算法笔记(一):复杂度分析:最好、最坏、平均、均摊
- 数据结构指的是“一组数据的存储结构”,
- 算法指的是“操作数据的一组方法”。
- 数据结构是为算法服务的,算法是要作用再特定的数据结构上的。 效率和资源消耗的度量衡--复杂度分析。
- 数据结构和算法解决是“如何让计算机更快时间、更省空间的解决问题”,因此需从执行时间和占用空间两个维度来评估数据结构和算法的性能。分别用时间复杂度和空间复杂度两个概念来描述性能问题,二者统称为复杂度。
不管是应付面试还是工作需要,只要集中精力逐一攻克以下20 个最常用的最基础数据结构与算法,掌握了这些基础的,再学更加复杂的就会非常容易、非常快。学习它们的“来历”“自身的特点”“适合解决的问题”以及“实际的应用场景;
点我!一个将指定算法可视化,能方便理解的网站
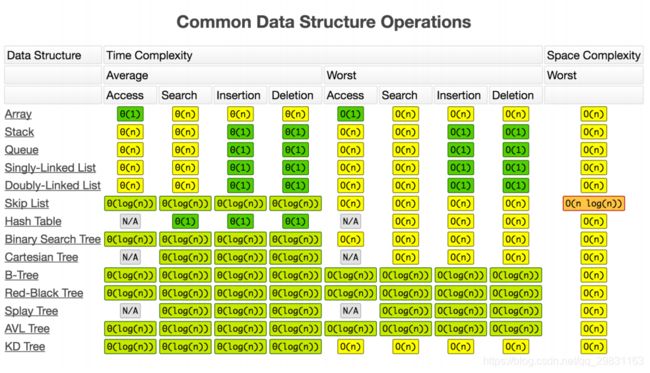
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树;
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算 法、动态规划、字符串匹配算法。
学习方法篇
- 零基础的可看看《大话数据结构》和《算法图解》。 刷题的话leetcode比较火。
- 边学边练,适度刷题; 给自己设立一个切实可行的目标,:每节课后的思考题都认真思考,每周写总结。
- 多问、多思考、多互动;谈一个事物/概念的时候,需要问自己三个终极问题--是什么?为什么?怎么样?
- 找到几个人一起学习,一块儿讨论切磋,有问题及时寻求老师答疑。
- 不懂的可以先沉淀一下,过几天再重新学一 遍。想听一遍、看一遍就把所有知识掌握,这肯定是不可能的。学习知识的过程是反复迭代、不断沉淀的过程。
- 要记住这些算法的特点、应用场景,真要用的时候 能想到并快速弄懂就OK了; 完全不需要死记硬背。
- 所有数据结构与算法用C++、Java、Python实现一遍;书上的每一段代码都敲一边!《C++ primer》
 图1 算法&数据结构主要内容
图1 算法&数据结构主要内容
复杂度分析是整个算法学习的精髓,“熟练”复杂度分析的关键在于多看案例,多分析,
事后统计法把代码跑一遍,通过统计、监控,就能得到算法执行的时间和占用的内存大小,缺点就是测试结果非常依赖测试环境硬件和数据规模。eg对同一个排序算法,待排序数据的有序度不一样,排序的执行时间就会有很大的差别。

大 O 复杂度表示法
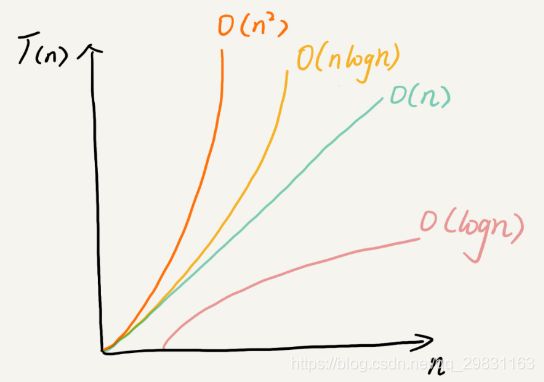
大 O 时间复杂度实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度(asymptotic time complexity),简称时间复杂度。可以粗略地分为两类,多项式量级和非多项式量级。其中非多项式量级只有两个:O(2n) 和 O(n!)。当数据规模 n 越来越大时,非多项式量级算法的执行时间会急剧增加,是非常低效的算法。

算法的执行效率就是算法代码执行的时间。假设每行代码执行的时间都一样为 unit_time。当 n 很大时,公式中的低阶、常量、系数三部分并不左右增长趋势,所以都可以忽略。只需要记录一个最大阶的量级就可以了。
时间复杂度的全称是渐进时间复杂度,表示算法的执行时间与数据规模之间的增长关系。如何分析一段代码的时间复杂度?
- 1.只关注循环执行次数最多的一段代码
在分析一个算法、一段代码的时间复杂度的时候,也只关注循环执行次数最多的那一段代码就可以了。
- 2. 加法法则:总复杂度等于量级最大的那段代码的复杂度
总的时间复杂度就等于量级最大的那段代码的时间复杂度。如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)+T2(n)=max(O(f(n)), O(g(n))) =O(max(f(n), g(n))).
即便这段代码循环 10000 次、100000 次(对代码的执行时间会有很大影响),只要是一个已知的数(常量级的执行时间),跟 n 无关。当 n 无限大的时候,就可以忽略。时间复杂度的概念表示的是一个算法执行效率与数据规模增长的变化趋势,所以不管常量的执行时间多大,我们都可以忽略掉。因为它本身对增长趋势并没有影响。
- 3. 乘法法则:嵌套循环代码的复杂度等于嵌套内外代码复杂度的乘积
如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)*T2(n)=O(f(n))*O(g(n))=O(f(n)*g(n)).

O(1) 只是常量级时间复杂度的一种表示方法,并不是指只执行了一行代码,而是代码的执行时间不随 n 的增大而增长。一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)。
在对数阶时间复杂度的表示方法里,我们忽略对数的“底”,不管是以 2 为底、以 3 为底,还是以 10 为底,统一表示为 O(logn)。因为对数之间是可以互相转换的,log3n 就等于 log32 * log2n,所以 O(log3n) = O(C * log2n),其中 C=log32 是一个常量。在采用大 O 标记复杂度的时候,可以忽略系数,即 O(Cf(n)) = O(f(n))。所以,O(log2n) 就等于 O(log3n)。
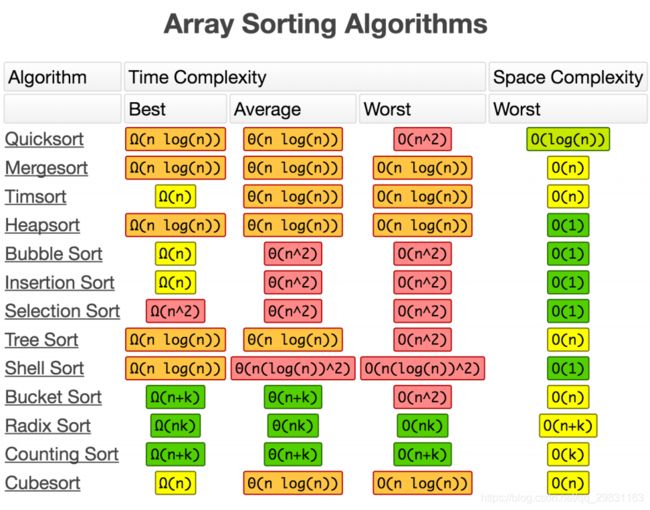
如果一段代码的时间复杂度是 O(logn),我们循环执行 n 遍,时间复杂度就是 O(nlogn) 。归并排序、快速排序的时间复杂度都是 O(nlogn)。
代码的复杂度由两个数据的规模m 和 n 来决定时,由于我们无法事先评估 m 和 n 谁的量级大,在表示复杂度的时候不能简单地省略掉其中一个。此时需要将加法规则改为:T1(m) + T2(n) = O(f(m) + g(n))。但乘法法则仍有效:T1(m)*T2(n) = O(f(m) * f(n))。
空间复杂度分析
空间复杂度全称就是渐进空间复杂度(asymptotic space complexity),表示算法的存储空间与数据规模之间的增长关系。
常见的空间复杂度就是 O(1)、O(n)、O(n2 ),空间复杂度分析比时间复杂度分析要简单很多。
存储一个二进制数,输入规模(空间复杂度)是O(logn) bit。 比如8用二进制表示就是3个bit。16用二进制表示就是4个bit。以此类推 n用二进制表示就是logn个bit
复杂度也叫渐进复杂度,包括时间复杂度和空间复杂度,用来分析算法执行效率与数据规模之间的增长关系,可以粗略地表示,越高阶复杂度的算法,执行效率越低。常见的复杂度从低阶到高阶有:O(1)、O(logn)、O(n)、O(nlogn)、O(n2 )。
项目之前都会进行性能测试,再做代码的时间复杂度、空间复杂度分析,是不是多此一举呢?而且,每段代码都分析一下时间复杂度、空间复杂度,是不是很浪费时间呢?性能测试与复杂度分析不冲突,原因如下:
1、性能测试是依附于具体的环境,如SIT、UAT机器配置及实例数量不一致结果也有差别。
2、复杂度分析是独立于环境的,可以大致估算出程序所执行的效率。
同一段代码在不同输入的情况下的复杂度量级有可能不一样,引入下面这几个复杂度概念可以更全面地分析一段代码的执行效率。大多数情况下不需要区别分析它们。均摊只是其中一种复杂度度量方法。
最好情况时间复杂度(best case time complexity):在最理想的情况下执行这段代码的时间复杂度。
最坏情况时间复杂度(worst case time complexity):在最糟糕的情况下执行这段代码的时间复杂度。
平均情况时间复杂度(average case time complexity):把每种情况发生的概率也考虑进去的平均时间复杂度为概率论中的加权平均值(也叫作期望值),所以平均时间复杂度的全称应该叫加权平均时间复杂度或者期望时间复杂度。在大多数情况下,我们并不需要区分最好、最坏、平均情况时间复杂度三种情况。
均摊时间复杂度(amortized time complexity):对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,且这些操作之间存在前后连贯的时序关系,此时可以看看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。
平均情况时间复杂度
eg要查找的变量 x 在一个无序数组中的位置,有 n+1 种情况:在数组的 0~n-1 位置中和不在数组中。在最理想的情况下,要查找的变量 x 正好是数组的第一个元素,时间复杂度就是 O(1)。但如果数组中不存在变量 x,就需要把整个数组都遍历一遍,时间复杂度就成了 O(n)。把每种情况下,查找需要遍历的元素个数累加起来,然后再除以 n+1,就可以得到需要遍历的元素个数的平均值(平均情况时间复杂度,简称为平均时间复杂度)。

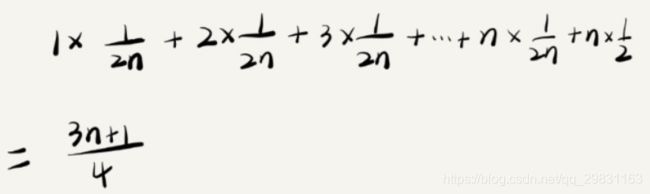
但这n+1 种情况出现的概率并不是一样的。要查找的变量 x,要么在数组里,要么就不在数组里。假设在数组中与不在数组中的概率都为 1/2并且 x出现在 0~n-1 这 n 个位置的概率也是一样的为 1/n。根据概率乘法法则,要查找的数据出现在 0~n-1 中任意位置的概率就是 1/(2n)。用大 O 表示法来表示,去掉系数和常量,这段代码的加权平均时间复杂度仍然是 O(n)。
均摊时间复杂度
insert()第一个区别于 find() 的地方:
- find() 函数在极端情况下,复杂度才为 O(1)。但 insert() 在大部分情况下,时间复杂度都为 O(1)。只有个别情况下,复杂度才比较高,为 O(n)。
- 对于 insert() 函数来说,O(1) 时间复杂度的插入和 O(n) 时间复杂度的插入,出现的频率是非常有规律的,而且有一定的前后时序关系,一般都是一个 O(n) 插入之后,紧跟着 n-1 个 O(1) 的插入操作,循环往复。因此不需要找出所有的输入情况及相应的发生概率再计算加权平均值。 ,而是使用摊还分析法来分析算法的均摊时间复杂度。
- 每一次 O(n) 的插入操作都会跟着 n-1 次 O(1) 的插入操作,所以把耗时多的那次操作均摊到接下来的 n-1 次耗时少的操作上,均摊下来,这一组连续的操作的均摊时间复杂度就是 O(1)。这就是均摊分析的大致思路。
- 在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度。均摊时间复杂度可看作一种特殊的平均时间复杂度。
对于清空数组的问题: 对于可反复读写的存储空间,使用者认为它是空的它就是空的,只关心要存的新值!清空把下标指到第一个位置就可以了!如果你定义清空是全部重写为0或者某个值,那也可以!
count=1;count被重置为1,之后再插入的数据就会覆盖掉原来的数据。就相当于将原数组清空了。
| 知识点 | 难易程度 | 重要 程度 |
掌握程度 | 涉及内容 |
| 复杂度分析 | Medium | 10 分 |
能分析大部分数据结构和算法的时间、空 间复杂 | 递推公式和递归树 |
| 数组、栈、队列 | Easy | 8分 | 实现动态数组、栈、队列 | |
| 链表 | Medium |
9 | 能轻松写出经典链表题目代码,比如链表反转、求中间结点等 |
|
| 递归 | Hard | 10 分 | 轻松写出二叉树遍历、八皇后、背包问题、DFS 的递归代码 | 斐波那契数列、求阶乘,归并排序、快速排序、二 叉树的遍历、求高度,回溯八皇后、背包问题等。 |
| 排序、 二分查找 |
Easy | 7 | 能自己把各种排序算法、二分查找及其变体代码写一遍 |
|
| 跳表 |
Medium | 6 | 初学者可以先跳过,不需要掌握代码实现 |
|
| 散列表 | Medium | 8 | 代码实现一个拉链法解决冲突的散列表 |
|
| 哈希算法 |
Easy | 3 | 初学者可以略过 | |
| 二叉树 |
Medium | 9 | 能代码实现二叉树的三种遍历算法、按层遍历、求高度等经典二叉树题目 |
|
| 红黑树 | Hard | 3 | 初学者略过 | |
| B+ 树 | Medium | 5 | 能看懂即可 | |
| 堆与堆排序 | Medium | 8 | 能代码实现堆、堆排序,并且掌握堆的三种应用(优先级队列、Top k、中位 数) |
|
| 图的表示 |
Easy | 8 | 能自己代码实现 邻接矩阵、邻接表、逆邻接表 |
邻接矩阵、邻接表、逆邻接表 |
| 深度广度优先搜索 |
Hard | 5 | 能代码实现广度优先、深度优先搜索算法 |
队列,递归 |
| 拓扑排序、最短路径、A* 算法 |
Hard | 7 | 有时间再看 | |
| 字符串匹配(BF、RK) |
Easy
|
3 | 能实践 BF 算法,能看懂 RK 算法 | |
| 字符串匹配(BM、KMP、AC 自动机) | Hard
|
7 | 初学者不用看,理解看懂即可 | |
| 字符串匹配(Trie) |
Medium | 6 | 能看懂,知道特点、应用场景即可,不要求代码实 | |
| 位图
|
Easy | 10 | 看懂即可,能自己实现一个位图结构最好
|
|
| 四种算法思想 |
Hard | 可以放到最后,但是一定要掌握!做到能实现 Leetcode 上 Medium 难度的题 目 |
贪心、分治、回溯、动态规划 |