.0 7.0
1 6 5.0 4.0
2 9 0.0 5.0
3 7 1.0 NaN
4 6 NaN NaN
# join默认outer外连接,"inner"內连接(数据是交集),如果没有交集数据,则去除NaN所在行/列
>>> print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1, join="inner"))
0 1 2
0 6 8 7
1 6 5 4
2 9 0 5
2-3.DataFrame合并时同时查看行索引和列索引有无重复
>>> df_obj1 = pd.DataFrame(np.random.randint(0, 10, (3, 2)), index=['a', 'b', 'c'], columns=['A', 'B'])
>>> df_obj2 = pd.DataFrame(np.random.randint(0, 10, (2, 2)), index=['a', 'b'], columns=['C', 'D'])
>>> print(df_obj1)
A B
a 4 4
b 8 8
c 9 4
>>> print(df_obj2)
C D
a 8 4
b 1 1
# 默认是按行连接
>>> print(pd.concat([df_obj1, df_obj2]))
A B C D
a 4.0 4.0 NaN NaN
b 8.0 8.0 NaN NaN
c 9.0 4.0 NaN NaN
a NaN NaN 8.0 4.0
b NaN NaN 1.0 1.0
# 指定轴方向
>>> print(pd.concat([df_obj1, df_obj2], axis=1))
A B C D
a 4 4 8.0 4.0
b 8 8 1.0 1.0
c 9 4 NaN NaN
#指定轴方向,按内连接(NaN所在的行/列将被去除)
>>> print(pd.concat([df_obj1, df_obj2], axis=1, join='inner'))
A B C D
a 4 4 8 4
b 8 8 1 1
3.数据转换
3-1.处理重复数据
duplicated() 返回布尔型Series表示每行是否为重复行
>>> df_obj = pd.DataFrame({'data1' : ['a'] * 4 + ['b'] * 4, 'data2' : np.random.randint(0, 4, 8)})
>>> print(df_obj)
data1 data2
0 a 3
1 a 3
2 a 3
3 a 3
4 b 2
5 b 3
6 b 3
7 b 3
>>> df_obj = pd.DataFrame({'data1' : ['a'] * 4 + ['b'] * 4, 'data2' : np.random.randint(0, 4, 8)})
>>> print(df_obj)
data1 data2
0 a 3
1 a 3
2 a 3
3 a 3
4 b 2
5 b 3
6 b 3
7 b 3
>>> df_obj = pd.DataFrame({'data1' : ['a'] * 4 + ['b'] * 4, 'data2' : np.random.randint(0, 4, 8)})
>>> print(df_obj)
data1 data2
0 a 3
1 a 3
2 a 3
3 a 3
4 b 2
5 b 3
6 b 3
7 b 3
#是否有重复行,和之前的行进行对比判断,如果有重复,则返回true,否则 false
>>> print(df_obj.duplicated())
0 False
1 True
2 True
3 True
4 False
5 False
6 True
7 True
dtype: bool
3-2.过滤重复行
drop_duplicates()默认判断全部列
如果某一行数据和之前的列重复,则去除那一行
可以指定按某一列判断
>>> print(df_obj.drop_duplicates())
data1 data2
0 a 3
4 b 2
5 b 3
>>> print(df_obj.drop_duplicates("data2"))
data1 data2
0 a 3
4 b 2
3-3.根据map传入的函数对每行或每列进行转换
Series根据map传入的函数对每行或每列进行转换
>>> ser_obj = pd.Series(np.random.randint(0,10,10))
>>> print(ser_obj)
0 7
1 6
2 1
3 3
4 7
5 1
6 2
7 3
8 7
9 6
dtype: int32
>>> print(ser_obj.map(lambda x:x**2))
0 49
1 36
2 1
3 9
4 49
5 1
6 4
7 9
8 49
9 36
dtype: int64
3-4.数据替换
replace根据值的内容进行替换
接收两个参数,第一个参数的值替换为第二个参数的值
>>> ser_obj = pd.Series(np.random.randint(0,10,10))
>>> print(ser_obj.replace(5,100)) #把所有5替换为100
0 2
1 8
2 4
3 8
4 0
5 2
6 8
7 1
8 100
9 9
dtype: int32
>>> print(ser_obj.replace([4,5],100)) # 多个值替换一个值
0 2
1 8
2 100
3 8
4 0
5 2
6 8
7 1
8 100
9 9
dtype: int32
>>> print(ser_obj.replace([4, 7], [-100, -200]))# 多个值替换多个值
0 2
1 8
2 -100
3 8
4 0
5 2
6 8
7 1
8 5
9 9
dtype: int64
4.数据重构
4-1.stack:DataFrame->Series
>>> df_obj = pd.DataFrame(np.random.randint(0,10, (5,2)), columns=['data1', 'data2'])
>>> print(df_obj)
data1 data2
0 8 8
1 0 2
2 7 5
3 2 7
4 5 0
>>> stacked = df_obj.stack()
>>> print(stacked)
0 data1 8
data2 8
1 data1 0
data2 2
2 data1 7
data2 5
3 data1 2
data2 7
4 data1 5
data2 0
dtype: int32
4-2.数据重构unstack:Series->DataFrame
>>> print(stacked.unstack())
data1 data2
0 8 8
1 0 2
2 7 5
3 2 7
4 5 0