基于selenium的大麦网自动抢票脚本实测(新年第一篇)
本次试验对象为大麦网 2020上海林俊杰演唱会 ,针对大家关心的能不能抢到票的问题。先在开头说明结论
1.以目前的脚本情况,在不经过大量优化的情况下 寄托于python的速度去和票贩子抢票是 不可能的。
2.这个项目不太适用于纯小白,因为selenium坑太多,但博主这种有一些前端基础的半小白还是收获很多。
3.本项目来自于知乎用户Oliver0047,地点https://zhuanlan.zhihu.com/p/56697166,由于时间原因,大麦网的前端格式发生了很大的变化,因此主体内容需要根据情况更改,但原理一致。
4.在线求 两张 林俊杰上海演唱会门票,单价780以下的联系我!!!
—————————————以下进入正文内容—————————————————
1. selenium安装与使用
selenium是一种打包好的web自动化库,用来模拟用户操作,本项目的内容重点在于模拟流程,即使用爬虫和自动化手段,将你平时的登陆,点击按钮等行为转成py代码操作。
首先默认python装好,假如使用的是pycharm直接在setting里找到selenium安装即可
除此之外你还要安装浏览器对应的driver,推荐使用Chrome和火狐,如果是谷歌就要安装Chromedriver
并且根据浏览器版本的不同,Chromedriver的版本也不同,在设置中找到版本号并与之对应下载。
并将其与脚本的py文件放到同一目录下。

安装完成后首先导入库,并将
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
from time import sleep
import time
import pickle
import os
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#本次加载登陆的网页
login_url = "https://passport.damai.cn/login?ru=https%3A%2F%2Fwww.damai.cn%2F"
#使用此命令访问,在完整代码中我会把下面三行注销掉
driver = webdriver.Chrome()
driver.maximize_window()
driver.get(login_url)运行结果如下图所示,当发现上方出现Chrome正在受自动软件的控制时,说明已经启用成功,我们将从这个页面登陆。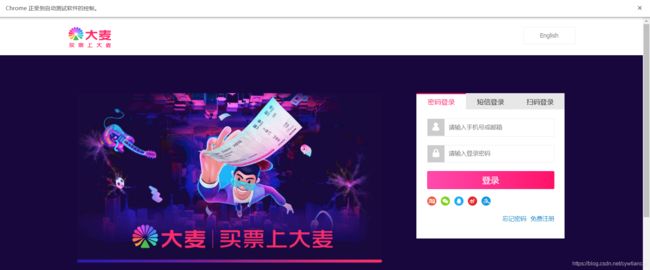
2. 平台账号登陆
原作者将所有内容都写在一个class下面,非常清晰,值得学习。
class Concert(object):
def __init__(self, name, date, price, place, real_name, method=1):
self.name = name # 歌星
self.date = date # 日期序号优先级,比如,如果第二个时间可行,就选第二个
self.price = price # 票价序号优先级,道理同上
self.place = place # 地点
self.status = 0 # 状态,表示如今进行到何种程度
self.login_method = 1 # {0:模拟登录,1:Cookie登录}自行选择登录方式
self.real_name = real_name # 实名者序号针对账号自动化登陆,原作者给出了两个方法:一是模拟账号输入登陆;二是使用cookie登陆。
一是模拟账号点击登陆;二是使用cookie登陆。
一号方法经过测试现在已经不能使用,原因是大麦网的反爬能力,当其检测到浏览器下在selenium下时,就无法登陆到内部,当然网上也有一些绕过检测的教程 https://www.jianshu.com/p/4dd2737a3048 有兴趣的同学可以学习下。
二号方法,是通过 自己扫码登陆 记录下的cookie信息实现自动化登陆,记录的cookie信息可能一段时间就需要重新生成一下。
#生成cookie的函数
def get_cookie(self):
self.driver.get(login_url)
#切换到iframe内容
self.driver.switch_to.frame("alibaba-login-box");
#点击扫码登陆
self.driver.find_element_by_xpath("/html/body/div[1]/div/div[1]/div[3]").click()
#开始扫码
sleep(10)
#保存cookie
pickle.dump(self.driver.get_cookies(), open("cookies.pkl", "wb"))
print("###Cookie保存成功###")其中有个小点,登陆页面里还内置了另外一个页面。所以不能直接全网页的方式爬取,需要先使用self.driver.switch_to.frame定位到内置页面,再定位到扫码处。
#载入函数
def set_cookie(self):
try:
cookies = pickle.load(open("cookies.pkl", "rb")) # 载入cookie
for cookie in cookies:
cookie_dict = {
'domain': '.damai.cn', # 必须有,不然就是假登录
'name': cookie.get('name'),
'value': cookie.get('value'),
"expires": "",
'path': '/',
'httpOnly': False,
'HostOnly': False,
'Secure': False}
#加载cookie
self.driver.add_cookie(cookie_dict)
登陆代码,只需获取和载入两步。
#登陆函数
def login(self):
if self.login_method == 1:
if not os.path.exists('cookies.pkl'): # 如果不存在cookie.pkl,就获取一下
self.get_cookie()
else:
self.driver.get(login_url)
self.set_cookie()3. 演唱会选择和购票
接下来,主要就是爬虫相关的内容,具体的话就是定位到这个搜索框,填入内容,然后点击啥的,没啥特别好说的,关于如何定位,建议用Xpath全定位和class定位,至于页面结构 利用CTRL+SHIFT+C,移动到想使用的组件处就能定位其位置,在F12里右键copy Xpath 即可得到位置,有时候一个div里有多个相同的class,那就需要使用层级定位,先定到父级再定到下面的子级。
def enter_concert(self):
print('###打开浏览器,进入大麦网###')
self.driver = webdriver.Chrome() # 谷歌浏览器
self.driver.maximize_window()
self.login() # 先登录再说
self.driver.get("https://www.damai.cn/")
try:
#主要是验证是否登入成功,用户名检查
locator = (By.XPATH,"/html/body/div[2]/div/div[3]/div[1]/a[2]/div")
#显示等待3s直到验证成功
element = WebDriverWait(self.driver,3).until(EC.text_to_be_present_in_element(locator, self.usr_name))
self.status = 1
print("###登录成功###")
except Exception as d:
print(d)
if self.status == 1:
self.driver.find_elements_by_xpath('/html/body/div[2]/div/div[4]/input')[0].send_keys(self.name) # 搜索栏输入歌星
self.driver.find_elements_by_xpath('/html/body/div[2]/div/div[4]/div[1]')[0].click() # 点击搜索
self.driver.find_elements_by_xpath('/html/body/div[2]/div[2]/div[1]/div[1]/div[2]/div/div/div/span')[0].click()
# 嫌麻烦就对原版代码进行了一些删减
# 获取所有可能演唱会
titles = []
links = []
# 注释的代码表示用图形界面手动选择演唱会,可以自行体会
# root = Tk()
# root.title("选择演唱会")
# v = IntVar()
# v.set(1)
self.choose_result = 0
# def selection():
# self.choose_result=v.get()
# root.destroy()
# 此处的意义为定位到购买页面的url,和演唱会所处的地点是否符合预期
lists = self.driver.find_elements_by_class_name('items__txt__title')
i=0
for li in lists:
word_link=li
#titles.append(word_link.text)
print(word_link)
temp_s = word_link.get_attribute('innerHTML').find('href')+8
temp_e = word_link.get_attribute('innerHTML').find('target')-2
links.append(word_link.get_attribute('innerHTML')[temp_s:temp_e])
print('运行完成')
#确定地点
didian=li.find_element_by_tag_name('a').text[-3:-1]
print(didian)
if didian != self.place:
print('地址错误')
else:
print('地址正确')
self.url = "https:" + links[i]
i=i+1
self.driver.get(self.url) # 载入至购买界面
self.status = 2
print("###选择演唱会###")其中有个小点,find_element_by_id 和 find_elements_by_id是不一样的,后者需要加个[0]。
同样下一步是在购买页面,选择票价,时间,然后点击购买,对于票价我们需要判断其是否有货,有货的先选,其余的按照价格排序选择,时间的话根据个人弹性选择。
def choose_ticket(self):
if self.status == 2:
self.num = 1 # 第一次尝试
time_start = time.time()
while self.driver.title.find('确认订单') == -1: # 如果跳转到了订单结算界面就算这部成功了
if self.num != 1: # 如果前一次失败了,那就刷新界面重新开始
self.status = 2
self.driver.get(self.url)
try:
element = WebDriverWait(self.driver, 3).until(EC.presence_of_element_located((By.CLASS_NAME,"select_right_list_item")))
print('通过验证')
except Exception as e:
print(e)
self.driver.find_elements_by_class_name('perform__order__select perform__order__select__performs')
#datelist= self.driver.find_elements_by_class_name('select_right_list_item')
print('成功找到')
datelist=self.driver.find_elements_by_xpath('/html/body/div[2]/div/div[1]/div[1]/div/div[2]/div[4]/div[3]/div[2]/div')[0].find_elements_by_tag_name('div')
print(len(datelist))
#j = datelist[0].get_attribute('span')
#通过票务判断是否先买
info=self.driver.find_elements_by_xpath('/html/body/div[2]/div/div[1]/div[1]/div/div[2]/div[4]/div[3]/div[2]/div')[0].find_elements_by_class_name('presell')
#判断是否有票
for i in range(len(info)):
INFO=info[i].text
if INFO == '有票':
datelist[i].click()
break
else:
datelist[1].click()
#datelist[2].click()
sleep(1)
print('点击成功')
# 根据优先级选择一个可行票价,
# 先买不缺货的,再买最便宜的
pricepalce=self.driver.find_elements_by_xpath('/html/body/div[2]/div/div[1]/div[1]/div/div[2]/div[4]/div[5]/div[2]/div')[0].find_elements_by_class_name('select_right_list_item')
pricelist=self.driver.find_elements_by_xpath('/html/body/div[2]/div/div[1]/div[1]/div/div[2]/div[4]/div[5]/div[2]/div')[0].find_elements_by_class_name('notticket')
for i in range(len(pricelist)):
PH=pricelist[i].text
if PH == '缺货登记':
continue
else:
pricepalce[i].click()
break
print("###选择演唱会时间与票价###")
#点击购买按钮
cart = self.driver.find_elements_by_xpath('/html/body/div[2]/div/div[1]/div[1]/div/div[2]/div[4]')[0]
sleep(3)
cart.find_elements_by_class_name('buybtn')[0].click()
sleep(3)
self.status = 3
print('已完成跳转')
try:
element = WebDriverWait(self.driver, 3).until(EC.title_is(u'确认订单'))
print("确认定位")
except:
print('###暂无余票###')
#关闭
#self.driver.quit()
time_end = time.time()
print("###经过%d轮奋斗,共耗时%f秒,抢票成功!请确认订单信息###" % (self.num - 1, round(time_end - time_start, 3)))注意点 find_element_by_link_text似乎只能定位里的元素。最后,只需在提交订单页面,判断一下,然后选择乘客,地址 点击提交订单即可进入到支付宝页面。
def check_order(self):
if self.status in [3, 4, 5]:
print('###开始确认订单###')
self.driver.find_element_by_xpath('/html/body/div[2]/div[2]/div/div[2]/div[2]/div[1]/div/label/span[1]/input').click()
print('进入到此阶段')
self.driver.find_element_by_xpath('/html/body/div[2]/div[2]/div/div[9]/button').click() # 同意以上协议并提交订单
try:
element = WebDriverWait(self.driver, 5).until(EC.title_contains('支付'))
self.status = 6
print('###成功提交订单,请手动支付###')
sleep(100)
except:
print('###提交订单失败,请查看问题###')
def finish(self):
self.driver.quit()由于林俊杰已经没票了,所以实验的时候改成张杰即可。。。最后是挨个调用函数。
if __name__ == '__main__':
try:
#在此更改想买的演唱会信息
con = Concert('张杰', [1], [2], '苏州', 1) # 具体如果填写请查看类中的初始化函数
con.enter_concert()
con.choose_ticket()
con.check_order()
except Exception as e:
print(e)
con.finish() —————————————小结—————————————————单次买票时间大约是15.8s,总的来说比较尴尬,我觉得如果要实际使用,还是应该采用 js脚本模拟操作的方式,直接作为插件启用,这样1.不容易被反爬,2.节省了很多的不必要的加载时间 具体的操作以后有机会再更新吧,
原始代码可在csdn的资源里下载,不过没啥必要,太乱了没整理。
今年毕业,下半年忙着干活都没空写,6月份后会将三年论文内容慢慢公布,虽然我作为一个土木专业学生做的都是些半吊子玩意,不过应该是挺好的入门玩具,祝大家新年快乐。