c#扩展出MapReduce方法
MapReduce方法主体:


1 public static IDictionary<TKey, TResult> MapReduce<TInput, TKey, TValue, TResult>(this IList<TInput> inputList, 2 Func<MapReduceData<TInput>, KeyValueClass<TKey, TValue>> map, Func<TKey, IList<TValue>, TResult> reduce) 3 { 4 object locker = new object(); 5 ConcurrentDictionary<TKey, TResult> result = new ConcurrentDictionary<TKey, TResult>(); 6 //保存map出来的结果 7 ConcurrentDictionary<TKey, IList<TValue>> mapDic = new ConcurrentDictionary<TKey, IList<TValue>>(); 8 var parallelOptions = new ParallelOptions(); 9 parallelOptions.MaxDegreeOfParallelism = Environment.ProcessorCount; 10 //并行map 11 Parallel.For(0, inputList.Count(), parallelOptions, t => 12 { 13 MapReduceData<TInput> data = new MapReduceData<TInput> 14 { 15 Data = inputList[t], 16 Index = t, 17 List = inputList, 18 }; 19 var pair = map(data); 20 if (pair != null && pair.Valid) 21 { 22 //锁住防止并发操作list造成数据缺失 23 lock (locker) 24 { 25 //将匹配出来的结果加入结果集放入字典 26 IList<TValue> list = null; 27 if (mapDic.ContainsKey(pair.Key)) 28 { 29 list = mapDic[pair.Key]; 30 } 31 else 32 { 33 list = new List<TValue>(); 34 mapDic[pair.Key] = list; 35 } 36 list.Add(pair.Value); 37 } 38 } 39 }); 40 41 //并行reduce 42 Parallel.For(0, mapDic.Keys.Count, parallelOptions, t => 43 { 44 KeyValuePair<TKey, IList<TValue>> pair = mapDic.ElementAt(t); 45 result[pair.Key] = reduce(pair.Key, pair.Value); 46 }); 47 return result; 48 }
KeyValueClass定义:
1 public class KeyValueClass<K, V> 2 { 3 public KeyValueClass(K key, V value) 4 { 5 Key = key; 6 Value = value; 7 } 8 9 public KeyValueClass() 10 { 11 12 } 13 14 public K Key { get; set; } 15 16 public V Value { get; set; } 17 }
Console测试:
1 List<TestClass> listTestClass = new List<TestClass>(); 2 listTestClass.Add(new TestClass { a = "a", g = 1 }); 3 listTestClass.Add(new TestClass { a = "b", g = 3 }); 4 listTestClass.Add(new TestClass { a = "c", g = 4 }); 5 listTestClass.Add(new TestClass { a = "d", g = 2 }); 6 listTestClass.Add(new TestClass { a = "e", g = 1 }); 7 listTestClass.Add(new TestClass { a = "f", g = 2 }); 8 listTestClass.Add(new TestClass { a = "g", g = 5 }); 9 listTestClass.Add(new TestClass { a = "h", g = 6 }); 10 IDictionary<int, string> dic = listTestClass.MapReduce(t => 11 { 12 if (t.g < 5) 13 { 14 return new KeyValueClass<int, string>(t.g, t.a); 15 } 16 return null; 17 }, (key, values) => 18 { 19 return string.Join(",", values); 20 });
TestClass定义:
1 public class TestClass 2 { 3 public string a { get; set; } 4 public string b { get; set; } 5 6 public string d { get; set; } 7 8 //public DateTime f { get; set; } 9 10 public int g { get; set; } 11 12 public List<TestClass> test { get; set; } 13 14 public Dictionary<string, string> dic { get; set; } 15 }
结果:
1:a,e
2:d,f
3:b
4:c
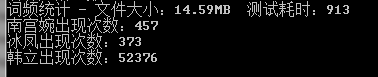
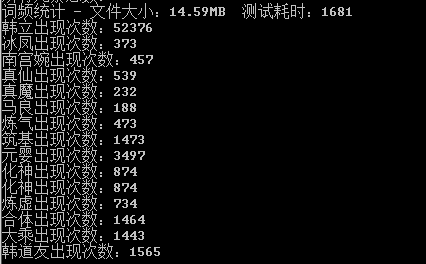
词频性能测试