PS:看起来好像不支持MathJax,文章中的数学公式都没渲染出来,大家将就点看吧...(或者可以访问我的个人博客:http://blog.leanote.com/post/gaunthan/%E5%86%B3%E7%AD%96%E6%A0%91%E5%AD%A6%E4%B9%A0%E4%B8%8EID3%E7%AE%97%E6%B3%95%E5%AE%9E%E7%8E%B0)
决策树学习是以实例为基础的归纳学习,它从一类无序、无规则的事物(也就是概念)中推理出决策树表示的分类规则。
决策树
所谓决策树就是一棵表示“怎么做决定”的树。比如你现在考虑是否要去跑步,那么你也许会以这样的顺序来考虑:
- 天气怎么样?如果下雨我就不去了;不下的话,我再考虑考虑。
- 我状态怎么样?如果良好就出发吧,不然就算了吧。
如果将上面这个考虑(做决定)过程转化为一棵决策树,它会是下面这个样子的:

注意上面列出的两个点之间是有优先级的,第一点显然是我们先考虑的。好的决策树的层次就表现了良好优先级,在顶层的属性(如“天气”),其决策优先级要高,这也意味着这一属性是可以最快导出结果的。
上面例子的决策树碰巧是一棵二叉树,实际上决策树可以是任意多叉的。
决策树学习
决策树学习采用的是自顶向下的递归方法,决策树的每一层结点依照某一属性值向下分为子结点,待分类的实例在每一结点处与该结点相关的属性值进行比较,根据不同的比较结果向相应的子节点扩展,这一过程在到达决策树的叶结点时结束,此时得到结论。
从根结点到叶结点的每一条路径都对应着一条合理的规则,规则间各个部分(各个层的条件)的关系是合取关系。整个决策树就对应着一组析取的规则。决策树学习算法的最大优点是,它是可以自学习的。
在学习的过程中,不需要使用者了解过多背景知识,只需对训练例子进行较好的标注,就能够进行学习。如果在应用中发现不符合规则的实例,程序会询问用户该实例的正确分类,从而生成新的分支和叶子,并添加到树中。
决策树学习相关定义
决策树学习算法是以信息熵为基础的。
下面是一些相关的定义:
自信息量
设信源发出的概率为,在收到符号之前,收信者对的不确定性定义为的自信息量。其中,
信息熵
自信息量只能反映符号的不确定性,而信息熵用来度量整个信源整体的不确定性,定义为:
条件熵
设信源为,收信者收到信息,用条件熵来描述收信者在收到后对的不确定性估计。设的符号,的符号,为当为时,为的概率,则有:
平均互信息量
平均互信息量用来表示信号所能提供的关于的信息量的大小,用表示:
决策树的构建
构建一棵决策树要解决4个问题:
- 收集待分类的数据。这些数据的所有属性应该是完全标注的。
- 设计分类原则。即数据的哪些属性可以被用来分类,以及如何将该属性量化。
- 分类原则的选择。即在众多分类准则中,每一步选择哪一准则使最终的树更令人满意。
- 设计分类停止条件。实际应用中数据的属性很多,真正有分类意义的属性往往是有限几个,因此在必要的时候应该停止数据集分类,这些准则包括:
- 该结点包括的数据太少不足以分裂;
- 继续分裂数据集对树生成的目标没有贡献;
- 树的深度过大不宜再分。
通用的决策树分裂目标是整棵树的熵总量最小,每一步分裂时,选择使熵减小最小的准则,这种方案使最具分类潜力的准则最先被提取出来。
构建流程大致如下图所示:

ID3算法C++实现
ID3算法将信息熵的下降速度作为属性选择标准。
按照上一节提到的构建过程,我们以一个例子来说明具体如何应用ID3来构建决策树。
案例
现有某流感训练数据集,预定义两个类别:患流感和不患流感。其数据集如下所示:
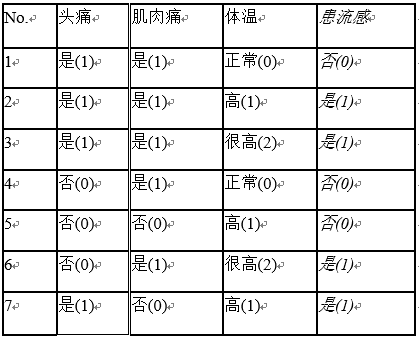
构建过程
按照前面的流程图,第一步骤是计算各个属性的条件熵。条件熵的求取又依赖到信息熵,因此先讲述如何手算条件熵。
对于上面的例子,属性“体温”的条件熵的计算过程为:
- 分别计算每个值的信息熵,有
- 求条件熵
由于属性”体温“取“正常”或“很高”时,其结论均是单一的(一边倒),因此其信息熵为零(嘛)。而当取“高”时,有3个样本,这3个样本中有两个结论是“患流感”,另一个是“不患流感”,因此其信息熵不为零。
对于其他的属性,同理可求得:
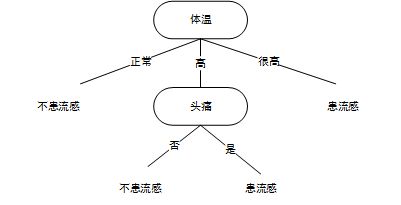
由于“体温”的条件熵最小,因此决策树的第一个结点应该选用“体温”作为判断属性。
最后生成的决策树如下所示:
设计思路
设计样本文件内容格式
为了能够简单使用样本数据,可以将文件内容置为以下:
headache courbature temperature hasBirdFlu
1 1 0 0
1 1 1 1
1 1 2 1
0 1 0 0
0 0 1 0
0 1 2 1
1 0 1 1
第一行表出参与决策的属性以及结论。第二行到最后一行是样本数据,用数值来表达属性的取值。
属性列表、样本集的数据结构设计
得益于C++强大的容器库,可以使用 list 来表示这两个逻辑体:
struct Sample; // 代表一行样本数据
typedef std::list Samples; // 样本集类型
...
typdef std::string Attribute; // 代表一个属性
typdef std::list Attributes; // 属性列表类型
决策树的数据结构设计
决策树本身是一棵树,而树的表示方式有好几种。简单起见,选择孩子兄弟表示法,即每棵树的根结点拥有一个指向其第一个孩子(即第一棵子树)和一个指向其兄弟(即其父亲的下一棵子树)的指针。
为了方便看出结点的决策,可以选用“(属性,属性值;结果)”这一格式来表示一个结点的内容,其中,根节点为空,内部结点没有“结果”项。
信息熵的求取
信息熵的求取涉及到属性的取值,以及属性取该值时的结论分布。下面的函数就是用于求取某一个属性取特定值时的信息熵,过程中的GetValueCntOfAttr()求取该属性取特定值时的样本个数(如“温度”取“正常”时有2个样本),GetTrueCntForValueOfAttr()求取该属性性取特定值时,结论为真的个数(如“温度”取“正常”时有0个为真的结论):
double CalcEntropyOf(const Samples& samples,
const Attribute& attr,
double attrValue)
{
double total = GetValueCntOfAttr(samples, attr, attrValue);
double trueResult = GetTrueCntForValueOfAttr(
samples, attr, attrValue);
// all has the same value
if(total == trueResult || trueResult == 0)
return 0;
double trueRate = trueResult / total;
double entropy = -(trueRate * log2(trueRate)) -
((1 - trueRate) * log2(1 - trueRate));
return entropy;
}
条件熵的求取
求一个属性的条件熵,需要先求出其各个取值的信息熵,然后根据求取条件熵的公式求取该属性的条件熵即可。注意过程中的GetValueTypeCntOfAttr()求取属性的值种类(如“温度”有3个取值类型):
double CalcConditionalEntropyOf(const Samples& samples,
const Attribute& attr)
{
// calculate conditional entropy
size_t valueTypeCnt = GetValueTypeCntOfAttr(samples, attr);
double total = samples.size();
double conditionalEntropy = 0;
for(size_t value = 0; value != valueTypeCnt; ++value) {
conditionalEntropy += GetValueCntOfAttr(samples, attr, value)
/ total *
CalcEntropyOf(samples, attr, value);
}
return conditionalEntropy;
}
决策树的生成
DecisionTree* GenerateDecisionTree(const Samples& samples,
const Attributes& attributes,
const DecisionNode& root)
{
if(attributes.empty()) {
DecisionTree* tree = new DecisionTree(root);
return tree;
}
DecisionTree* tree = new DecisionTree(root);
const Attribute bestAttr = FindBestAttribute(samples, attributes);
const size_t valueTypeCnt = GetValueTypeCntOfAttr(
samples, bestAttr);
for(size_t value = 0; value != valueTypeCnt; ++value) {
double entropy = CalcEntropyOf(samples, bestAttr, value);
if(entropy == 0) { // already know the decision
size_t trueCnt = GetTrueCntForValueOfAttr(
samples, bestAttr, value);
size_t decision = trueCnt > 0 ? 1 : 0;
DecisionNode subTreeNode(DN_LEAF_TYPE, bestAttr,
value, decision);
DecisionTree* subTree = new DecisionTree(subTreeNode);
tree->addChild(subTree);
}else {
DecisionNode subTreeNode(DN_INNER_TYPE, bestAttr, value);
// generate new attribute list
Attributes newAttrs(attributes);
newAttrs.remove(bestAttr);
// generate new Samples
Samples newSamples = GenerateSamplesByAttrValue(
samples, bestAttr, value);
DecisionTree* subTree = GenerateDecisionTree(
newSamples, newAttrs, subTreeNode);
tree->addChild(subTree);
}
}
return tree;
}
总结
如果你懂得了怎么手动进行这一过程,那么你离编码实现也不远了。
完整的程序代码我已经放到了github上:ID3-Implement。由于能力有限,不免出错。如果您发现了错误,请一定联系我!