redis--缓存穿透,缓存雪崩,缓存击穿。
1.redis缓存的由来
传统网络访问系统图:

当client访问量增大的时候,数据库会出现性能瓶颈,导致qps低下,解决方案:数据库集群,数据库读写分离。
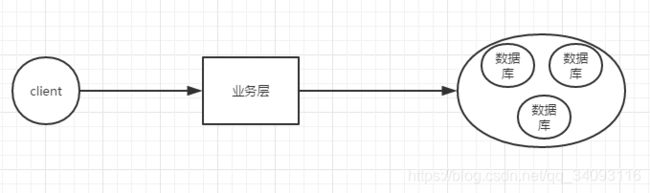
理论上讲,无限新增机器,新增数据库节点,是可以解决这个问题的,但是要考虑资源成本和维护成本。故引出了我们的缓存。
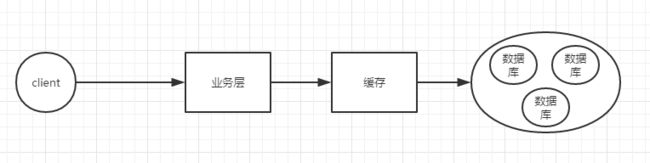
缓存能提高qps的原因是:缓存基于内存运行,数据库基于硬盘运行。这里的缓存在java web中我们一般采用的就是redis。
将热点数据维护在redis中,业务层查询数据的时候优先查询redis,没有再查询数据库。
2.redis缓存会引发的问题以及解决方法
缓存穿透
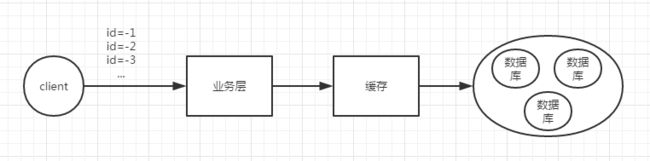
如图,如果我大量的数据库和缓存都不存在的查询条件,去访问,会怎么样,业务层就会绕过redis,每次都去数据库查询一遍,从而当量上来了损耗数据库性能。这就是我们常说的缓存穿透问题。
思考?解决方法,如果让这些不存在的数据在第一次查询数据库之后,缓存里面也保存起来呢

好像是防止了后续无效访问数据库的问题,但随之而来的问题是,当量大起来的时候,redis里面会存在大量的null值,而机器的内存大小是有限的,这样显然是不是长久之计。
怎么办?请看下图

在缓存里面没有查询条件的数据时候,我们在它要去访问数据库之前加上一个过滤器。来控制是否让它去访问数据库,意思就是我们提高了访问数据库的门槛,之前是缓存没有就去数据库,不,现在你得把你的身份证给我验证一下,我再决定是否放行。
那么这个验证的标准是什么呢,比如它把id=-1给我了,我总得去一个地方比对,有人说简单啊,不是说内存快吗,我事先在内存里面把数据库已经存在的id都存一遍,通过这个比对就可以了。好,如果后面有人用name,age等等一系列查询条件去查呢?难道都缓存起来吗,显然不是这样的。因为太耗内存。
怎么办?过滤器总得有个过滤条件,这个条件总得事先就有的,其实上面的思路是对的,现在要解决的是不能让它太消耗内存。bit数组,这个时候有用武之地了,某查询条件下数据库如果有值就在特定的位置标1,简单来说长度为一亿的bit数组,所占内存大小是接近12MB。这也是布隆过滤器的原理。开始上图

如上图,过滤器中定义若干个hash函数,对查询条件进行hash运算,并且与bit数组的长度取模,得到的结果位置标志1,表示该查询条件数据库里有值,可以放行。
问题:为啥要若干个hash函数,因为要减少hash碰撞的概率,那是不是hash函数越多越好呢,这样碰撞的概率也越小,当底下的bit数组长度无穷大的时候是这样的,事实,bit数组的长度是有限的,如果hash函数过多,每一个查询条件hash出来的位置个数也就越多,如果最后少量的查询条件就把bit数组给填满了,那么过滤器就无法起到作用了。
如何平衡hash函数个数,和bit数组长度呢,两个公式:
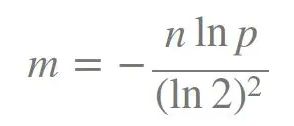

n表示预估数据的数据条数,p为你接受的误判率,m为bit数组的长度,k为hash函数的个数。
误判率说一下,就是两个查询条件,最后经过多个hash函数得到的值都一样,最后其实有一个查询条件其实数据库里并没有值,故此时就会发生误判。
缓存雪崩
上面加完过滤器似乎很完美了,
1.某一时刻,redis里面大量的key值失效,会怎么样,这些数据数据库里面是存在的,所以过滤器中也有,那么肯定也是会放行的,这个时候数据库面对的又是大量的访问;
2.某一时刻,做缓存的redis挂掉了,那么查询redis肯定是没有值的,过滤器中是有的,同样放行,数据库同样面临着大量的访问。
以上两种情况就是所谓的缓存雪崩现象。
怎么解决呢?
情况一:错开key的失效时间。(如果是代码删除key导致的,这个就是bug了)
情况二:redis采用高可用的集群方式,分片存储。即使挂掉了,也是部分放行。
缓存击穿
过滤器也加了,失效时间也错开了,集群也做了,完美吗?
当然是NO,想想redis中key值设置失效是很常见的,那么如果有一个极度热点的数据,在某一刻失效了导致大量访问,这个时候也会直接到数据库那边去,这个时候怎么办。首先告诉你这个问题就是缓存击穿。
有人会说,既然这样,那么这个数据我不设置失效时间不就可以了吗,永远存在。想法很好,但是你怎么知道哪一个数据会是极度热点的呢?拿商品搜索来说,现在疫情,可能口罩搜的特别多,之前可能是杜蕾斯搜的比较多,再之前可能是华为搜的比较多等等,你总不能事先把这些全都设置为永久的吧。或者说你代码逻辑某一时刻删除key的情况也是存在的。
问题来了,怎么解决。先上图
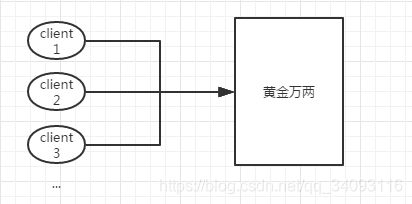
大量的客户端都要去数据库拿黄金万两这条数据,方法:加锁,一个一个来。
如果只有一个jvm,内置锁,显示锁都行。
如果是多个jvm那么就要来分布式锁了。主流分布式锁有:基于数据库分布式锁,基于redis分布式锁,基于zookeeper分布式锁。

分布式锁图,有图就是好哈,client拿完锁之后,如果睡着了,或者说挂掉了怎么办,锁没有还,后面的client不就只能干等着吗,好,我设置过期时间,那么设置多长呢,还有就是说拿锁的人挂掉了,是不是其他的人至少要等你所设置的过期时间才行呢。
其实上面有两个问题,一个是过期时间不好设置,二是其他的客户端需要时不时过来看看锁是否释放掉了,这就是基于数据库和redis实现分布式锁存在的问题。
故这里我决定采用zookeeper规避掉这些问题。
zookeeper如此强大吗,对是的,我说的,怎么实现,临时顺序节点,事件监听回调函数处理。
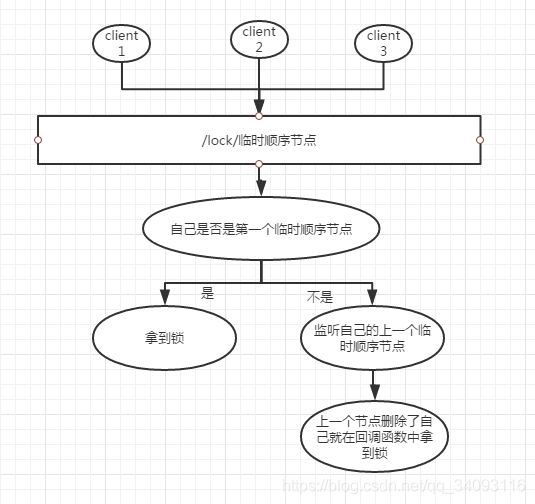
一,不用设置过期时间,zookeeper有心跳机制进行检测节点状态,模式是2秒检查一次可以设置,如果节点挂掉了,它所对应的临时节点会被删除,那么它的下一个节点会进入到自己的回调函数当中去。
二,没有拿到锁的client,不用去轮训看看可不可以拿到锁,采用事件监听,每一个client只需要监听自己的上一位就可以了,就像银行加号一样,你是8号,那么只要关注7号有没有完事儿就行。
总结:
基本上,关于redis缓存,为什么用,有哪些问题都说明白了,其实不难发现,缓存雪崩和缓存击穿其实本质就是缓存穿透,只不过是特殊情况下发生的缓存穿透。就是绕过了缓存直接访问数据库,导致数据库顶不住的问题。好了,该博客,写于世界疫情的当前,希望疫情早日结束,A股也早日重回3000点,各位程序员同胞们都能有一份好的工作,莫道浮云终蔽日,严冬过尽春蓓蕾。